Learning from Random Demonstrations: Offline Reinforcement Learning with Importance-Sampled Diffusion Models
2405.19878
0
0
Abstract
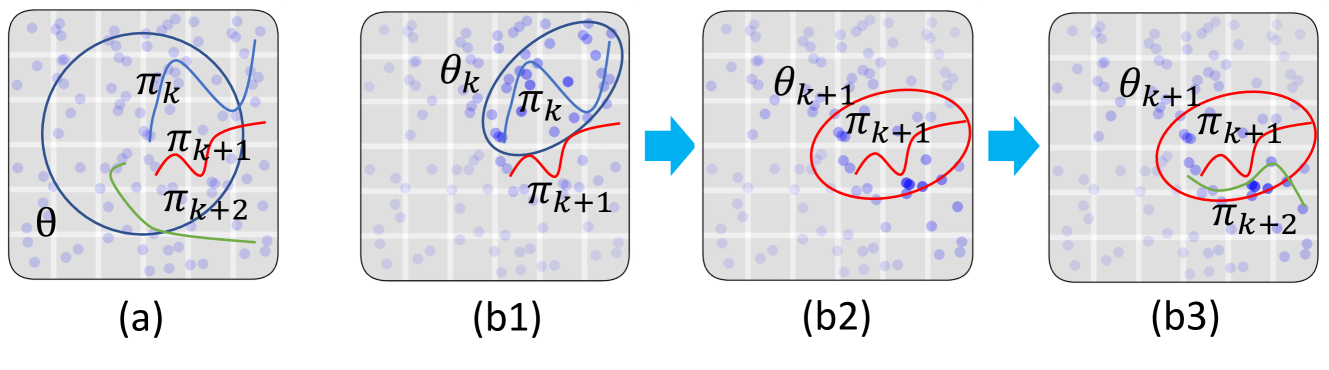
Generative models such as diffusion have been employed as world models in offline reinforcement learning to generate synthetic data for more effective learning. Existing work either generates diffusion models one-time prior to training or requires additional interaction data to update it. In this paper, we propose a novel approach for offline reinforcement learning with closed-loop policy evaluation and world-model adaptation. It iteratively leverages a guided diffusion world model to directly evaluate the offline target policy with actions drawn from it, and then performs an importance-sampled world model update to adaptively align the world model with the updated policy. We analyzed the performance of the proposed method and provided an upper bound on the return gap between our method and the real environment under an optimal policy. The result sheds light on various factors affecting learning performance. Evaluations in the D4RL environment show significant improvement over state-of-the-art baselines, especially when only random or medium-expertise demonstrations are available -- thus requiring improved alignment between the world model and offline policy evaluation.
Create account to get full access
Overview
- This paper introduces a novel offline reinforcement learning (RL) method called Importance-Sampled Diffusion Models (ISDM) that can learn effective policies from random, unlabeled demonstrations.
- The approach leverages diffusion models, a type of generative model, to learn a dynamics model from the demonstration data, which is then used to guide the policy optimization process.
- ISDM outperforms existing offline RL methods on a range of continuous control tasks, demonstrating the benefits of using diffusion-based dynamics models for offline RL.
Plain English Explanation
This research paper proposes a new way to teach an AI system how to perform tasks without giving it direct instructions or "rewards" for good behavior. Instead, the system learns by observing random examples of people or other agents performing the task, even if those examples are not perfect.
The key insight is to use a special type of machine learning model called a "diffusion model" to learn the underlying dynamics of the task from the random examples. Diffusion models are good at capturing the complex patterns and relationships in data, allowing the system to build an understanding of how the task should be performed.
Once the diffusion model has learned the dynamics, the researchers use an "importance sampling" technique to guide the policy optimization process. This helps the system focus on the most relevant and informative parts of the random demonstrations, allowing it to learn an effective policy for completing the task.
The paper shows that this Importance-Sampled Diffusion Models (ISDM) approach outperforms other state-of-the-art offline reinforcement learning methods on a variety of continuous control tasks. This suggests that the use of diffusion-based dynamics models can be a powerful way to learn from imperfect, unlabeled data in the absence of direct rewards or feedback.
Technical Explanation
The authors propose a novel offline reinforcement learning (RL) algorithm called Importance-Sampled Diffusion Models (ISDM) that leverages diffusion models to learn effective policies from random, unlabeled demonstration data.
The core idea is to use a diffusion model to learn the underlying dynamics of the task from the demonstration data, which is then used to guide the policy optimization process. Specifically, the diffusion model is trained to predict the next state given the current state and action, capturing the complex patterns and relationships in the data.
During policy optimization, ISDM uses an importance sampling technique to focus the policy updates on the most informative parts of the demonstration data. This helps the policy quickly learn the most relevant behaviors, rather than getting distracted by irrelevant or noisy demonstrations.
The authors evaluate ISDM on a range of continuous control tasks and show that it outperforms existing offline RL methods, such as Policy-Guided Diffusion, Preferred Action Optimized Diffusion Policies, Efficient Imitation Learning with Conservative World Models, and Continual Offline Reinforcement Learning via Diffusion-Based Dynamics Models. This demonstrates the benefits of using diffusion-based dynamics models for offline RL, where direct rewards or feedback may not be available.
Critical Analysis
The paper presents a compelling approach to offline RL that leverages the power of diffusion models to learn effective policies from random, unlabeled demonstrations. The importance sampling technique used to guide the policy optimization process is a clever way to focus the learning on the most relevant parts of the data.
However, the paper does not address some potential limitations of the ISDM approach. For example, the reliance on a pre-trained diffusion model could make the method sensitive to the quality and coverage of the demonstration data, as well as the hyperparameters used to train the diffusion model. Additionally, the paper does not explore the scalability of ISDM to more complex, high-dimensional tasks or environments with sparse rewards.
Further research could investigate ways to make the ISDM approach more robust and adaptable, such as by incorporating techniques for learning diffusion-based dynamics models in an end-to-end fashion or exploring ways to combine ISDM with other offline RL methods. Nonetheless, the core ideas presented in this paper represent an important contribution to the field of offline RL and could inspire further advancements in this area.
Conclusion
The "Learning from Random Demonstrations" paper introduces a novel offline reinforcement learning method called Importance-Sampled Diffusion Models (ISDM) that can effectively learn policies from random, unlabeled demonstration data. By leveraging diffusion models to capture the underlying dynamics of the task, ISDM is able to outperform other state-of-the-art offline RL approaches on a variety of continuous control tasks.
This research demonstrates the potential of diffusion-based dynamics models for offline RL, where direct rewards or feedback may not be available. While the approach has some limitations that warrant further investigation, the core ideas presented in this paper represent an important advance in the field and could pave the way for more robust and adaptable offline RL methods in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Policy-Guided Diffusion
Matthew Thomas Jackson, Michael Tryfan Matthews, Cong Lu, Benjamin Ellis, Shimon Whiteson, Jakob Foerster
0
0
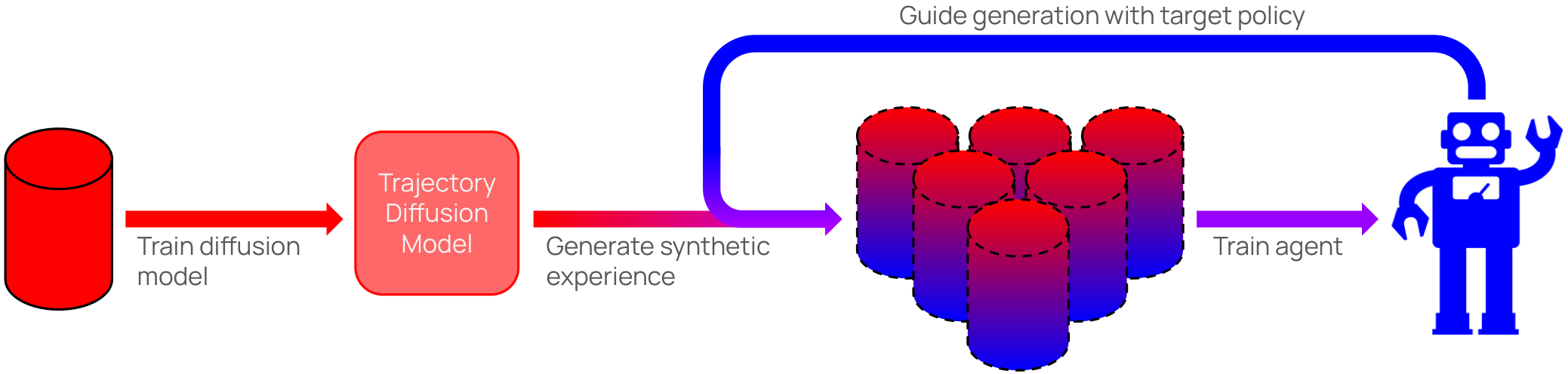
In many real-world settings, agents must learn from an offline dataset gathered by some prior behavior policy. Such a setting naturally leads to distribution shift between the behavior policy and the target policy being trained - requiring policy conservatism to avoid instability and overestimation bias. Autoregressive world models offer a different solution to this by generating synthetic, on-policy experience. However, in practice, model rollouts must be severely truncated to avoid compounding error. As an alternative, we propose policy-guided diffusion. Our method uses diffusion models to generate entire trajectories under the behavior distribution, applying guidance from the target policy to move synthetic experience further on-policy. We show that policy-guided diffusion models a regularized form of the target distribution that balances action likelihood under both the target and behavior policies, leading to plausible trajectories with high target policy probability, while retaining a lower dynamics error than an offline world model baseline. Using synthetic experience from policy-guided diffusion as a drop-in substitute for real data, we demonstrate significant improvements in performance across a range of standard offline reinforcement learning algorithms and environments. Our approach provides an effective alternative to autoregressive offline world models, opening the door to the controllable generation of synthetic training data.
4/10/2024

Diffusion World Model: Future Modeling Beyond Step-by-Step Rollout for Offline Reinforcement Learning
Zihan Ding, Amy Zhang, Yuandong Tian, Qinqing Zheng
0
0
We introduce Diffusion World Model (DWM), a conditional diffusion model capable of predicting multistep future states and rewards concurrently. As opposed to traditional one-step dynamics models, DWM offers long-horizon predictions in a single forward pass, eliminating the need for recursive queries. We integrate DWM into model-based value estimation, where the short-term return is simulated by future trajectories sampled from DWM. In the context of offline reinforcement learning, DWM can be viewed as a conservative value regularization through generative modeling. Alternatively, it can be seen as a data source that enables offline Q-learning with synthetic data. Our experiments on the D4RL dataset confirm the robustness of DWM to long-horizon simulation. In terms of absolute performance, DWM significantly surpasses one-step dynamics models with a $44%$ performance gain, and is comparable to or slightly surpassing their model-free counterparts.
6/18/2024
🏅
Model-Based Reinforcement Learning with Multi-Task Offline Pretraining
Minting Pan, Yitao Zheng, Yunbo Wang, Xiaokang Yang
0
0
Pretraining reinforcement learning (RL) models on offline datasets is a promising way to improve their training efficiency in online tasks, but challenging due to the inherent mismatch in dynamics and behaviors across various tasks. We present a model-based RL method that learns to transfer potentially useful dynamics and action demonstrations from offline data to a novel task. The main idea is to use the world models not only as simulators for behavior learning but also as tools to measure the task relevance for both dynamics representation transfer and policy transfer. We build a time-varying, domain-selective distillation loss to generate a set of offline-to-online similarity weights. These weights serve two purposes: (i) adaptively transferring the task-agnostic knowledge of physical dynamics to facilitate world model training, and (ii) learning to replay relevant source actions to guide the target policy. We demonstrate the advantages of our approach compared with the state-of-the-art methods in Meta-World and DeepMind Control Suite.
6/6/2024
Preferred-Action-Optimized Diffusion Policies for Offline Reinforcement Learning
Tianle Zhang, Jiayi Guan, Lin Zhao, Yihang Li, Dongjiang Li, Zecui Zeng, Lei Sun, Yue Chen, Xuelong Wei, Lusong Li, Xiaodong He
0
0
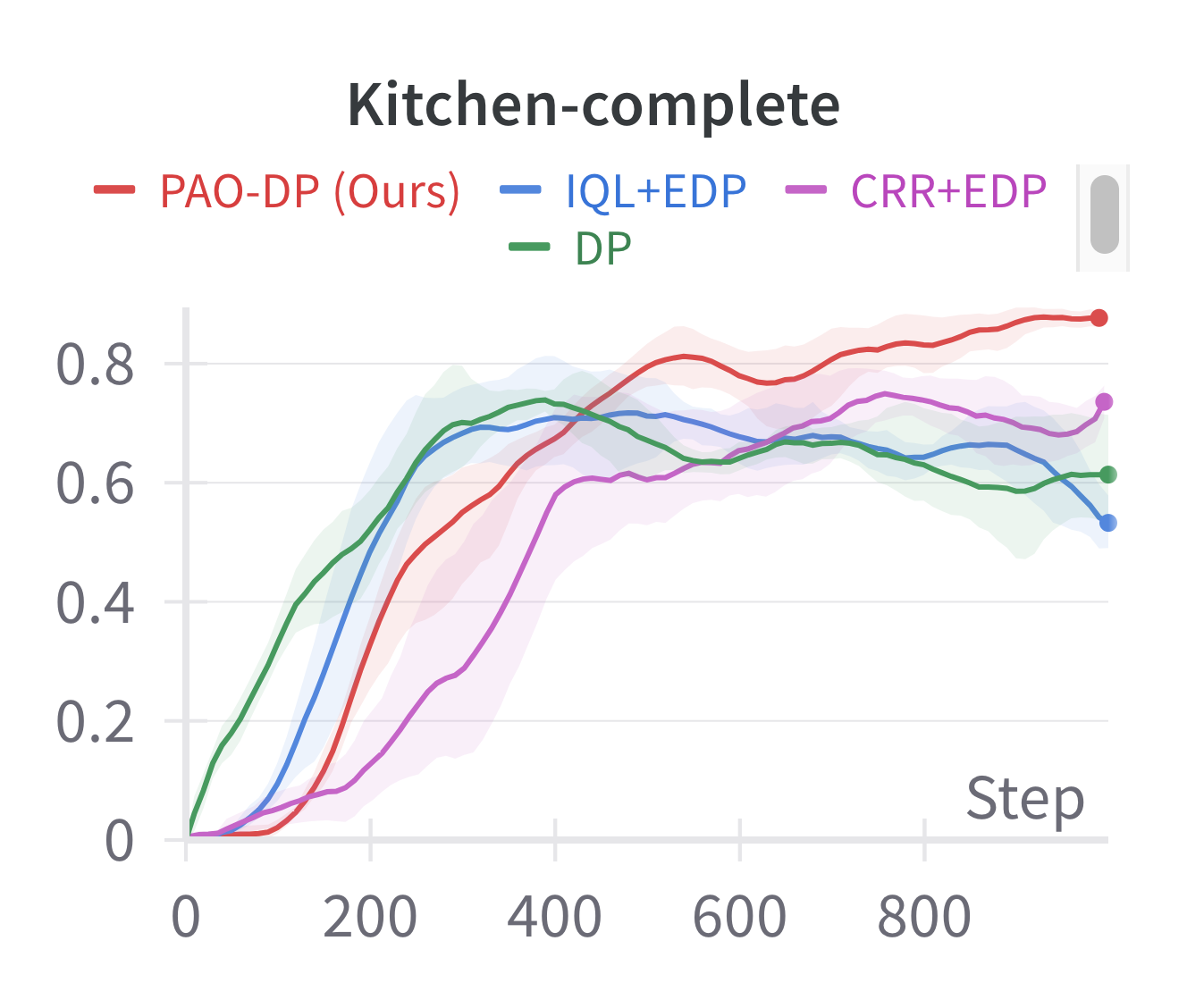
Offline reinforcement learning (RL) aims to learn optimal policies from previously collected datasets. Recently, due to their powerful representational capabilities, diffusion models have shown significant potential as policy models for offline RL issues. However, previous offline RL algorithms based on diffusion policies generally adopt weighted regression to improve the policy. This approach optimizes the policy only using the collected actions and is sensitive to Q-values, which limits the potential for further performance enhancement. To this end, we propose a novel preferred-action-optimized diffusion policy for offline RL. In particular, an expressive conditional diffusion model is utilized to represent the diverse distribution of a behavior policy. Meanwhile, based on the diffusion model, preferred actions within the same behavior distribution are automatically generated through the critic function. Moreover, an anti-noise preference optimization is designed to achieve policy improvement by using the preferred actions, which can adapt to noise-preferred actions for stable training. Extensive experiments demonstrate that the proposed method provides competitive or superior performance compared to previous state-of-the-art offline RL methods, particularly in sparse reward tasks such as Kitchen and AntMaze. Additionally, we empirically prove the effectiveness of anti-noise preference optimization.
5/30/2024