DiLoCo: Distributed Low-Communication Training of Language Models

32
🏋️
Sign in to get full access
Overview
- Large language models (LLMs) are critical components in many machine learning applications.
- Standard LLM training approaches require many interconnected accelerators that exchange gradients and intermediate states at each optimization step.
- Building and maintaining a single computing cluster with many accelerators can be challenging.
- This paper proposes a distributed optimization algorithm, Distributed Low-Communication (DiLoCo), to enable LLM training on poorly connected computing clusters.
Plain English Explanation
DiLoCo: A Distributed Approach to Training Large Language Models
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. They are used in a wide range of applications, from virtual assistants to language translation. However, training these models typically requires a lot of computing power and communication between the devices used for the training.
Normally, LLM training is done on a single powerful computing cluster with many interconnected accelerators, such as GPUs or TPUs. These accelerators constantly exchange information, like gradients and intermediate states, as the model is being trained. While this approach can be effective, it can also be challenging to build and maintain such a large and complex computing system.
This paper proposes a different approach, called Distributed Low-Communication (DiLoCo), that allows LLM training to be done across multiple, smaller computing clusters that are not as well-connected. The key idea is to reduce the amount of communication required between the clusters during training, making the process more efficient and easier to implement.
The DiLoCo approach is based on a technique called federated averaging, where the model is trained independently on each cluster for a number of steps, and then the model updates are combined in a specific way. This allows the training to proceed with much less communication between the clusters, while still achieving good performance on the C4 dataset, a common benchmark for language models.
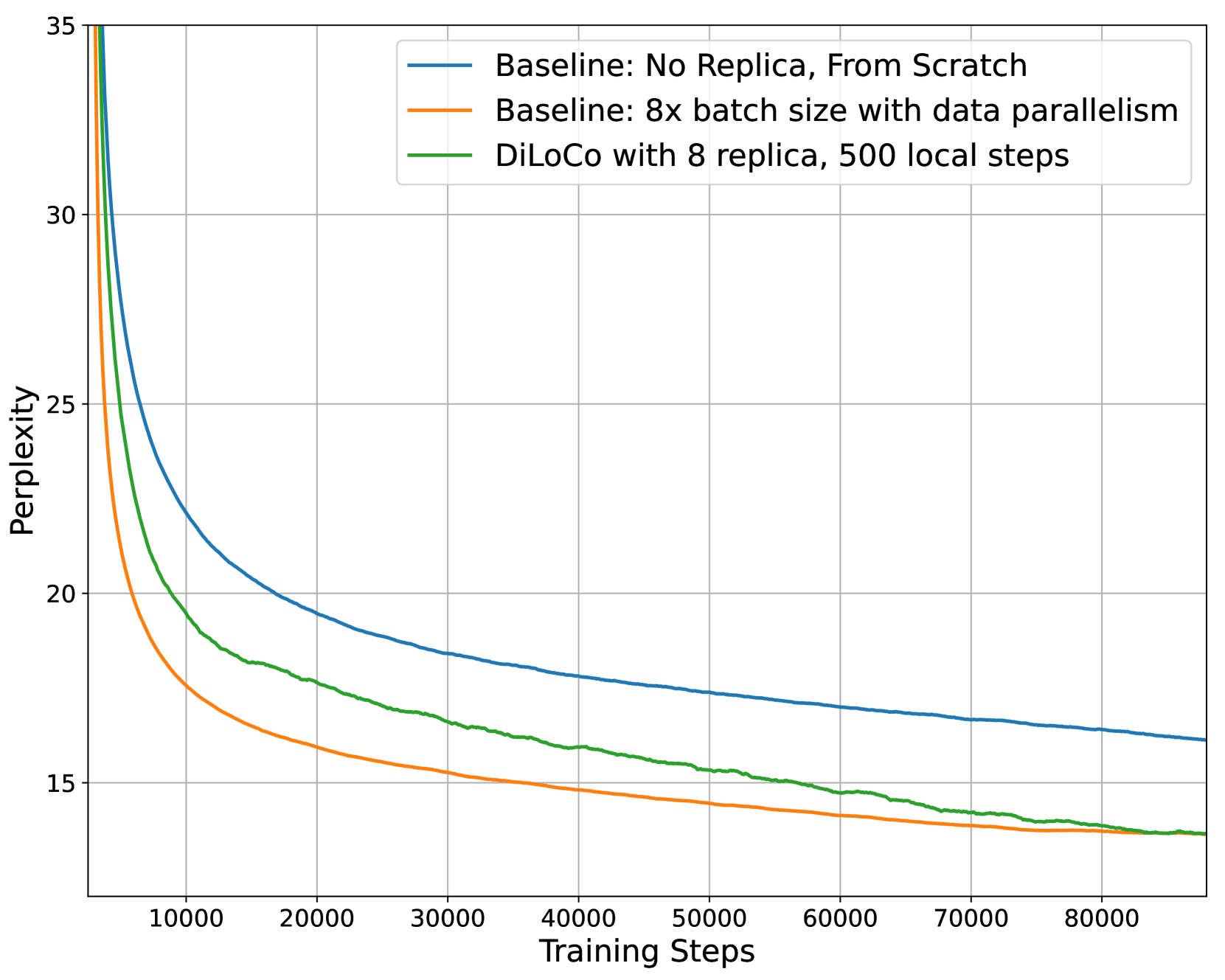
The paper shows that DiLoCo can match the performance of the standard, fully synchronized training approach while communicating 500 times less. This makes it a promising technique for training LLMs in a more distributed and scalable way, especially when the available computing resources are spread across multiple locations.
Technical Explanation
DiLoCo: A Distributed Approach to Training Large Language Models
The key elements of the DiLoCo approach are:
-
Distributed Training: DiLoCo enables training of language models on "islands" of devices (e.g., computing clusters) that are poorly connected, rather than requiring a single, tightly interconnected cluster.
-
Federated Averaging: DiLoCo is a variant of the federated averaging algorithm, where the model is trained independently on each cluster for a large number of steps, and the model updates are then combined in a specific way.
-
Inner and Outer Optimization: The inner optimization on each cluster uses the AdamW algorithm, while the outer optimization that combines the updates uses Nesterov momentum.
-
Reduced Communication: On the C4 dataset, DiLoCo achieves performance comparable to fully synchronous optimization while communicating 500 times less.
-
Robustness: DiLoCo exhibits great robustness to the data distribution on each worker, as well as to changes in resource availability during training.
The paper presents experiments comparing DiLoCo to the standard synchronous training approach, demonstrating its effectiveness in training language models on distributed computing resources with limited connectivity.
Critical Analysis
The paper presents a promising approach to training large language models in a distributed and scalable manner. The key strengths of the DiLoCo algorithm are its ability to achieve high performance with greatly reduced communication between computing clusters, as well as its robustness to variations in data distribution and resource availability.
However, the paper does not address several important considerations:
-
Convergence and Stability: While the paper shows that DiLoCo can match the performance of synchronous training, it does not provide a theoretical analysis of the convergence properties and stability of the algorithm. This is an important area for further research.
-
Practical Deployment: The paper focuses on the algorithmic aspects of DiLoCo, but does not discuss the practical challenges of deploying such a system in real-world scenarios, such as fault tolerance, load balancing, and monitoring.
-
Generalization to Other Domains: The evaluation is limited to the C4 dataset for language modeling. It would be valuable to understand how DiLoCo performs on other types of machine learning tasks and datasets.
-
Comparison to Other Distributed Approaches: The paper could benefit from a more thorough comparison to other distributed optimization algorithms, such as those based on hierarchical parallelism or asynchronous updates.
Overall, the DiLoCo approach is an interesting and potentially impactful contribution to the field of distributed machine learning. However, the practical deployment and generalization of the method require further investigation and research.
Conclusion
This paper presents a novel distributed optimization algorithm, DiLoCo, that enables the training of large language models on computing clusters with limited connectivity. The key idea is to reduce the amount of communication required between clusters during the training process, while still maintaining high performance.
The results show that DiLoCo can match the performance of the standard synchronous training approach on the C4 dataset, while communicating 500 times less. This makes it a promising technique for training large language models in a more scalable and distributed manner, especially when the available computing resources are spread across multiple locations.
While the paper highlights the strengths of the DiLoCo approach, it also identifies areas for further research, such as the theoretical convergence properties, practical deployment challenges, and generalization to other domains. Addressing these concerns could further strengthen the impact and applicability of this distributed machine learning technique.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
32
New!DiLoCo: Distributed Low-Communication Training of Language Models
Arthur Douillard, Qixuan Feng, Andrei A. Rusu, Rachita Chhaparia, Yani Donchev, Adhiguna Kuncoro, Marc'Aurelio Ranzato, Arthur Szlam, Jiajun Shen
Large language models (LLM) have become a critical component in many applications of machine learning. However, standard approaches to training LLM require a large number of tightly interconnected accelerators, with devices exchanging gradients and other intermediate states at each optimization step. While it is difficult to build and maintain a single computing cluster hosting many accelerators, it might be easier to find several computing clusters each hosting a smaller number of devices. In this work, we propose a distributed optimization algorithm, Distributed Low-Communication (DiLoCo), that enables training of language models on islands of devices that are poorly connected. The approach is a variant of federated averaging, where the number of inner steps is large, the inner optimizer is AdamW, and the outer optimizer is Nesterov momentum. On the widely used C4 dataset, we show that DiLoCo on 8 workers performs as well as fully synchronous optimization while communicating 500 times less. DiLoCo exhibits great robustness to the data distribution of each worker. It is also robust to resources becoming unavailable over time, and vice versa, it can seamlessly leverage resources that become available during training.
Read more9/24/2024
28
OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training
Sami Jaghouar, Jack Min Ong, Johannes Hagemann
OpenDiLoCo is an open-source implementation and replication of the Distributed Low-Communication (DiLoCo) training method for large language models. We provide a reproducible implementation of the DiLoCo experiments, offering it within a scalable, decentralized training framework using the Hivemind library. We demonstrate its effectiveness by training a model across two continents and three countries, while maintaining 90-95% compute utilization. Additionally, we conduct ablations studies focusing on the algorithm's compute efficiency, scalability in the number of workers and show that its gradients can be all-reduced using FP16 without any performance degradation. Furthermore, we scale OpenDiLoCo to 3x the size of the original work, demonstrating its effectiveness for billion parameter models.
Read more7/11/2024
📈
0
LoCo: Low-Bit Communication Adaptor for Large-scale Model Training
Xingyu Xie, Zhijie Lin, Kim-Chuan Toh, Pan Zhou
To efficiently train large-scale models, low-bit gradient communication compresses full-precision gradients on local GPU nodes into low-precision ones for higher gradient synchronization efficiency among GPU nodes. However, it often degrades training quality due to compression information loss. To address this, we propose the Low-bit Communication Adaptor (LoCo), which compensates gradients on local GPU nodes before compression, ensuring efficient synchronization without compromising training quality. Specifically, LoCo designs a moving average of historical compensation errors to stably estimate concurrent compression error and then adopts it to compensate for the concurrent gradient compression, yielding a less lossless compression. This mechanism allows it to be compatible with general optimizers like Adam and sharding strategies like FSDP. Theoretical analysis shows that integrating LoCo into full-precision optimizers like Adam and SGD does not impair their convergence speed on nonconvex problems. Experimental results show that across large-scale model training frameworks like Megatron-LM and PyTorch's FSDP, LoCo significantly improves communication efficiency, e.g., improving Adam's training speed by 14% to 40% without performance degradation on large language models like LLAMAs and MoE.
Read more7/8/2024
🏋️
0
ACCO: Accumulate while you Communicate, Hiding Communications in Distributed LLM Training
Adel Nabli (MLIA, Mila), Louis Fournier (MLIA), Pierre Erbacher (MLIA), Louis Serrano (MLIA), Eugene Belilovsky (Mila), Edouard Oyallon
Training Large Language Models (LLMs) relies heavily on distributed implementations, employing multiple GPUs to compute stochastic gradients on model replicas in parallel. However, synchronizing gradients in data parallel settings induces a communication overhead increasing with the number of distributed workers, which can impede the efficiency gains of parallelization. To address this challenge, optimization algorithms reducing inter-worker communication have emerged, such as local optimization methods used in Federated Learning. While effective in minimizing communication overhead, these methods incur significant memory costs, hindering scalability: in addition to extra momentum variables, if communications are only allowed between multiple local optimization steps, then the optimizer's states cannot be sharded among workers. In response, we propose $textbf{AC}$cumulate while $textbf{CO}$mmunicate ($texttt{ACCO}$), a memory-efficient optimization algorithm tailored for distributed training of LLMs. $texttt{ACCO}$ allows to shard optimizer states across workers, overlaps gradient computations and communications to conceal communication costs, and accommodates heterogeneous hardware. Our method relies on a novel technique to mitigate the one-step delay inherent in parallel execution of gradient computations and communications, eliminating the need for warmup steps and aligning with the training dynamics of standard distributed optimization while converging faster in terms of wall-clock time. We demonstrate the effectiveness of $texttt{ACCO}$ on several LLMs training and fine-tuning tasks.
Read more6/6/2024