Discovery of Generalizable TBI Phenotypes Using Multivariate Time-Series Clustering

0
🔗
Sign in to get full access
Overview
- Traumatic Brain Injury (TBI) has a wide range of clinical presentations and outcomes due to its inherent diversity.
- Identifying consistent TBI phenotypes (subtypes) across different populations is a critical research gap.
- This study used multivariate time-series clustering to reveal the dynamic complexities of TBI.
Plain English Explanation
Traumatic Brain Injury (TBI) is a serious medical condition that can have very different symptoms and recovery paths in different people. This is because TBI is a complex disorder with many possible causes and effects. Researchers have struggled to identify consistent TBI subtypes that apply across different patient groups.
In this study, the researchers used an advanced machine learning technique called multivariate time-series clustering to better understand the patterns in TBI. They analyzed data from two large TBI databases - one focused on research and one from real-world clinical settings. Interestingly, the researchers found that the optimal clustering approach and number of TBI subtypes were consistent across these very different datasets. This suggests their method can reliably identify generalizable TBI subtypes.
The analysis revealed three main TBI phenotypes or subtypes:
- Phenotype α represents mild TBI with a very consistent clinical presentation.
- Phenotype β signifies severe TBI with diverse clinical symptoms.
- Phenotype γ represents a moderate TBI profile in terms of severity and clinical diversity.
Importantly, the core characteristics of these TBI subtypes remained consistent even when looking at different age groups. However, age was found to be a significant factor in TBI outcomes, with older patients having higher mortality rates.
Technical Explanation
The researchers employed a self-supervised learning-based approach to cluster multivariate time-series data with missing values, called SLAC-Time. They applied this method to analyze data from two large TBI datasets: the research-focused TRACK-TBI and the real-world MIMIC-IV.
Remarkably, the optimal hyperparameters of SLAC-Time and the ideal number of clusters (three) were consistent across these two very different datasets. This demonstrates the stability and generalizability of the SLAC-Time approach for identifying TBI phenotypes.
The analysis revealed three distinct TBI phenotypes. Phenotype α represents mild TBI cases with a highly consistent set of clinical features during emergency department visits and ICU stays. In contrast, phenotype β signifies severe TBI with diverse clinical manifestations. Phenotype γ exhibits a moderate TBI profile, sitting between the mild and severe cases in terms of both severity and clinical diversity.
Interestingly, while certain features varied by patient age, the core characteristics of these three TBI phenotypes remained consistent across diverse populations. Age was found to be a significant determinant of TBI outcomes, with older cohorts experiencing higher mortality rates.
Critical Analysis
The researchers' use of multivariate time-series clustering is a novel and promising approach for identifying generalizable TBI subtypes. The consistent findings across the TRACK-TBI and MIMIC-IV datasets suggest this method can reliably uncover stable TBI phenotypes, which is a critical gap in TBI research.
However, the study does not provide detailed information on the specific clinical features and symptom profiles associated with each TBI phenotype. Further research is needed to fully characterize and validate these subtypes, including exploring their relationships to underlying neurological mechanisms, treatment responsiveness, and long-term outcomes.
Additionally, while the researchers noted that certain features varied by age, the paper does not delve deeply into how age-related factors may influence the manifestation and progression of these TBI phenotypes. More work is needed to understand the interplay between age, TBI subtype, and clinical trajectories.
Conclusion
This study presents a novel, data-driven approach to uncover generalizable TBI phenotypes using multivariate time-series clustering. The identification of three consistent TBI subtypes - mild, severe, and moderate - across diverse datasets is an important step forward in understanding the heterogeneity of this condition.
The findings highlight the potential for using advanced machine learning techniques to improve TBI characterization and, ultimately, inform more personalized treatment and rehabilitation strategies. Further research is needed to fully validate and expand upon these TBI phenotypes, but this work represents a significant advance in the quest to better manage the complex and variable nature of Traumatic Brain Injury.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔗
0
Discovery of Generalizable TBI Phenotypes Using Multivariate Time-Series Clustering
Hamid Ghaderi, Brandon Foreman, Chandan K. Reddy, Vignesh Subbian
Traumatic Brain Injury (TBI) presents a broad spectrum of clinical presentations and outcomes due to its inherent heterogeneity, leading to diverse recovery trajectories and varied therapeutic responses. While many studies have delved into TBI phenotyping for distinct patient populations, identifying TBI phenotypes that consistently generalize across various settings and populations remains a critical research gap. Our research addresses this by employing multivariate time-series clustering to unveil TBI's dynamic intricates. Utilizing a self-supervised learning-based approach to clustering multivariate time-Series data with missing values (SLAC-Time), we analyzed both the research-centric TRACK-TBI and the real-world MIMIC-IV datasets. Remarkably, the optimal hyperparameters of SLAC-Time and the ideal number of clusters remained consistent across these datasets, underscoring SLAC-Time's stability across heterogeneous datasets. Our analysis revealed three generalizable TBI phenotypes ({alpha}, b{eta}, and {gamma}), each exhibiting distinct non-temporal features during emergency department visits, and temporal feature profiles throughout ICU stays. Specifically, phenotype {alpha} represents mild TBI with a remarkably consistent clinical presentation. In contrast, phenotype b{eta} signifies severe TBI with diverse clinical manifestations, and phenotype {gamma} represents a moderate TBI profile in terms of severity and clinical diversity. Age is a significant determinant of TBI outcomes, with older cohorts recording higher mortality rates. Importantly, while certain features varied by age, the core characteristics of TBI manifestations tied to each phenotype remain consistent across diverse populations.
Read more8/22/2024
🔗
0
Clustering of Disease Trajectories with Explainable Machine Learning: A Case Study on Postoperative Delirium Phenotypes
Xiaochen Zheng, Manuel Schurch, Xingyu Chen, Maria Angeliki Komninou, Reto Schupbach, Ahmed Allam, Jan Bartussek, Michael Krauthammer
The identification of phenotypes within complex diseases or syndromes is a fundamental component of precision medicine, which aims to adapt healthcare to individual patient characteristics. Postoperative delirium (POD) is a complex neuropsychiatric condition with significant heterogeneity in its clinical manifestations and underlying pathophysiology. We hypothesize that POD comprises several distinct phenotypes, which cannot be directly observed in clinical practice. Identifying these phenotypes could enhance our understanding of POD pathogenesis and facilitate the development of targeted prevention and treatment strategies. In this paper, we propose an approach that combines supervised machine learning for personalized POD risk prediction with unsupervised clustering techniques to uncover potential POD phenotypes. We first demonstrate our approach using synthetic data, where we simulate patient cohorts with predefined phenotypes based on distinct sets of informative features. We aim to mimic any clinical disease with our synthetic data generation method. By training a predictive model and applying SHAP, we show that clustering patients in the SHAP feature importance space successfully recovers the true underlying phenotypes, outperforming clustering in the raw feature space. We then present a case study using real-world data from a cohort of elderly surgical patients. The results showcase the utility of our approach in uncovering clinically relevant subtypes of complex disorders like POD, paving the way for more precise and personalized treatment strategies.
Read more5/7/2024

0
Leveraging Persistent Homology for Differential Diagnosis of Mild Cognitive Impairment
Ninad Aithal, Debanjali Bhattacharya, Neelam Sinha, Thomas Gregor Issac
Mild cognitive impairment (MCI) is characterized by subtle changes in cognitive functions, often associated with disruptions in brain connectivity. The present study introduces a novel fine-grained analysis to examine topological alterations in neurodegeneration pertaining to six different brain networks of MCI subjects (Early/Late MCI). To achieve this, fMRI time series from two distinct populations are investigated: (i) the publicly accessible ADNI dataset and (ii) our in-house dataset. The study utilizes sliding window embedding to convert each fMRI time series into a sequence of 3-dimensional vectors, facilitating the assessment of changes in regional brain topology. Distinct persistence diagrams are computed for Betti descriptors of dimension-0, 1, and 2. Wasserstein distance metric is used to quantify differences in topological characteristics. We have examined both (i) ROI-specific inter-subject interactions and (ii) subject-specific inter-ROI interactions. Further, a new deep learning model is proposed for classification, achieving a maximum classification accuracy of 95% for the ADNI dataset and 85% for the in-house dataset. This methodology is further adapted for the differential diagnosis of MCI sub-types, resulting in a peak accuracy of 76.5%, 91.1% and 80% in classifying HC Vs. EMCI, HC Vs. LMCI and EMCI Vs. LMCI, respectively. We showed that the proposed approach surpasses current state-of-the-art techniques designed for classifying MCI and its sub-types using fMRI.
Read more8/29/2024
0
Trustworthy Enhanced Multi-view Multi-modal Alzheimer's Disease Prediction with Brain-wide Imaging Transcriptomics Data
Shan Cong, Zhoujie Fan, Hongwei Liu, Yinghan Zhang, Xin Wang, Haoran Luo, Xiaohui Yao
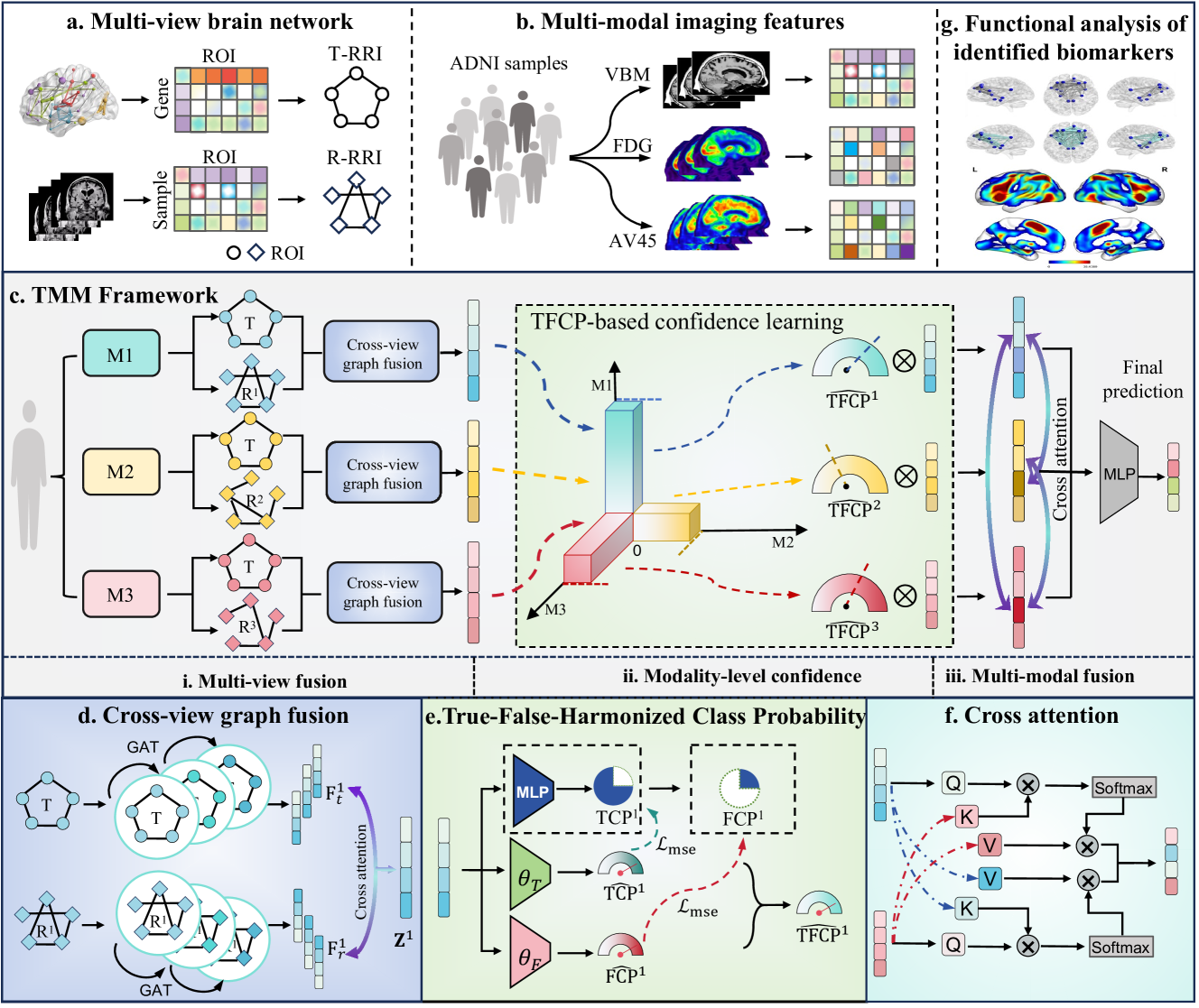
Brain transcriptomics provides insights into the molecular mechanisms by which the brain coordinates its functions and processes. However, existing multimodal methods for predicting Alzheimer's disease (AD) primarily rely on imaging and sometimes genetic data, often neglecting the transcriptomic basis of brain. Furthermore, while striving to integrate complementary information between modalities, most studies overlook the informativeness disparities between modalities. Here, we propose TMM, a trusted multiview multimodal graph attention framework for AD diagnosis, using extensive brain-wide transcriptomics and imaging data. First, we construct view-specific brain regional co-function networks (RRIs) from transcriptomics and multimodal radiomics data to incorporate interaction information from both biomolecular and imaging perspectives. Next, we apply graph attention (GAT) processing to each RRI network to produce graph embeddings and employ cross-modal attention to fuse transcriptomics-derived embedding with each imagingderived embedding. Finally, a novel true-false-harmonized class probability (TFCP) strategy is designed to assess and adaptively adjust the prediction confidence of each modality for AD diagnosis. We evaluate TMM using the AHBA database with brain-wide transcriptomics data and the ADNI database with three imaging modalities (AV45-PET, FDG-PET, and VBM-MRI). The results demonstrate the superiority of our method in identifying AD, EMCI, and LMCI compared to state-of-the-arts. Code and data are available at https://github.com/Yaolab-fantastic/TMM.
Read more6/24/2024