DIRAS: Efficient LLM-Assisted Annotation of Document Relevance in Retrieval Augmented Generation
2406.14162
0
0

Abstract
Retrieval Augmented Generation (RAG) is widely employed to ground responses to queries on domain-specific documents. But do RAG implementations leave out important information or excessively include irrelevant information? To allay these concerns, it is necessary to annotate domain-specific benchmarks to evaluate information retrieval (IR) performance, as relevance definitions vary across queries and domains. Furthermore, such benchmarks should be cost-efficiently annotated to avoid annotation selection bias. In this paper, we propose DIRAS (Domain-specific Information Retrieval Annotation with Scalability), a manual-annotation-free schema that fine-tunes open-sourced LLMs to annotate relevance labels with calibrated relevance probabilities. Extensive evaluation shows that DIRAS fine-tuned models achieve GPT-4-level performance on annotating and ranking unseen (query, document) pairs, and is helpful for real-world RAG development.
Create account to get full access
Overview
- DIRAS is a novel technique that uses Large Language Models (LLMs) to efficiently annotate the relevance of documents in Retrieval Augmented Generation (RAG) systems.
- It addresses the challenge of accurately identifying the most relevant documents to include in the generation process, which is critical for improving the quality of the generated output.
- DIRAS leverages the capabilities of LLMs to quickly and accurately assess the relevance of documents, reducing the need for time-consuming manual annotation.
Plain English Explanation
DIRAS is a new way to help AI systems understand which documents are most relevant when they are generating text. These AI systems, called Retrieval Augmented Generation (RAG) systems, need to find and use the right information from a large number of documents to produce high-quality output. However, manually figuring out which documents are most relevant can be a slow and tedious process.
DIRAS uses powerful language models, called Large Language Models (LLMs), to quickly and accurately assess the relevance of each document. This means the AI system can quickly identify the most important information to include in its text generation, without needing as much human effort. By making this process more efficient, DIRAS can help RAG systems produce better results.
Technical Explanation
DIRAS works by using an LLM to generate relevance scores for each document in a collection. These relevance scores are used to select the most relevant documents to include in the RAG system's generation process. The authors demonstrate that DIRAS can achieve performance comparable to manually annotated relevance, but with significantly less time and effort required.
The key innovations of DIRAS include:
- LLM-based Relevance Scoring: The system uses an LLM to generate a relevance score for each document, which captures the document's relevance to the current generation task.
- Efficient Document Selection: Based on the relevance scores, DIRAS selects a subset of the most relevant documents to include in the generation process, reducing computation and memory requirements.
- Iterative Refinement: The system can iteratively refine the relevance scores and document selection, improving the quality of the generated output over multiple steps.
Experiments on benchmark tasks show that DIRAS can match the performance of manual relevance annotation while being significantly more efficient, making it a valuable tool for improving the capabilities of RAG systems.
Critical Analysis
The paper provides a compelling approach to addressing the challenge of efficiently annotating document relevance for Retrieval Augmented Generation. However, the authors acknowledge some potential limitations:
- The performance of DIRAS is still dependent on the quality and capabilities of the underlying LLM. As language models continue to improve, the benefits of DIRAS may become even more pronounced.
- The paper focuses on general-purpose RAG systems, but the authors note that the approach may need to be adapted for more specialized or domain-specific tasks.
- The iterative refinement process used by DIRAS could potentially be further optimized to reduce computational requirements and improve efficiency.
Overall, DIRAS represents a promising step forward in making Retrieval Augmented Generation more scalable and practical for real-world applications. As the field of large language models continues to advance, techniques like DIRAS will likely play an important role in unlocking the full potential of these powerful AI systems.
Conclusion
DIRAS is a novel approach that leverages the capabilities of large language models to efficiently annotate the relevance of documents for Retrieval Augmented Generation. By automating this previously manual process, DIRAS can significantly reduce the time and effort required to identify the most relevant information for text generation tasks, leading to improved performance and scalability of RAG systems. As language models continue to advance, techniques like DIRAS will play an increasingly important role in making powerful AI-driven text generation more accessible and practical for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
DomainRAG: A Chinese Benchmark for Evaluating Domain-specific Retrieval-Augmented Generation
Shuting Wang, Jiongnan Liu, Shiren Song, Jiehan Cheng, Yuqi Fu, Peidong Guo, Kun Fang, Yutao Zhu, Zhicheng Dou
0
0
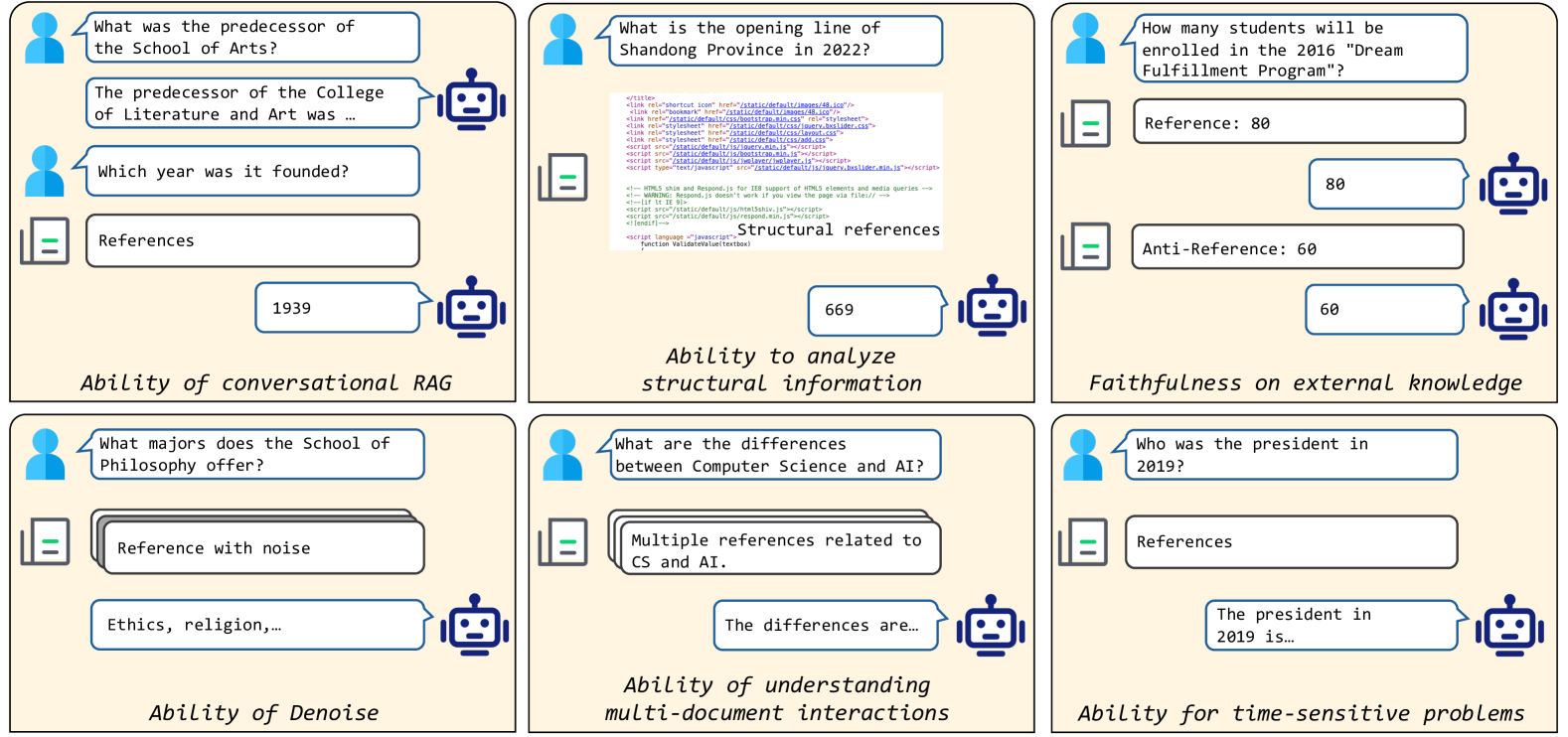
Retrieval-Augmented Generation (RAG) offers a promising solution to address various limitations of Large Language Models (LLMs), such as hallucination and difficulties in keeping up with real-time updates. This approach is particularly critical in expert and domain-specific applications where LLMs struggle to cover expert knowledge. Therefore, evaluating RAG models in such scenarios is crucial, yet current studies often rely on general knowledge sources like Wikipedia to assess the models' abilities in solving common-sense problems. In this paper, we evaluated LLMs by RAG settings in a domain-specific context, college enrollment. We identified six required abilities for RAG models, including the ability in conversational RAG, analyzing structural information, faithfulness to external knowledge, denoising, solving time-sensitive problems, and understanding multi-document interactions. Each ability has an associated dataset with shared corpora to evaluate the RAG models' performance. We evaluated popular LLMs such as Llama, Baichuan, ChatGLM, and GPT models. Experimental results indicate that existing closed-book LLMs struggle with domain-specific questions, highlighting the need for RAG models to solve expert problems. Moreover, there is room for RAG models to improve their abilities in comprehending conversational history, analyzing structural information, denoising, processing multi-document interactions, and faithfulness in expert knowledge. We expect future studies could solve these problems better.
6/18/2024
DR-RAG: Applying Dynamic Document Relevance to Retrieval-Augmented Generation for Question-Answering
Zijian Hei, Weiling Liu, Wenjie Ou, Juyi Qiao, Junming Jiao, Guowen Song, Ting Tian, Yi Lin
0
0
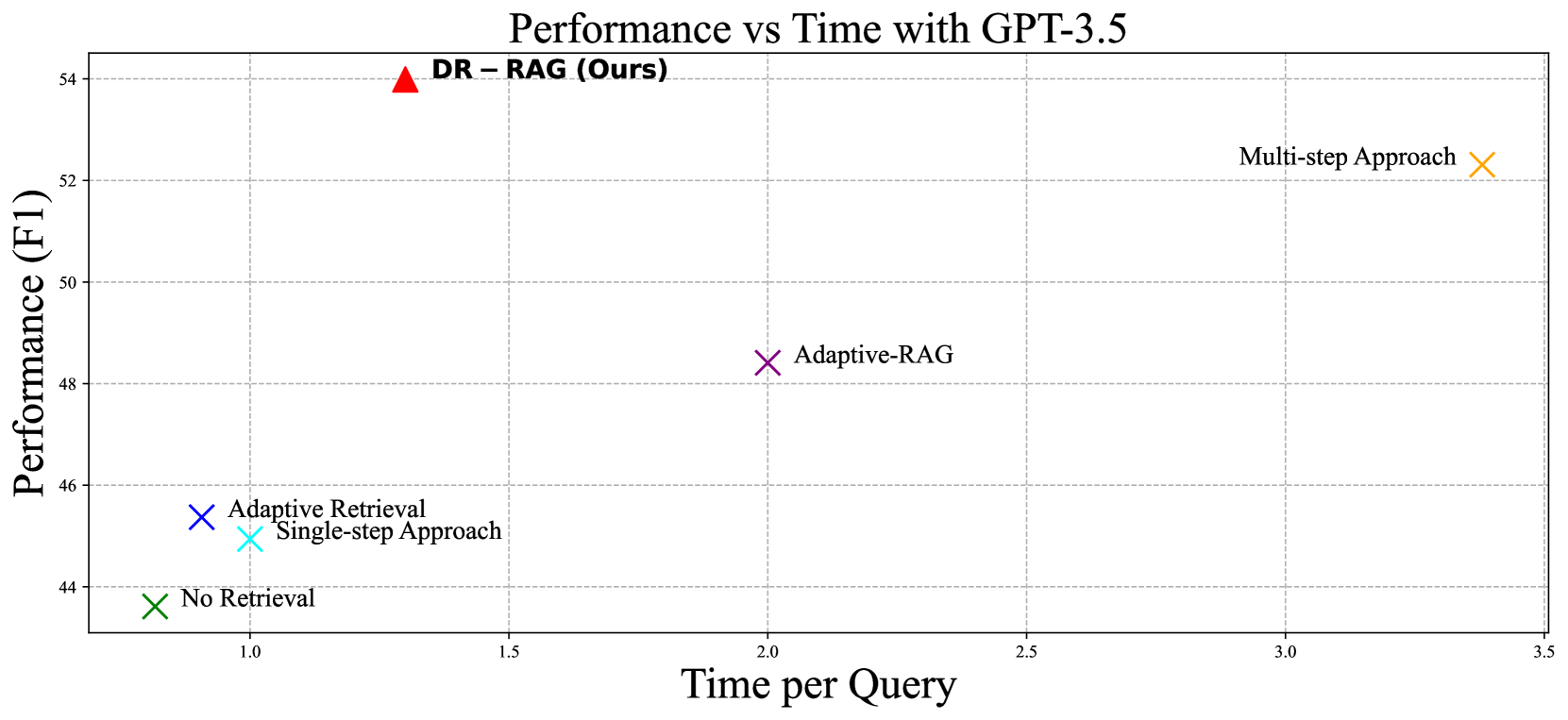
Retrieval-Augmented Generation (RAG) has recently demonstrated the performance of Large Language Models (LLMs) in the knowledge-intensive tasks such as Question-Answering (QA). RAG expands the query context by incorporating external knowledge bases to enhance the response accuracy. However, it would be inefficient to access LLMs multiple times for each query and unreliable to retrieve all the relevant documents by a single query. We have found that even though there is low relevance between some critical documents and query, it is possible to retrieve the remaining documents by combining parts of the documents with the query. To mine the relevance, a two-stage retrieval framework called Dynamic-Relevant Retrieval-Augmented Generation (DR-RAG) is proposed to improve document retrieval recall and the accuracy of answers while maintaining efficiency. Additionally, a compact classifier is applied to two different selection strategies to determine the contribution of the retrieved documents to answering the query and retrieve the relatively relevant documents. Meanwhile, DR-RAG call the LLMs only once, which significantly improves the efficiency of the experiment. The experimental results on multi-hop QA datasets show that DR-RAG can significantly improve the accuracy of the answers and achieve new progress in QA systems.
6/18/2024
🛸
DuetRAG: Collaborative Retrieval-Augmented Generation
Dian Jiao, Li Cai, Jingsheng Huang, Wenqiao Zhang, Siliang Tang, Yueting Zhuang
0
0
Retrieval-Augmented Generation (RAG) methods augment the input of Large Language Models (LLMs) with relevant retrieved passages, reducing factual errors in knowledge-intensive tasks. However, contemporary RAG approaches suffer from irrelevant knowledge retrieval issues in complex domain questions (e.g., HotPot QA) due to the lack of corresponding domain knowledge, leading to low-quality generations. To address this issue, we propose a novel Collaborative Retrieval-Augmented Generation framework, DuetRAG. Our bootstrapping philosophy is to simultaneously integrate the domain fintuning and RAG models to improve the knowledge retrieval quality, thereby enhancing generation quality. Finally, we demonstrate DuetRAG' s matches with expert human researchers on HotPot QA.
5/24/2024

RE-RAG: Improving Open-Domain QA Performance and Interpretability with Relevance Estimator in Retrieval-Augmented Generation
Kiseung Kim, Jay-Yoon Lee
0
0
The Retrieval Augmented Generation (RAG) framework utilizes a combination of parametric knowledge and external knowledge to demonstrate state-of-the-art performance on open-domain question answering tasks. However, the RAG framework suffers from performance degradation when the query is accompanied by irrelevant contexts. In this work, we propose the RE-RAG framework, which introduces a relevance estimator (RE) that not only provides relative relevance between contexts as previous rerankers did, but also provides confidence, which can be used to classify whether given context is useful for answering the given question. We propose a weakly supervised method for training the RE simply utilizing question-answer data without any labels for correct contexts. We show that RE trained with a small generator (sLM) can not only improve the sLM fine-tuned together with RE but also improve previously unreferenced large language models (LLMs). Furthermore, we investigate new decoding strategies that utilize the proposed confidence measured by RE such as choosing to let the user know that it is unanswerable to answer the question given the retrieved contexts or choosing to rely on LLM's parametric knowledge rather than unrelated contexts.
6/18/2024