Direct Nash Optimization: Teaching Language Models to Self-Improve with General Preferences
2404.03715
52
1

Abstract
This paper studies post-training large language models (LLMs) using preference feedback from a powerful oracle to help a model iteratively improve over itself. The typical approach for post-training LLMs involves Reinforcement Learning from Human Feedback (RLHF), which traditionally separates reward learning and subsequent policy optimization. However, such a reward maximization approach is limited by the nature of point-wise rewards (such as Bradley-Terry model), which fails to express complex intransitive or cyclic preference relations. While advances on RLHF show reward learning and policy optimization can be merged into a single contrastive objective for stability, they yet still remain tethered to the reward maximization framework. Recently, a new wave of research sidesteps the reward maximization presumptions in favor of directly optimizing over pair-wise or general preferences. In this paper, we introduce Direct Nash Optimization (DNO), a provable and scalable algorithm that marries the simplicity and stability of contrastive learning with theoretical generality from optimizing general preferences. Because DNO is a batched on-policy algorithm using a regression-based objective, its implementation is straightforward and efficient. Moreover, DNO enjoys monotonic improvement across iterations that help it improve even over a strong teacher (such as GPT-4). In our experiments, a resulting 7B parameter Orca-2.5 model aligned by DNO achieves the state-of-the-art win-rate against GPT-4-Turbo of 33% on AlpacaEval 2.0 (even after controlling for response length), an absolute gain of 26% (7% to 33%) over the initializing model. It outperforms models with far more parameters, including Mistral Large, Self-Rewarding LM (70B parameters), and older versions of GPT-4.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a novel approach called "Direct Nash Optimization" (DNO) for teaching language models to self-improve with general preferences.
- The key idea is to formulate the model training process as a game between the language model and a reward model, where the language model tries to generate outputs that maximize the reward model's score.
- This approach is designed to be more flexible and scalable than existing techniques like Reinforcement Learning from Human Feedback (RLHF), which rely on hand-crafted reward functions.
Plain English Explanation
The researchers have developed a new method called "Direct Nash Optimization" (DNO) to help language models like GPT-3 or GPT-4 get better at tasks over time.
The basic idea is to set up a "game" between the language model and another model called a "reward model". The reward model's job is to evaluate how good the language model's outputs are, based on some general preferences or goals. The language model then tries to generate outputs that maximize the reward model's score.
This is different from other approaches like Reinforcement Learning from Human Feedback (RLHF), which rely on humans manually defining reward functions. With DNO, the reward model can learn more general preferences, making the system more flexible and scalable.
The key advantage of this approach is that it allows the language model to keep improving itself, without needing constant human oversight or intervention. The language model essentially learns to "self-improve" by optimizing for the reward model's preferences.
Technical Explanation
The paper introduces a new training framework called "Direct Nash Optimization" (DNO) that aims to teach language models to self-improve according to general preferences, rather than relying on hand-crafted reward functions.
The core idea is to formulate the model training process as a game between the language model and a reward model. The language model tries to generate outputs that maximize the reward model's score, while the reward model tries to accurately capture the desired preferences. This "Nash equilibrium" leads the language model to learn to generate outputs that align with the general preferences encoded in the reward model.
The authors show that this approach has several advantages over existing techniques like Reinforcement Learning from Human Feedback (RLHF). First, the reward model can learn more general preferences, rather than being limited to specific reward functions. Second, the language model can keep improving itself through this optimization process, without needing constant human oversight.
Theoretically, the authors provide convergence guarantees for this approach under certain assumptions, and demonstrate its robustness to noise in the reward model.
Critical Analysis
The paper presents a compelling and well-grounded framework for teaching language models to self-improve according to general preferences. The theoretical analysis and empirical results suggest that DNO has the potential to be a more flexible and scalable alternative to RLHF.
However, the authors acknowledge several limitations and areas for further research. For example, the current formulation assumes that the reward model is static, whereas in practice, it may need to adapt and evolve over time. Additionally, the authors note that the performance of DNO may depend on the specific architecture and training procedures used for the language model and reward model.
Another potential concern is the risk of reward model misspecification, where the preferences encoded in the reward model may not fully align with the desired outcomes. This could lead to unintended consequences or behaviors from the language model. Careful monitoring and evaluation of the reward model's performance would be crucial in such cases.
Finally, the authors do not address the potential computational and resource requirements of the DNO approach, which could be a practical concern for deploying these systems at scale. Techniques like Online Control and Adaptive Large Neighborhood Search may be helpful in addressing these challenges.
Conclusion
The "Direct Nash Optimization" framework introduced in this paper represents a significant step forward in teaching language models to self-improve according to general preferences. By formulating the training process as a game between the language model and a reward model, the authors have developed a more flexible and scalable approach than existing techniques like RLHF.
While the paper highlights several promising theoretical and empirical results, it also acknowledges important limitations and areas for further research. Careful attention to reward model specification, computational efficiency, and potential unintended consequences will be crucial as this approach is further developed and deployed in real-world applications.
Overall, the DNO framework is a valuable contribution to the field of language model optimization, and it will be exciting to see how it evolves and is applied to address the growing demand for highly capable and aligned AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
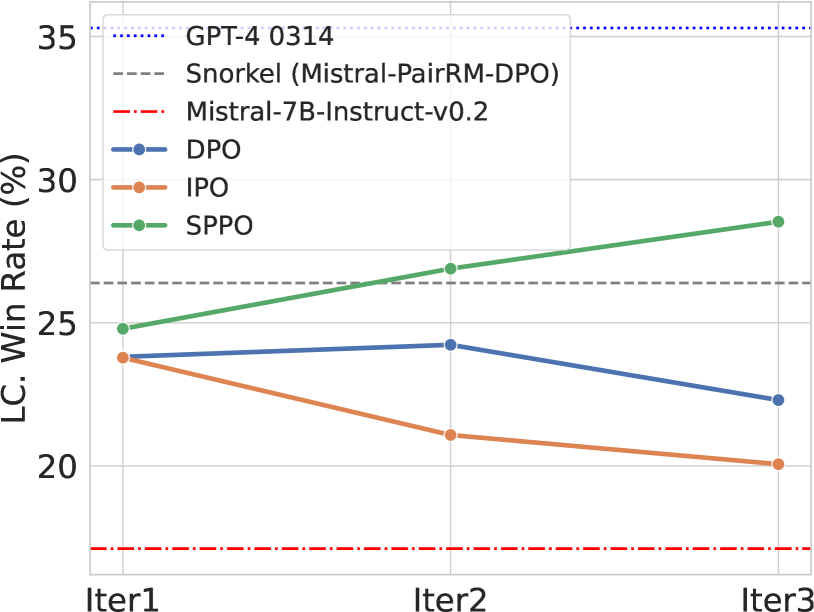
Self-Play Preference Optimization for Language Model Alignment
Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, Quanquan Gu
0
0
Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences. Recent advancements suggest that directly working with preference probabilities can yield a more accurate reflection of human preferences, enabling more flexible and accurate language model alignment. In this paper, we propose a self-play-based method for language model alignment, which treats the problem as a constant-sum two-player game aimed at identifying the Nash equilibrium policy. Our approach, dubbed textit{Self-Play Preference Optimization} (SPPO), approximates the Nash equilibrium through iterative policy updates and enjoys theoretical convergence guarantee. Our method can effectively increase the log-likelihood of the chosen response and decrease that of the rejected response, which cannot be trivially achieved by symmetric pairwise loss such as Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO). In our experiments, using only 60k prompts (without responses) from the UltraFeedback dataset and without any prompt augmentation, by leveraging a pre-trained preference model PairRM with only 0.4B parameters, SPPO can obtain a model from fine-tuning Mistral-7B-Instruct-v0.2 that achieves the state-of-the-art length-controlled win-rate of 28.53% against GPT-4-Turbo on AlpacaEval 2.0. It also outperforms the (iterative) DPO and IPO on MT-Bench and the Open LLM Leaderboard. Notably, the strong performance of SPPO is achieved without additional external supervision (e.g., responses, preferences, etc.) from GPT-4 or other stronger language models.
5/2/2024
🏅
Online Iterative Reinforcement Learning from Human Feedback with General Preference Model
Chenlu Ye, Wei Xiong, Yuheng Zhang, Nan Jiang, Tong Zhang
0
0
We study Reinforcement Learning from Human Feedback (RLHF) under a general preference oracle. In particular, we do not assume that there exists a reward function and the preference signal is drawn from the Bradley-Terry model as most of the prior works do. We consider a standard mathematical formulation, the reverse-KL regularized minimax game between two LLMs for RLHF under general preference oracle. The learning objective of this formulation is to find a policy so that it is consistently preferred by the KL-regularized preference oracle over any competing LLMs. We show that this framework is strictly more general than the reward-based one, and propose sample-efficient algorithms for both the offline learning from a pre-collected preference dataset and online learning where we can query the preference oracle along the way of training. Empirical studies verify the effectiveness of the proposed framework.
4/26/2024
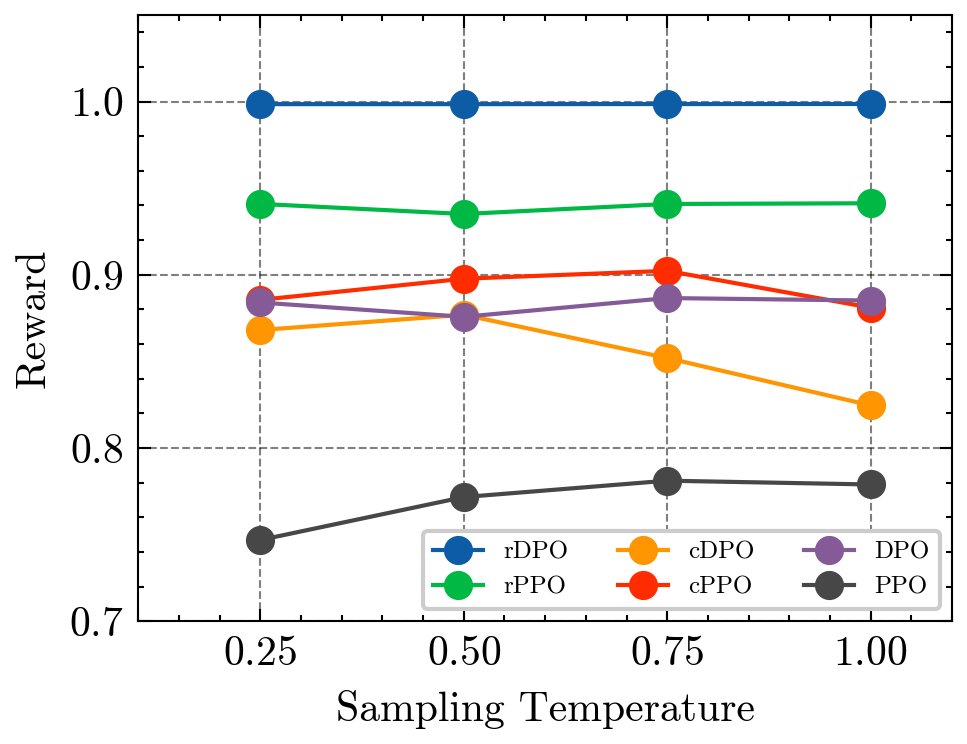
Provably Robust DPO: Aligning Language Models with Noisy Feedback
Sayak Ray Chowdhury, Anush Kini, Nagarajan Natarajan
0
0
Learning from preference-based feedback has recently gained traction as a promising approach to align language models with human interests. While these aligned generative models have demonstrated impressive capabilities across various tasks, their dependence on high-quality human preference data poses a bottleneck in practical applications. Specifically, noisy (incorrect and ambiguous) preference pairs in the dataset might restrict the language models from capturing human intent accurately. While practitioners have recently proposed heuristics to mitigate the effect of noisy preferences, a complete theoretical understanding of their workings remain elusive. In this work, we aim to bridge this gap by by introducing a general framework for policy optimization in the presence of random preference flips. We focus on the direct preference optimization (DPO) algorithm in particular since it assumes that preferences adhere to the Bradley-Terry-Luce (BTL) model, raising concerns about the impact of noisy data on the learned policy. We design a novel loss function, which de-bias the effect of noise on average, making a policy trained by minimizing that loss robust to the noise. Under log-linear parameterization of the policy class and assuming good feature coverage of the SFT policy, we prove that the sub-optimality gap of the proposed robust DPO (rDPO) policy compared to the optimal policy is of the order $O(frac{1}{1-2epsilon}sqrt{frac{d}{n}})$, where $epsilon < 1/2$ is flip rate of labels, $d$ is policy parameter dimension and $n$ is size of dataset. Our experiments on IMDb sentiment generation and Anthropic's helpful-harmless dataset show that rDPO is robust to noise in preference labels compared to vanilla DPO and other heuristics proposed by practitioners.
4/15/2024

From $r$ to $Q^*$: Your Language Model is Secretly a Q-Function
Rafael Rafailov, Joey Hejna, Ryan Park, Chelsea Finn
0
0
Reinforcement Learning From Human Feedback (RLHF) has been a critical to the success of the latest generation of generative AI models. In response to the complex nature of the classical RLHF pipeline, direct alignment algorithms such as Direct Preference Optimization (DPO) have emerged as an alternative approach. Although DPO solves the same objective as the standard RLHF setup, there is a mismatch between the two approaches. Standard RLHF deploys reinforcement learning in a specific token-level MDP, while DPO is derived as a bandit problem in which the whole response of the model is treated as a single arm. In this work we rectify this difference, first we theoretically show that we can derive DPO in the token-level MDP as a general inverse Q-learning algorithm, which satisfies the Bellman equation. Using our theoretical results, we provide three concrete empirical insights. First, we show that because of its token level interpretation, DPO is able to perform some type of credit assignment. Next, we prove that under the token level formulation, classical search-based algorithms, such as MCTS, which have recently been applied to the language generation space, are equivalent to likelihood-based search on a DPO policy. Empirically we show that a simple beam search yields meaningful improvement over the base DPO policy. Finally, we show how the choice of reference policy causes implicit rewards to decline during training. We conclude by discussing applications of our work, including information elicitation in multi-tun dialogue, reasoning, agentic applications and end-to-end training of multi-model systems.
4/19/2024