DiM-Gesture: Co-Speech Gesture Generation with Adaptive Layer Normalization Mamba-2 framework

0
Sign in to get full access
Overview
- Co-speech gesture generation system called DiM-Gesture that uses adaptive layer normalization and the Mamba-2 framework
- Aims to generate natural and expressive gestures that are synchronized with speech
- Leverages fuzzy inference, diffusion models, and state-space models
Plain English Explanation
The DiM-Gesture system is designed to automatically generate natural-looking gestures that accompany speech. It uses a combination of techniques, including fuzzy inference, diffusion models, and state-space models.
The key innovation of DiM-Gesture is its use of adaptive layer normalization (AdaLN), which helps the system adapt to different speakers and their unique gestural styles. This allows the generated gestures to be more tailored to the individual.
The Mamba-2 framework provides the overall structure and coordination for the various components of the DiM-Gesture system. This helps ensure the gestures are well-synchronized with the speech and appear natural and cohesive.
Technical Explanation
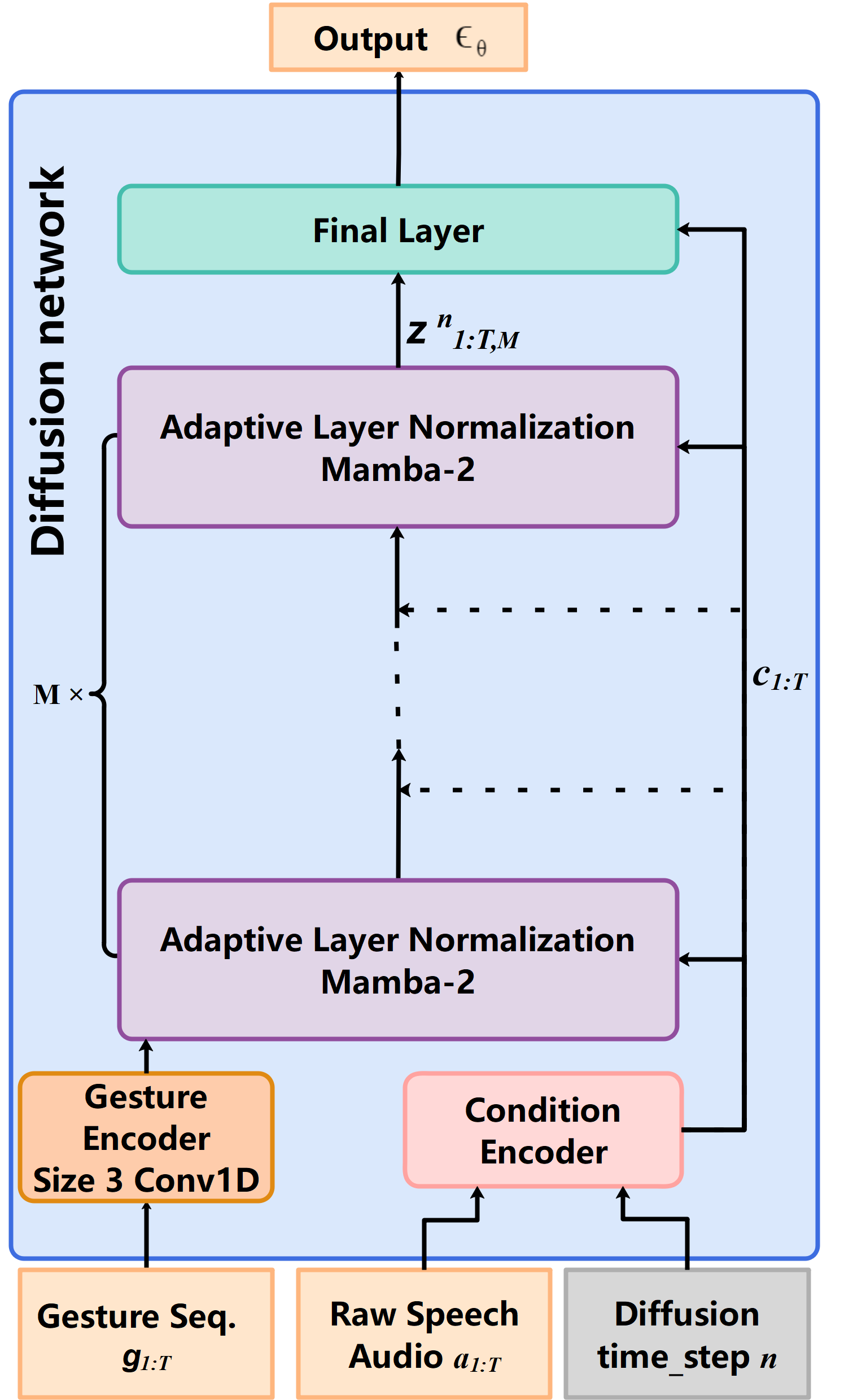
The DiM-Gesture system uses a multi-stage architecture to generate co-speech gestures. First, a fuzzy inference engine analyzes the speech input and extracts relevant features, such as prosody and semantics. These features are then used to condition a diffusion model that generates a sequence of 3D hand and arm poses.
To ensure the generated gestures are well-synchronized with the speech, DiM-Gesture employs a state-space model that models the temporal dynamics of the gesture sequence. This state-space model is trained alongside the diffusion model.
A key innovation in DiM-Gesture is the use of adaptive layer normalization (AdaLN) to make the system more adaptable to different speakers. AdaLN allows the normalization parameters to be dynamically adjusted based on the input speech, helping the system generate gestures that better match the speaker's individual style.
The overall system is implemented using the Mamba-2 framework, which provides a structured way to integrate the various components and ensure smooth coordination between the different stages of the gesture generation process.
Critical Analysis
The DiM-Gesture system presents a promising approach to co-speech gesture generation, with its use of adaptive normalization and the Mamba-2 framework as key innovations. However, the paper does not provide a thorough evaluation of the system's performance, with only limited quantitative and qualitative results reported.
Additionally, the paper does not address potential limitations or challenges of the approach, such as its ability to handle diverse speaking styles, its scalability to longer speech segments, or its robustness to noise or other real-world conditions. Further research and evaluation would be necessary to fully assess the system's capabilities and potential areas for improvement.
It would also be useful to see a more in-depth comparison of DiM-Gesture to other state-of-the-art co-speech gesture generation systems, to better understand its relative strengths and weaknesses.
Conclusion
The DiM-Gesture system represents an interesting step forward in the field of co-speech gesture generation, leveraging adaptive normalization and a structured framework to generate natural-looking and well-synchronized gestures. While the paper provides a high-level overview of the system, further research and evaluation would be needed to fully understand its capabilities and potential real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DiM-Gesture: Co-Speech Gesture Generation with Adaptive Layer Normalization Mamba-2 framework
Fan Zhang, Naye Ji, Fuxing Gao, Bozuo Zhao, Jingmei Wu, Yanbing Jiang, Hui Du, Zhenqing Ye, Jiayang Zhu, WeiFan Zhong, Leyao Yan, Xiaomeng Ma
Speech-driven gesture generation is an emerging domain within virtual human creation, where current methods predominantly utilize Transformer-based architectures that necessitate extensive memory and are characterized by slow inference speeds. In response to these limitations, we propose textit{DiM-Gestures}, a novel end-to-end generative model crafted to create highly personalized 3D full-body gestures solely from raw speech audio, employing Mamba-based architectures. This model integrates a Mamba-based fuzzy feature extractor with a non-autoregressive Adaptive Layer Normalization (AdaLN) Mamba-2 diffusion architecture. The extractor, leveraging a Mamba framework and a WavLM pre-trained model, autonomously derives implicit, continuous fuzzy features, which are then unified into a singular latent feature. This feature is processed by the AdaLN Mamba-2, which implements a uniform conditional mechanism across all tokens to robustly model the interplay between the fuzzy features and the resultant gesture sequence. This innovative approach guarantees high fidelity in gesture-speech synchronization while maintaining the naturalness of the gestures. Employing a diffusion model for training and inference, our framework has undergone extensive subjective and objective evaluations on the ZEGGS and BEAT datasets. These assessments substantiate our model's enhanced performance relative to contemporary state-of-the-art methods, demonstrating competitive outcomes with the DiTs architecture (Persona-Gestors) while optimizing memory usage and accelerating inference speed.
Read more8/2/2024

0
MambaGesture: Enhancing Co-Speech Gesture Generation with Mamba and Disentangled Multi-Modality Fusion
Chencan Fu, Yabiao Wang, Jiangning Zhang, Zhengkai Jiang, Xiaofeng Mao, Jiafu Wu, Weijian Cao, Chengjie Wang, Yanhao Ge, Yong Liu
Co-speech gesture generation is crucial for producing synchronized and realistic human gestures that accompany speech, enhancing the animation of lifelike avatars in virtual environments. While diffusion models have shown impressive capabilities, current approaches often overlook a wide range of modalities and their interactions, resulting in less dynamic and contextually varied gestures. To address these challenges, we present MambaGesture, a novel framework integrating a Mamba-based attention block, MambaAttn, with a multi-modality feature fusion module, SEAD. The MambaAttn block combines the sequential data processing strengths of the Mamba model with the contextual richness of attention mechanisms, enhancing the temporal coherence of generated gestures. SEAD adeptly fuses audio, text, style, and emotion modalities, employing disentanglement to deepen the fusion process and yield gestures with greater realism and diversity. Our approach, rigorously evaluated on the multi-modal BEAT dataset, demonstrates significant improvements in Fr'echet Gesture Distance (FGD), diversity scores, and beat alignment, achieving state-of-the-art performance in co-speech gesture generation. Project website: $href{https://fcchit.github.io/mambagesture/}{textit{https://fcchit.github.io/mambagesture/}}$.
Read more8/29/2024
📈
0
Audio is all in one: speech-driven gesture synthetics using WavLM pre-trained model
Fan Zhang, Naye Ji, Fuxing Gao, Siyuan Zhao, Zhaohan Wang, Shunman Li
The generation of co-speech gestures for digital humans is an emerging area in the field of virtual human creation. Prior research has made progress by using acoustic and semantic information as input and adopting classify method to identify the person's ID and emotion for driving co-speech gesture generation. However, this endeavour still faces significant challenges. These challenges go beyond the intricate interplay between co-speech gestures, speech acoustic, and semantics; they also encompass the complexities associated with personality, emotion, and other obscure but important factors. This paper introduces diffmotion-v2, a speech-conditional diffusion-based and non-autoregressive transformer-based generative model with WavLM pre-trained model. It can produce individual and stylized full-body co-speech gestures only using raw speech audio, eliminating the need for complex multimodal processing and manually annotated. Firstly, considering that speech audio not only contains acoustic and semantic features but also conveys personality traits, emotions, and more subtle information related to accompanying gestures, we pioneer the adaptation of WavLM, a large-scale pre-trained model, to extract low-level and high-level audio information. Secondly, we introduce an adaptive layer norm architecture in the transformer-based layer to learn the relationship between speech information and accompanying gestures. Extensive subjective evaluation experiments are conducted on the Trinity, ZEGGS, and BEAT datasets to confirm the WavLM and the model's ability to synthesize natural co-speech gestures with various styles.
Read more4/16/2024
0
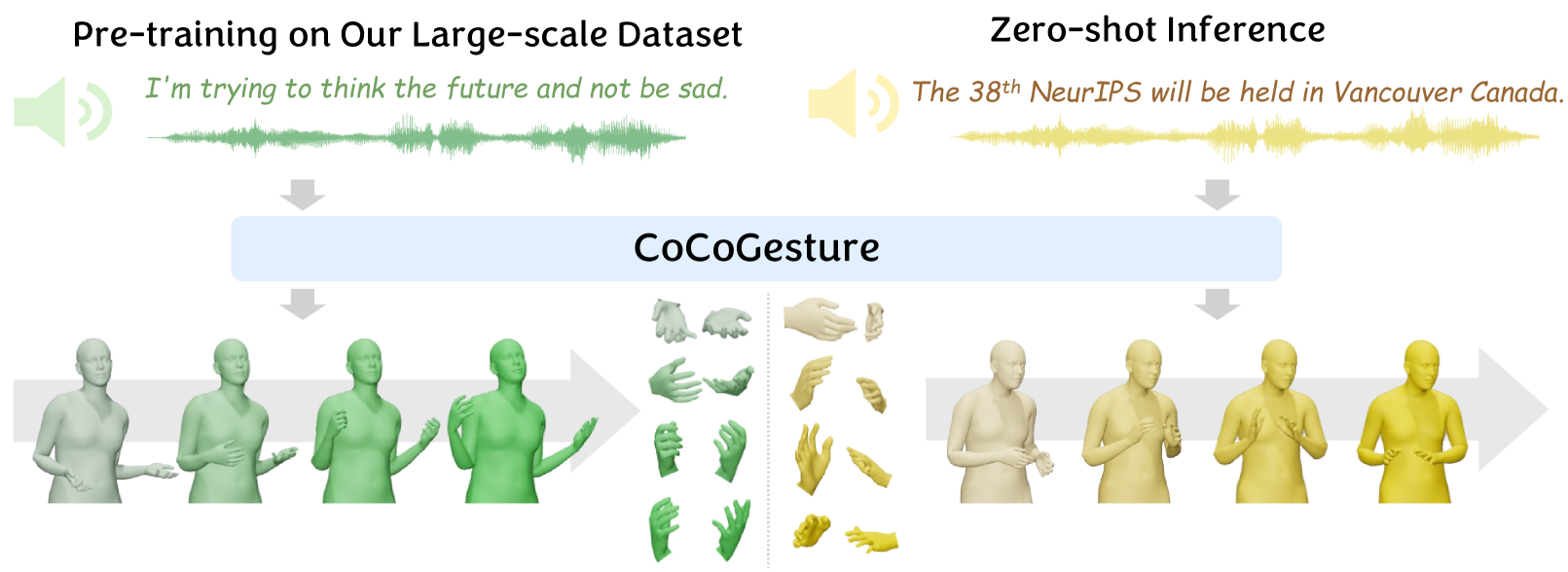
CoCoGesture: Toward Coherent Co-speech 3D Gesture Generation in the Wild
Xingqun Qi, Hengyuan Zhang, Yatian Wang, Jiahao Pan, Chen Liu, Peng Li, Xiaowei Chi, Mengfei Li, Qixun Zhang, Wei Xue, Shanghang Zhang, Wenhan Luo, Qifeng Liu, Yike Guo
Deriving co-speech 3D gestures has seen tremendous progress in virtual avatar animation. Yet, the existing methods often produce stiff and unreasonable gestures with unseen human speech inputs due to the limited 3D speech-gesture data. In this paper, we propose CoCoGesture, a novel framework enabling vivid and diverse gesture synthesis from unseen human speech prompts. Our key insight is built upon the custom-designed pretrain-fintune training paradigm. At the pretraining stage, we aim to formulate a large generalizable gesture diffusion model by learning the abundant postures manifold. Therefore, to alleviate the scarcity of 3D data, we first construct a large-scale co-speech 3D gesture dataset containing more than 40M meshed posture instances across 4.3K speakers, dubbed GES-X. Then, we scale up the large unconditional diffusion model to 1B parameters and pre-train it to be our gesture experts. At the finetune stage, we present the audio ControlNet that incorporates the human voice as condition prompts to guide the gesture generation. Here, we construct the audio ControlNet through a trainable copy of our pre-trained diffusion model. Moreover, we design a novel Mixture-of-Gesture-Experts (MoGE) block to adaptively fuse the audio embedding from the human speech and the gesture features from the pre-trained gesture experts with a routing mechanism. Such an effective manner ensures audio embedding is temporal coordinated with motion features while preserving the vivid and diverse gesture generation. Extensive experiments demonstrate that our proposed CoCoGesture outperforms the state-of-the-art methods on the zero-shot speech-to-gesture generation. The dataset will be publicly available at: https://mattie-e.github.io/GES-X/
Read more5/28/2024