CoCoGesture: Toward Coherent Co-speech 3D Gesture Generation in the Wild

0
Sign in to get full access
Overview
- This paper proposes a new approach called CoCoGesture for generating coherent co-speech 3D gesture animations from speech input.
- The model aims to produce realistic and natural-looking gestures that are synchronized with the input speech.
- The authors leverage large-scale datasets of human gestures to train the model and enable it to generate diverse, expressive gestures.
- The paper presents a comprehensive evaluation, including comparisons to state-of-the-art methods and human perceptual studies.
Plain English Explanation
The researchers developed a new system called CoCoGesture that can generate 3D animated hand and arm gestures to accompany speech. The goal was to create gestures that look natural and match the speech being delivered, just like a human speaker would do. To achieve this, the team used large datasets of real human gestures to train their machine learning model. This allowed the system to learn how people typically gesture when speaking and then apply that knowledge to generate new, believable gestures for any given speech input. The researchers thoroughly tested their system, comparing it to other state-of-the-art methods and getting feedback from human observers, to show that CoCoGesture can produce high-quality, coherent co-speech gestures.
Technical Explanation
The CoCoGesture: Toward Coherent Co-speech 3D Gesture Generation in the Wild paper introduces a new approach for generating 3D hand and arm gestures that are synchronized with and complement input speech. The authors leverage large-scale datasets of human gestures, such as Human3.6M and GENEA, to train a deep learning model that can produce diverse, expressive gestures.
The CoCoGesture model takes speech features as input and generates a sequence of 3D joint positions and rotations to animate a virtual character's hands and arms. The architecture includes modules for speech encoding, gesture planning, and gesture rendering, which work together to create coherent co-speech gestures. The gesture planning module in particular draws inspiration from Semantic Gesticulator, using semantic attributes to guide the gesture generation process.
The researchers conduct a comprehensive evaluation, including comparisons to prior work on co-speech gesture detection and synthesis. They also perform user studies to assess the perceptual quality and coherence of the generated gestures.
Critical Analysis
The CoCoGesture paper presents a promising approach for generating coherent co-speech gestures. The use of large-scale gesture datasets and the incorporation of semantic attributes are noteworthy aspects of the model design. The comprehensive evaluation, including comparisons to prior work and human perceptual studies, lends credibility to the claims about the system's performance.
However, the paper does not extensively discuss potential limitations or future research directions. For example, the authors do not address how the model might handle diverse speaking styles, accents, or languages. Additionally, the generalization capabilities of the system beyond the specific datasets used for training are not explored.
Further research could investigate the model's robustness to variation in speech inputs, as well as its ability to generate gestures that convey more nuanced emotional or pragmatic meanings. Exploring ways to integrate the gesture generation with other aspects of virtual character animation, such as facial expressions and body movements, could also be a fruitful avenue for future work.
Conclusion
The CoCoGesture paper presents a compelling approach for generating coherent co-speech 3D gestures. By leveraging large-scale datasets of human gestures and incorporating semantic attributes, the model can produce diverse and natural-looking gestures that complement input speech. The comprehensive evaluation demonstrates the system's strong performance, both in comparison to prior work and in terms of human perceptual quality.
While the paper does not address all potential limitations, the proposed CoCoGesture method represents a significant advancement in the field of co-speech gesture generation. Further research building upon this work could lead to even more realistic and expressive virtual characters, with applications in areas such as virtual assistants, interactive storytelling, and language learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CoCoGesture: Toward Coherent Co-speech 3D Gesture Generation in the Wild
Xingqun Qi, Hengyuan Zhang, Yatian Wang, Jiahao Pan, Chen Liu, Peng Li, Xiaowei Chi, Mengfei Li, Qixun Zhang, Wei Xue, Shanghang Zhang, Wenhan Luo, Qifeng Liu, Yike Guo
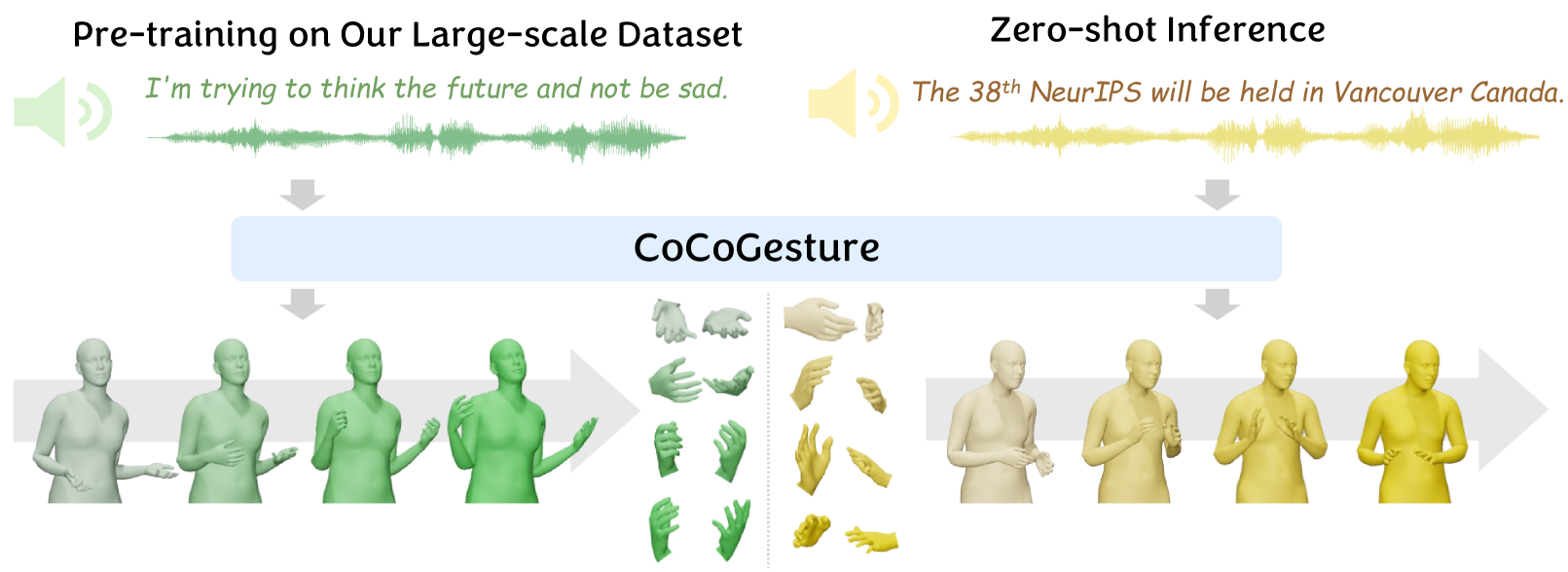
Deriving co-speech 3D gestures has seen tremendous progress in virtual avatar animation. Yet, the existing methods often produce stiff and unreasonable gestures with unseen human speech inputs due to the limited 3D speech-gesture data. In this paper, we propose CoCoGesture, a novel framework enabling vivid and diverse gesture synthesis from unseen human speech prompts. Our key insight is built upon the custom-designed pretrain-fintune training paradigm. At the pretraining stage, we aim to formulate a large generalizable gesture diffusion model by learning the abundant postures manifold. Therefore, to alleviate the scarcity of 3D data, we first construct a large-scale co-speech 3D gesture dataset containing more than 40M meshed posture instances across 4.3K speakers, dubbed GES-X. Then, we scale up the large unconditional diffusion model to 1B parameters and pre-train it to be our gesture experts. At the finetune stage, we present the audio ControlNet that incorporates the human voice as condition prompts to guide the gesture generation. Here, we construct the audio ControlNet through a trainable copy of our pre-trained diffusion model. Moreover, we design a novel Mixture-of-Gesture-Experts (MoGE) block to adaptively fuse the audio embedding from the human speech and the gesture features from the pre-trained gesture experts with a routing mechanism. Such an effective manner ensures audio embedding is temporal coordinated with motion features while preserving the vivid and diverse gesture generation. Extensive experiments demonstrate that our proposed CoCoGesture outperforms the state-of-the-art methods on the zero-shot speech-to-gesture generation. The dataset will be publicly available at: https://mattie-e.github.io/GES-X/
Read more5/28/2024
0
Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
Xu He, Qiaochu Huang, Zhensong Zhang, Zhiwei Lin, Zhiyong Wu, Sicheng Yang, Minglei Li, Zhiyi Chen, Songcen Xu, Xiaofei Wu
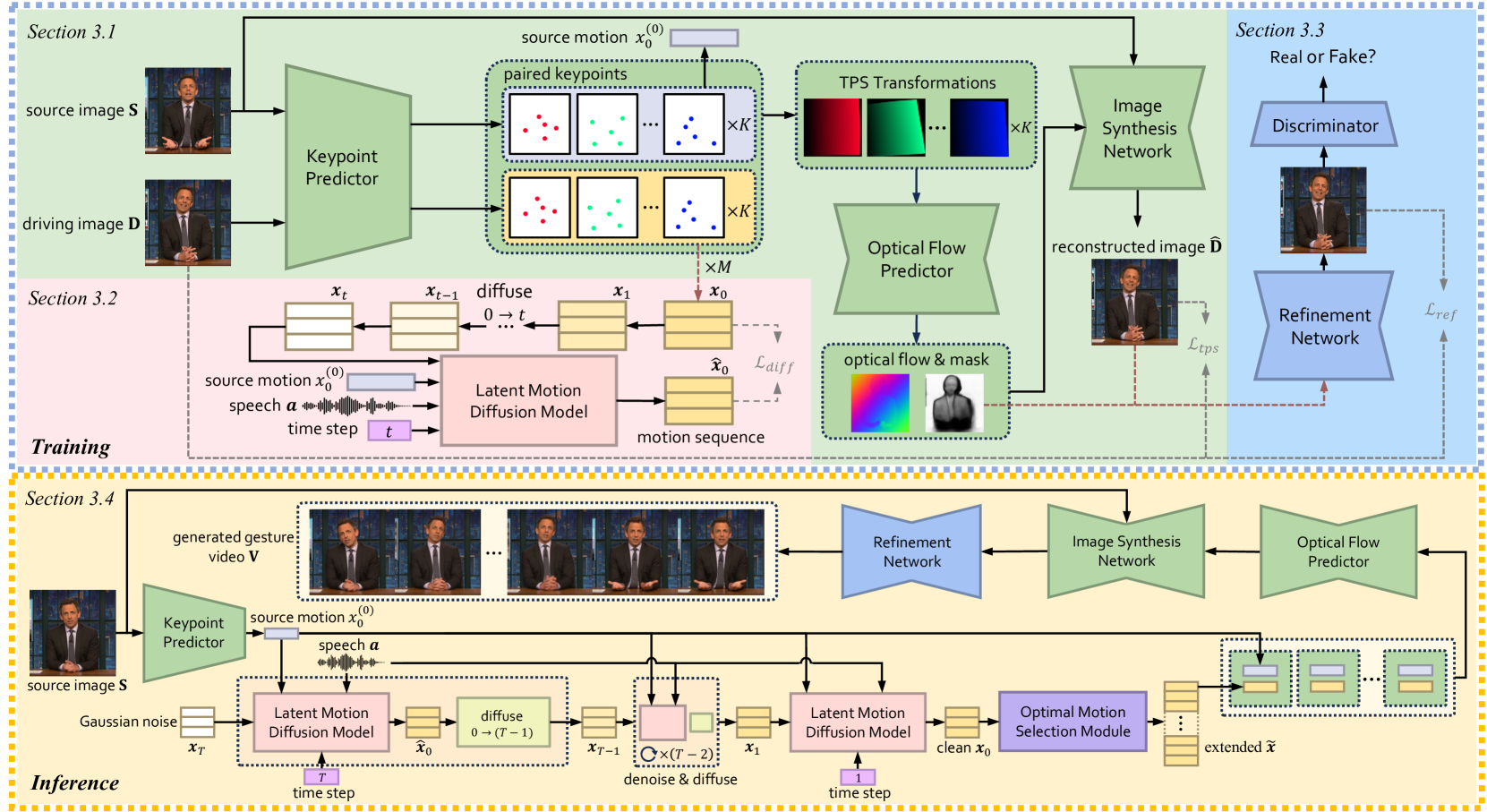
Co-speech gestures, if presented in the lively form of videos, can achieve superior visual effects in human-machine interaction. While previous works mostly generate structural human skeletons, resulting in the omission of appearance information, we focus on the direct generation of audio-driven co-speech gesture videos in this work. There are two main challenges: 1) A suitable motion feature is needed to describe complex human movements with crucial appearance information. 2) Gestures and speech exhibit inherent dependencies and should be temporally aligned even of arbitrary length. To solve these problems, we present a novel motion-decoupled framework to generate co-speech gesture videos. Specifically, we first introduce a well-designed nonlinear TPS transformation to obtain latent motion features preserving essential appearance information. Then a transformer-based diffusion model is proposed to learn the temporal correlation between gestures and speech, and performs generation in the latent motion space, followed by an optimal motion selection module to produce long-term coherent and consistent gesture videos. For better visual perception, we further design a refinement network focusing on missing details of certain areas. Extensive experimental results show that our proposed framework significantly outperforms existing approaches in both motion and video-related evaluations. Our code, demos, and more resources are available at https://github.com/thuhcsi/S2G-MDDiffusion.
Read more4/3/2024
📈
0
Audio is all in one: speech-driven gesture synthetics using WavLM pre-trained model
Fan Zhang, Naye Ji, Fuxing Gao, Siyuan Zhao, Zhaohan Wang, Shunman Li
The generation of co-speech gestures for digital humans is an emerging area in the field of virtual human creation. Prior research has made progress by using acoustic and semantic information as input and adopting classify method to identify the person's ID and emotion for driving co-speech gesture generation. However, this endeavour still faces significant challenges. These challenges go beyond the intricate interplay between co-speech gestures, speech acoustic, and semantics; they also encompass the complexities associated with personality, emotion, and other obscure but important factors. This paper introduces diffmotion-v2, a speech-conditional diffusion-based and non-autoregressive transformer-based generative model with WavLM pre-trained model. It can produce individual and stylized full-body co-speech gestures only using raw speech audio, eliminating the need for complex multimodal processing and manually annotated. Firstly, considering that speech audio not only contains acoustic and semantic features but also conveys personality traits, emotions, and more subtle information related to accompanying gestures, we pioneer the adaptation of WavLM, a large-scale pre-trained model, to extract low-level and high-level audio information. Secondly, we introduce an adaptive layer norm architecture in the transformer-based layer to learn the relationship between speech information and accompanying gestures. Extensive subjective evaluation experiments are conducted on the Trinity, ZEGGS, and BEAT datasets to confirm the WavLM and the model's ability to synthesize natural co-speech gestures with various styles.
Read more4/16/2024
✨
0
SIGGesture: Generalized Co-Speech Gesture Synthesis via Semantic Injection with Large-Scale Pre-Training Diffusion Models
Qingrong Cheng, Xu Li, Xinghui Fu
The automated synthesis of high-quality 3D gestures from speech is of significant value in virtual humans and gaming. Previous methods focus on synthesizing gestures that are synchronized with speech rhythm, yet they frequently overlook the inclusion of semantic gestures. These are sparse and follow a long-tailed distribution across the gesture sequence, making them difficult to learn in an end-to-end manner. Moreover, generating gestures, rhythmically aligned with speech, faces a significant issue that cannot be generalized to in-the-wild speeches. To address these issues, we introduce SIGGesture, a novel diffusion-based approach for synthesizing realistic gestures that are of both high quality and semantically pertinent. Specifically, we firstly build a strong diffusion-based foundation model for rhythmical gesture synthesis by pre-training it on a collected large-scale dataset with pseudo labels. Secondly, we leverage the powerful generalization capabilities of Large Language Models (LLMs) to generate proper semantic gestures for the various speech content. Finally, we propose a semantic injection module to infuse semantic information into the synthesized results during diffusion reverse process. Extensive experiments demonstrate that the proposed SIGGesture significantly outperforms existing baselines and shows excellent generalization and controllability.
Read more5/24/2024