Diffusion for World Modeling: Visual Details Matter in Atari
2405.12399
0
0
🌀
Abstract
World models constitute a promising approach for training reinforcement learning agents in a safe and sample-efficient manner. Recent world models predominantly operate on sequences of discrete latent variables to model environment dynamics. However, this compression into a compact discrete representation may ignore visual details that are important for reinforcement learning. Concurrently, diffusion models have become a dominant approach for image generation, challenging well-established methods modeling discrete latents. Motivated by this paradigm shift, we introduce DIAMOND (DIffusion As a Model Of eNvironment Dreams), a reinforcement learning agent trained in a diffusion world model. We analyze the key design choices that are required to make diffusion suitable for world modeling, and demonstrate how improved visual details can lead to improved agent performance. DIAMOND achieves a mean human normalized score of 1.46 on the competitive Atari 100k benchmark; a new best for agents trained entirely within a world model. To foster future research on diffusion for world modeling, we release our code, agents and playable world models at https://github.com/eloialonso/diamond.
Create account to get full access
Overview
- Introduces a reinforcement learning agent called DIAMOND that uses a diffusion world model
- Diffusion models are a newer approach for image generation, challenging methods using discrete latent variables
- DIAMOND achieves state-of-the-art performance on the Atari 100k benchmark by leveraging the visual details preserved in diffusion models
Plain English Explanation
Reinforcement learning is a powerful approach for training AI agents to complete tasks, but it can be challenging because the agents need to extensively explore their environment to learn. World models are a way to address this by having the agent first learn an internal model of the environment, which can then be used to train the agent more efficiently.
Previous world models have predominantly used sequences of discrete latent variables to represent the environment. However, this compressed representation may lose important visual details that could be useful for the reinforcement learning agent. DIAMOND takes a different approach by using a diffusion model, a newer type of generative AI model that is particularly good at preserving visual details.
The key insight of DIAMOND is that by using a diffusion model as the world model, the reinforcement learning agent can leverage this rich visual information to learn more effectively. The authors analyze the design choices needed to make diffusion models suitable for world modeling, and show that the improved visual details lead to better performance on the challenging Atari 100k benchmark, setting a new state-of-the-art for agents trained entirely within a world model.
Technical Explanation
The paper introduces DIAMOND (DIffusion As a Model Of eNvironment Dreams), a reinforcement learning agent that uses a diffusion world model rather than the more common discrete latent variable approach.
Diffusion models are a type of generative AI model that have recently been very successful at generating high-quality images. Unlike previous world models that compress the environment into a compact discrete representation, diffusion models preserve much richer visual details. The authors analyze the key design choices required to make diffusion models suitable for world modeling, such as using a conditional diffusion model to predict the next frame given the current state.
The DIAMOND agent is trained end-to-end, with the diffusion world model and the reinforcement learning policy trained jointly. The authors demonstrate that this approach leads to state-of-the-art performance on the Atari 100k benchmark, where DIAMOND achieves a mean human normalized score of 1.46 - the best result so far for agents trained entirely within a world model.
To support future research in this area, the authors release their code, agents, and playable world models on GitHub.
Critical Analysis
The paper presents a compelling approach by leveraging the visual detail preservation of diffusion models for world modeling in reinforcement learning. The authors carefully address the key design choices required to make diffusion models suitable for this task, such as using a conditional diffusion model.
One potential limitation mentioned in the paper is that diffusion models can be computationally expensive, which could make them less practical for some real-world applications. The authors note that further research is needed to address this issue.
Additionally, while the Atari 100k benchmark is a well-established test for reinforcement learning agents, it would be interesting to see how DIAMOND performs on a wider range of tasks and environments. Expanding the evaluation to more diverse scenarios could provide additional insights into the strengths and weaknesses of the approach.
Overall, the DIAMOND method represents an exciting advancement in the use of world models for reinforcement learning, and the authors' release of the code and models will likely spur further research in this promising direction. Readers are encouraged to critically examine the paper's claims and consider how this work might be extended or applied in their own areas of interest.
Conclusion
The DIAMOND method introduced in this paper represents a significant advancement in the use of world models for training reinforcement learning agents. By leveraging the visual detail preservation of diffusion models, the authors have shown that agents can learn more effectively and achieve state-of-the-art performance on the Atari 100k benchmark.
This work highlights the importance of exploring alternative approaches to world modeling beyond the traditional discrete latent variable methods. As the field of AI continues to evolve, innovative techniques like diffusion models will likely play an increasingly important role in pushing the boundaries of what is possible with reinforcement learning.
The open-source release of the DIAMOND code, agents, and models will undoubtedly spur further research and experimentation in this area, ultimately leading to more robust and capable reinforcement learning systems. As the technology progresses, it will be exciting to see how these advancements can be applied to solve real-world problems and create new possibilities for AI-driven applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Learning from Random Demonstrations: Offline Reinforcement Learning with Importance-Sampled Diffusion Models
Zeyu Fang, Tian Lan
0
0
Generative models such as diffusion have been employed as world models in offline reinforcement learning to generate synthetic data for more effective learning. Existing work either generates diffusion models one-time prior to training or requires additional interaction data to update it. In this paper, we propose a novel approach for offline reinforcement learning with closed-loop policy evaluation and world-model adaptation. It iteratively leverages a guided diffusion world model to directly evaluate the offline target policy with actions drawn from it, and then performs an importance-sampled world model update to adaptively align the world model with the updated policy. We analyzed the performance of the proposed method and provided an upper bound on the return gap between our method and the real environment under an optimal policy. The result sheds light on various factors affecting learning performance. Evaluations in the D4RL environment show significant improvement over state-of-the-art baselines, especially when only random or medium-expertise demonstrations are available -- thus requiring improved alignment between the world model and offline policy evaluation.
5/31/2024

Diffusion World Model: Future Modeling Beyond Step-by-Step Rollout for Offline Reinforcement Learning
Zihan Ding, Amy Zhang, Yuandong Tian, Qinqing Zheng
0
0
We introduce Diffusion World Model (DWM), a conditional diffusion model capable of predicting multistep future states and rewards concurrently. As opposed to traditional one-step dynamics models, DWM offers long-horizon predictions in a single forward pass, eliminating the need for recursive queries. We integrate DWM into model-based value estimation, where the short-term return is simulated by future trajectories sampled from DWM. In the context of offline reinforcement learning, DWM can be viewed as a conservative value regularization through generative modeling. Alternatively, it can be seen as a data source that enables offline Q-learning with synthetic data. Our experiments on the D4RL dataset confirm the robustness of DWM to long-horizon simulation. In terms of absolute performance, DWM significantly surpasses one-step dynamics models with a $44%$ performance gain, and is comparable to or slightly surpassing their model-free counterparts.
6/18/2024
Learning to Play Atari in a World of Tokens
Pranav Agarwal, Sheldon Andrews, Samira Ebrahimi Kahou
0
0
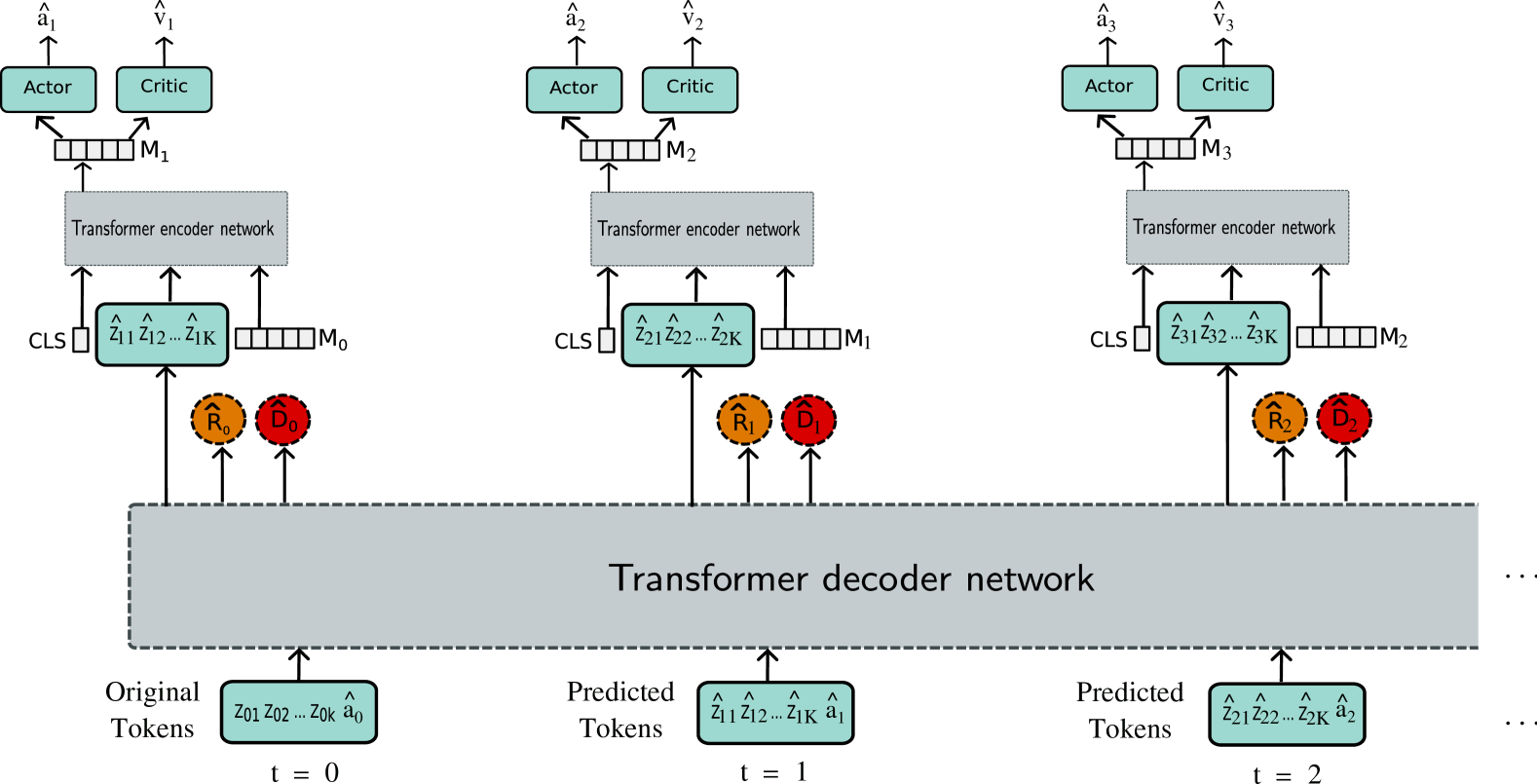
Model-based reinforcement learning agents utilizing transformers have shown improved sample efficiency due to their ability to model extended context, resulting in more accurate world models. However, for complex reasoning and planning tasks, these methods primarily rely on continuous representations. This complicates modeling of discrete properties of the real world such as disjoint object classes between which interpolation is not plausible. In this work, we introduce discrete abstract representations for transformer-based learning (DART), a sample-efficient method utilizing discrete representations for modeling both the world and learning behavior. We incorporate a transformer-decoder for auto-regressive world modeling and a transformer-encoder for learning behavior by attending to task-relevant cues in the discrete representation of the world model. For handling partial observability, we aggregate information from past time steps as memory tokens. DART outperforms previous state-of-the-art methods that do not use look-ahead search on the Atari 100k sample efficiency benchmark with a median human-normalized score of 0.790 and beats humans in 9 out of 26 games. We release our code at https://pranaval.github.io/DART/.
6/4/2024

Efficient World Models with Context-Aware Tokenization
Vincent Micheli, Eloi Alonso, Franc{c}ois Fleuret
0
0
Scaling up deep Reinforcement Learning (RL) methods presents a significant challenge. Following developments in generative modelling, model-based RL positions itself as a strong contender. Recent advances in sequence modelling have led to effective transformer-based world models, albeit at the price of heavy computations due to the long sequences of tokens required to accurately simulate environments. In this work, we propose $Delta$-IRIS, a new agent with a world model architecture composed of a discrete autoencoder that encodes stochastic deltas between time steps and an autoregressive transformer that predicts future deltas by summarizing the current state of the world with continuous tokens. In the Crafter benchmark, $Delta$-IRIS sets a new state of the art at multiple frame budgets, while being an order of magnitude faster to train than previous attention-based approaches. We release our code and models at https://github.com/vmicheli/delta-iris.
6/28/2024