Direct Preference Optimization for Neural Machine Translation with Minimum Bayes Risk Decoding
2311.08380
0
0
🛠️
Abstract
Minimum Bayes Risk (MBR) decoding can significantly improve translation performance of Multilingual Large Language Models (MLLMs). However, MBR decoding is computationally expensive. We show how the recently developed Reinforcement Learning technique, Direct Preference Optimization (DPO), can fine-tune MLLMs to get the gains of MBR without any additional computation in inference. Our method uses only a small monolingual fine-tuning set and yields significantly improved performance on multiple NMT test sets compared to MLLMs without DPO.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Multilingual Large Language Models (MLLMs) can significantly improve translation performance using Minimum Bayes Risk (MBR) decoding, but MBR decoding is computationally expensive.
- The paper introduces a new Reinforcement Learning technique called Direct Preference Optimization (DPO) that can fine-tune MLLMs to get the gains of MBR without additional computation during inference.
- The method uses only a small monolingual fine-tuning set and significantly improves performance on multiple Neural Machine Translation (NMT) test sets compared to MLLMs without DPO.
Plain English Explanation
Large language models trained on data from multiple languages (MLLMs) can significantly improve the quality of machine translation when using a technique called Minimum Bayes Risk (MBR) decoding. However, MBR decoding is computationally intensive, making it difficult to use in practical applications.
The researchers developed a new method called Direct Preference Optimization (DPO) that can fine-tune MLLMs to get the same translation quality improvements as MBR, but without the extra computational cost during actual translation. Their approach only requires a small amount of monolingual data to fine-tune the model, and it leads to much better translation performance on various test sets compared to using the original MLLM without DPO.
Technical Explanation
The paper demonstrates how applying Direct Preference Optimization (DPO) can fine-tune Multilingual Large Language Models (MLLMs) to achieve the benefits of Minimum Bayes Risk (MBR) decoding without the computational expense.
MBR decoding is a technique that improves the quality of machine translations produced by MLLMs, but it requires significant additional computation during the translation process. The authors show how DPO, a recently developed Reinforcement Learning method, can be used to fine-tune the MLLM to mimic the behavior of MBR decoding. This DPO fine-tuning is done using only a small amount of monolingual data, and it leads to substantial improvements in translation performance on multiple Neural Machine Translation (NMT) test sets compared to the original MLLM without DPO.
The paper also discusses connections between this work and other recent research on provably robust DPO, direct Nash optimization for teaching language models, strengthening multimodal large language models with bootstrapped preference learning, and binary classifier optimization for large language model alignment.
Critical Analysis
The paper provides a compelling approach to improving the translation performance of MLLMs without the computational overhead of MBR decoding. The use of DPO to fine-tune the model is an innovative technique that appears to yield significant benefits.
One potential limitation of the work is that it relies on having a small monolingual dataset for the fine-tuning process. In real-world scenarios, access to high-quality monolingual data may be a challenge, especially for lower-resource languages. The authors do not explore the sensitivity of their method to the size or quality of the fine-tuning dataset.
Additionally, the paper does not provide a deep analysis of the specific mechanisms by which the DPO fine-tuning leads to the observed translation quality improvements. A more detailed investigation of the internal model behavior and how it differs from the original MLLM could provide additional insights.
Overall, the research presents a promising approach to enhancing the practical applications of MLLMs for machine translation tasks. Further exploration of the method's robustness and generalizability could strengthen the contribution of this work.
Conclusion
This paper introduces a novel technique called Direct Preference Optimization (DPO) that can fine-tune Multilingual Large Language Models (MLLMs) to achieve the benefits of Minimum Bayes Risk (MBR) decoding without the computational overhead. The method uses only a small monolingual dataset to fine-tune the MLLM and leads to significant improvements in translation performance on multiple Neural Machine Translation (NMT) test sets.
The research demonstrates the potential of DPO to optimize language models for specific tasks, such as machine translation, in a more efficient manner than traditional approaches. This work could have important implications for making high-quality machine translation more accessible and practical, particularly for low-resource language pairs. Further exploration of the method's limitations and broader applications could enhance our understanding of how to effectively leverage large language models for real-world natural language processing tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
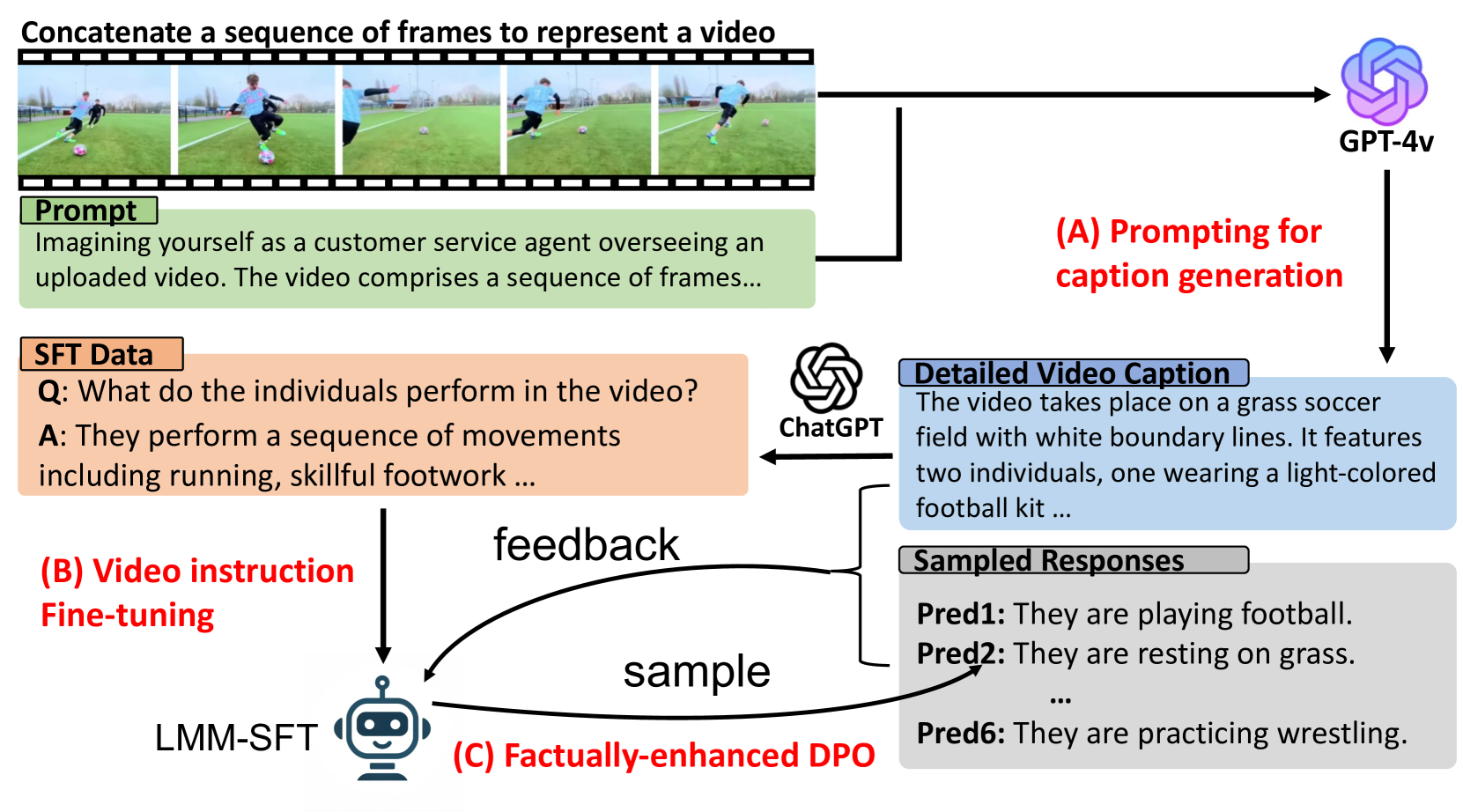
Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward
Ruohong Zhang, Liangke Gui, Zhiqing Sun, Yihao Feng, Keyang Xu, Yuanhan Zhang, Di Fu, Chunyuan Li, Alexander Hauptmann, Yonatan Bisk, Yiming Yang
0
0
Preference modeling techniques, such as direct preference optimization (DPO), has shown effective in enhancing the generalization abilities of large language model (LLM). However, in tasks involving video instruction-following, providing informative feedback, especially for detecting hallucinations in generated responses, remains a significant challenge. Previous studies have explored using large large multimodal models (LMMs) as reward models to guide preference modeling, but their ability to accurately assess the factuality of generated responses compared to corresponding videos has not been conclusively established. This paper introduces a novel framework that utilizes detailed video captions as a proxy of video content, enabling language models to incorporate this information as supporting evidence for scoring video Question Answering (QA) predictions. Our approach demonstrates robust alignment with OpenAI GPT-4V model's reward mechanism, which directly takes video frames as input. Furthermore, we show that applying this tailored reward through DPO significantly improves the performance of video LMMs on video QA tasks.
4/3/2024
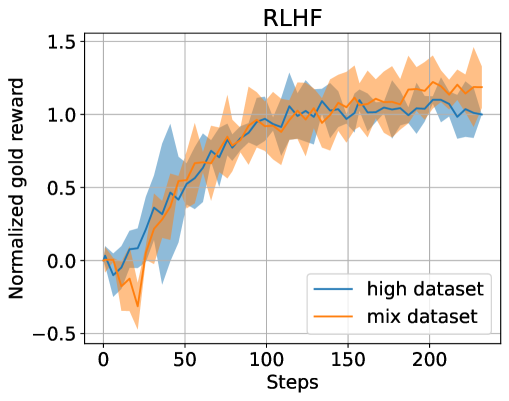
Filtered Direct Preference Optimization
Tetsuro Morimura, Mitsuki Sakamoto, Yuu Jinnai, Kenshi Abe, Kaito Ariu
0
0
Reinforcement learning from human feedback (RLHF) plays a crucial role in aligning language models with human preferences. While the significance of dataset quality is generally recognized, explicit investigations into its impact within the RLHF framework, to our knowledge, have been limited. This paper addresses the issue of text quality within the preference dataset by focusing on Direct Preference Optimization (DPO), an increasingly adopted reward-model-free RLHF method. We confirm that text quality significantly influences the performance of models optimized with DPO more than those optimized with reward-model-based RLHF. Building on this new insight, we propose an extension of DPO, termed filtered direct preference optimization (fDPO). fDPO uses a trained reward model to monitor the quality of texts within the preference dataset during DPO training. Samples of lower quality are discarded based on comparisons with texts generated by the model being optimized, resulting in a more accurate dataset. Experimental results demonstrate that fDPO enhances the final model performance. Our code is available at https://github.com/CyberAgentAILab/filtered-dpo.
4/24/2024
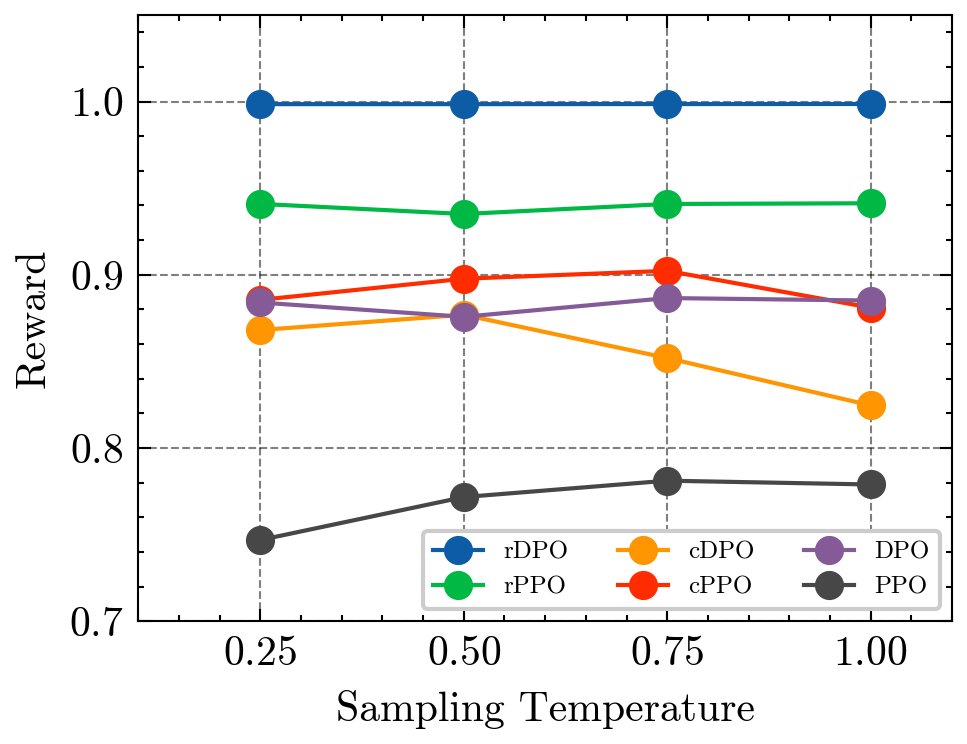
Provably Robust DPO: Aligning Language Models with Noisy Feedback
Sayak Ray Chowdhury, Anush Kini, Nagarajan Natarajan
0
0
Learning from preference-based feedback has recently gained traction as a promising approach to align language models with human interests. While these aligned generative models have demonstrated impressive capabilities across various tasks, their dependence on high-quality human preference data poses a bottleneck in practical applications. Specifically, noisy (incorrect and ambiguous) preference pairs in the dataset might restrict the language models from capturing human intent accurately. While practitioners have recently proposed heuristics to mitigate the effect of noisy preferences, a complete theoretical understanding of their workings remain elusive. In this work, we aim to bridge this gap by by introducing a general framework for policy optimization in the presence of random preference flips. We focus on the direct preference optimization (DPO) algorithm in particular since it assumes that preferences adhere to the Bradley-Terry-Luce (BTL) model, raising concerns about the impact of noisy data on the learned policy. We design a novel loss function, which de-bias the effect of noise on average, making a policy trained by minimizing that loss robust to the noise. Under log-linear parameterization of the policy class and assuming good feature coverage of the SFT policy, we prove that the sub-optimality gap of the proposed robust DPO (rDPO) policy compared to the optimal policy is of the order $O(frac{1}{1-2epsilon}sqrt{frac{d}{n}})$, where $epsilon < 1/2$ is flip rate of labels, $d$ is policy parameter dimension and $n$ is size of dataset. Our experiments on IMDb sentiment generation and Anthropic's helpful-harmless dataset show that rDPO is robust to noise in preference labels compared to vanilla DPO and other heuristics proposed by practitioners.
4/15/2024
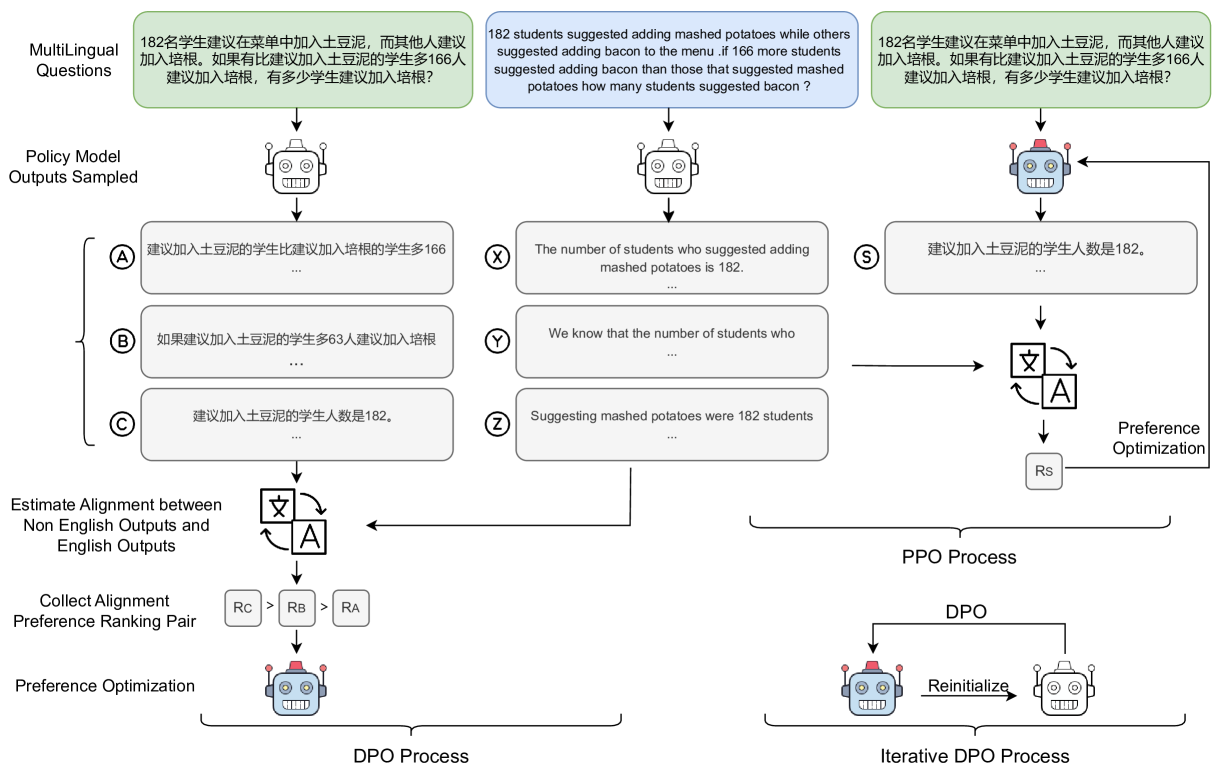
MAPO: Advancing Multilingual Reasoning through Multilingual Alignment-as-Preference Optimization
Shuaijie She, Wei Zou, Shujian Huang, Wenhao Zhu, Xiang Liu, Xiang Geng, Jiajun Chen
0
0
Though reasoning abilities are considered language-agnostic, existing LLMs exhibit inconsistent reasoning abilities across different languages, e.g., reasoning in the dominant language like English is superior to other languages due to the imbalance of multilingual training data. To enhance reasoning abilities in non-dominant languages, we propose a Multilingual-Alignment-as-Preference Optimization framework (MAPO), aiming to align the reasoning processes in other languages with the dominant language. Specifically, we harness an off-the-shelf translation model for the consistency between answers in non-dominant and dominant languages, which we adopt as the preference for optimization, e.g., Direct Preference Optimization (DPO) or Proximal Policy Optimization (PPO). Experiments show that MAPO stably achieves significant improvements in the multilingual reasoning of various models on all three benchmarks (MSVAMP +16.2%, MGSM +6.1%, and MNumGLUESub +13.3%), with improved reasoning consistency across languages.
4/16/2024