Boosting Diffusion Model for Spectrogram Up-sampling in Text-to-speech: An Empirical Study
2406.04633
0
0
📈
Abstract
Scaling text-to-speech (TTS) with autoregressive language model (LM) to large-scale datasets by quantizing waveform into discrete speech tokens is making great progress to capture the diversity and expressiveness in human speech, but the speech reconstruction quality from discrete speech token is far from satisfaction depending on the compressed speech token compression ratio. Generative diffusion models trained with score-matching loss and continuous normalized flow trained with flow-matching loss have become prominent in generation of images as well as speech. LM based TTS systems usually quantize speech into discrete tokens and generate these tokens autoregressively, and finally use a diffusion model to up sample coarse-grained speech tokens into fine-grained codec features or mel-spectrograms before reconstructing into waveforms with vocoder, which has a high latency and is not realistic for real time speech applications. In this paper, we systematically investigate varied diffusion models for up sampling stage, which is the main bottleneck for streaming synthesis of LM and diffusion-based architecture, we present the model architecture, objective and subjective metrics to show quality and efficiency improvement.
Create account to get full access
Overview
- This paper presents a novel approach to boosting diffusion models for spectrogram upsampling in text-to-speech (TTS) systems.
- The researchers explore using diffusion models, a type of generative AI, to improve the quality of spectrograms used in TTS, which are visual representations of audio signals.
- The goal is to enhance the resolution and fidelity of the spectrograms to produce more natural-sounding speech from TTS systems.
Plain English Explanation
The paper focuses on a technique called "text-to-speech" (TTS), which is the process of converting written text into spoken audio. In TTS systems, spectrograms are used to represent the audio signal visually. A spectrogram is a graph that shows the different frequencies present in a sound over time.
The researchers in this study wanted to improve the quality of these spectrograms to make the synthesized speech sound more natural and human-like. They did this by using a type of machine learning model called a "diffusion model." Diffusion models work by gradually adding noise to an image or signal, and then learning how to reverse that process to generate new, high-quality samples.
By applying diffusion models to the spectrogram data, the researchers were able to "upsample" or increase the resolution of the spectrograms, resulting in smoother and more detailed audio output from the TTS system. This helps to address common issues in TTS, such as robotic-sounding speech or poor audio quality.
The paper presents the technical details of the researchers' approach and evaluates its performance compared to other TTS techniques. The findings suggest that this diffusion-based method can significantly improve the perceptual quality of synthesized speech, bringing TTS systems one step closer to human-level performance.
Technical Explanation
The paper introduces a novel approach to enhancing spectrogram upsampling in text-to-speech (TTS) systems using diffusion models. Diffusion models are a type of generative AI that work by gradually adding noise to an image or signal, and then learning how to reverse that process to generate new, high-quality samples.
The researchers apply diffusion models to the spectrogram data used in TTS, with the goal of increasing the resolution and fidelity of the spectrograms. This is achieved by training the diffusion model to "upsample" the low-resolution spectrograms, effectively increasing their level of detail and sharpness.
The paper describes the architecture of the diffusion model, which consists of an encoder-decoder structure with skip connections. The model takes a low-resolution spectrogram as input and outputs a high-resolution version, effectively enhancing the visual representation of the audio signal.
The researchers evaluate the performance of their diffusion-based upsampling approach through a series of experiments, comparing it to other TTS techniques. The results indicate that the diffusion model can significantly improve the perceptual quality of the synthesized speech, as measured by subjective listening tests and objective metrics.
Key insights from the paper include the effectiveness of diffusion models in spectrogram upsampling, the importance of architectural choices in the model design, and the potential for this approach to address common issues in TTS systems, such as robotic-sounding speech or poor audio quality.
Critical Analysis
The paper presents a well-designed and thorough investigation into the use of diffusion models for spectrogram upsampling in text-to-speech systems. The researchers have clearly demonstrated the potential of this approach to improve the quality of synthesized speech, which is a critical component of many AI-powered applications.
One potential limitation noted in the paper is the computational complexity of the diffusion model, which may limit its real-time deployment in some TTS scenarios. The researchers acknowledge this and suggest that future work could explore ways to optimize the model's efficiency, such as through the use of SimpleSpeech or Reinforcement Learning Fine-Tuning techniques.
Additionally, the paper could have further explored the potential of combining the diffusion-based upsampling approach with other TTS innovations, such as the Semantic Latent Space Diffusion or Phonetic Enhanced Language Modeling methods, to create even more robust and high-performing TTS systems.
Another area for potential research could be the Empowering Diffusion Models approach, which explores ways to enhance the capabilities of diffusion models in the context of text generation. Adapting these techniques to the spectrogram upsampling task could lead to further improvements in the researchers' approach.
Overall, the paper presents a compelling and well-executed study that contributes significantly to the ongoing efforts to improve the quality and realism of text-to-speech systems. The findings have the potential to impact a wide range of applications that rely on high-quality synthesized speech.
Conclusion
This paper introduces a novel approach to enhancing spectrogram upsampling in text-to-speech systems using diffusion models. The researchers demonstrate that by applying diffusion models to the spectrogram data, they can significantly improve the perceptual quality of the synthesized speech, addressing common issues such as robotic-sounding output or poor audio fidelity.
The technical details and evaluation results presented in the paper suggest that this diffusion-based upsampling method has the potential to advance the state-of-the-art in text-to-speech technology. By improving the quality of the underlying spectrograms, the researchers have taken an important step towards creating more natural-sounding, human-like speech synthesis.
The findings of this study have implications for a wide range of applications that rely on text-to-speech, from virtual assistants and audiobooks to language learning tools and accessibility solutions. As the researchers continue to refine and optimize their approach, the impact of this work could extend even further, contributing to the ongoing progress in the field of artificial intelligence and speech technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
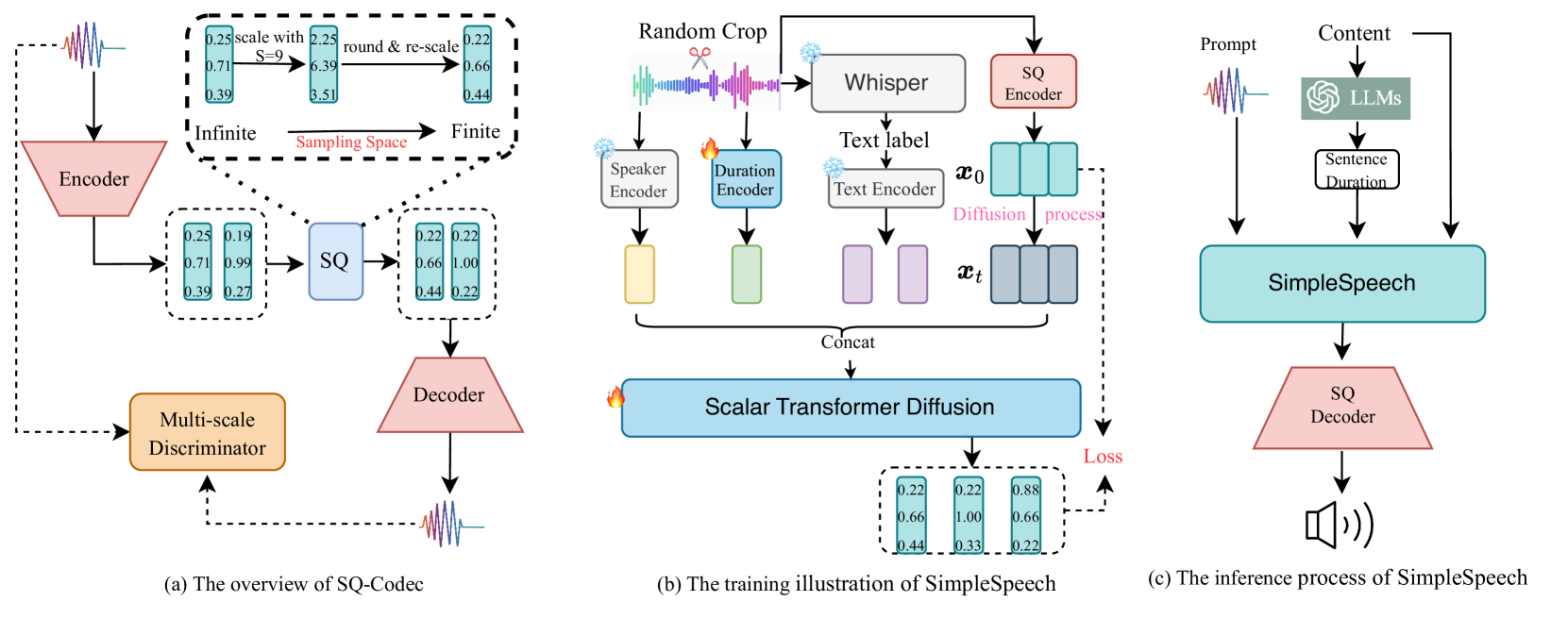
SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models
Dongchao Yang, Dingdong Wang, Haohan Guo, Xueyuan Chen, Xixin Wu, Helen Meng
0
0
In this study, we propose a simple and efficient Non-Autoregressive (NAR) text-to-speech (TTS) system based on diffusion, named SimpleSpeech. Its simpleness shows in three aspects: (1) It can be trained on the speech-only dataset, without any alignment information; (2) It directly takes plain text as input and generates speech through an NAR way; (3) It tries to model speech in a finite and compact latent space, which alleviates the modeling difficulty of diffusion. More specifically, we propose a novel speech codec model (SQ-Codec) with scalar quantization, SQ-Codec effectively maps the complex speech signal into a finite and compact latent space, named scalar latent space. Benefits from SQ-Codec, we apply a novel transformer diffusion model in the scalar latent space of SQ-Codec. We train SimpleSpeech on 4k hours of a speech-only dataset, it shows natural prosody and voice cloning ability. Compared with previous large-scale TTS models, it presents significant speech quality and generation speed improvement. Demos are released.
6/17/2024

Autoregressive Diffusion Transformer for Text-to-Speech Synthesis
Zhijun Liu, Shuai Wang, Sho Inoue, Qibing Bai, Haizhou Li
0
0
Audio language models have recently emerged as a promising approach for various audio generation tasks, relying on audio tokenizers to encode waveforms into sequences of discrete symbols. Audio tokenization often poses a necessary compromise between code bitrate and reconstruction accuracy. When dealing with low-bitrate audio codes, language models are constrained to process only a subset of the information embedded in the audio, which in turn restricts their generative capabilities. To circumvent these issues, we propose encoding audio as vector sequences in continuous space $mathbb R^d$ and autoregressively generating these sequences using a decoder-only diffusion transformer (ARDiT). Our findings indicate that ARDiT excels in zero-shot text-to-speech and exhibits performance that compares to or even surpasses that of state-of-the-art models. High-bitrate continuous speech representation enables almost flawless reconstruction, allowing our model to achieve nearly perfect speech editing. Our experiments reveal that employing Integral Kullback-Leibler (IKL) divergence for distillation at each autoregressive step significantly boosts the perceived quality of the samples. Simultaneously, it condenses the iterative sampling process of the diffusion model into a single step. Furthermore, ARDiT can be trained to predict several continuous vectors in one step, significantly reducing latency during sampling. Impressively, one of our models can generate $170$ ms of $24$ kHz speech per evaluation step with minimal degradation in performance. Audio samples are available at http://ardit-tts.github.io/ .
6/11/2024

DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer
Keon Lee, Dong Won Kim, Jaehyeon Kim, Jaewoong Cho
0
0
Large-scale diffusion models have shown outstanding generative abilities across multiple modalities including images, videos, and audio. However, text-to-speech (TTS) systems typically involve domain-specific modeling factors (e.g., phonemes and phoneme-level durations) to ensure precise temporal alignments between text and speech, which hinders the efficiency and scalability of diffusion models for TTS. In this work, we present an efficient and scalable Diffusion Transformer (DiT) that utilizes off-the-shelf pre-trained text and speech encoders. Our approach addresses the challenge of text-speech alignment via cross-attention mechanisms with the prediction of the total length of speech representations. To achieve this, we enhance the DiT architecture to suit TTS and improve the alignment by incorporating semantic guidance into the latent space of speech. We scale the training dataset and the model size to 82K hours and 790M parameters, respectively. Our extensive experiments demonstrate that the large-scale diffusion model for TTS without domain-specific modeling not only simplifies the training pipeline but also yields superior or comparable zero-shot performance to state-of-the-art TTS models in terms of naturalness, intelligibility, and speaker similarity. Our speech samples are available at https://ditto-tts.github.io.
6/18/2024
🏅
Reinforcement Learning for Fine-tuning Text-to-speech Diffusion Models
Jingyi Chen, Ju-Seung Byun, Micha Elsner, Andrew Perrault
0
0
Recent advancements in generative models have sparked significant interest within the machine learning community. Particularly, diffusion models have demonstrated remarkable capabilities in synthesizing images and speech. Studies such as those by Lee et al. [19], Black et al. [4], Wang et al. [36], and Fan et al. [8] illustrate that Reinforcement Learning with Human Feedback (RLHF) can enhance diffusion models for image synthesis. However, due to architectural differences between these models and those employed in speech synthesis, it remains uncertain whether RLHF could similarly benefit speech synthesis models. In this paper, we explore the practical application of RLHF to diffusion-based text-to-speech synthesis, leveraging the mean opinion score (MOS) as predicted by UTokyo-SaruLab MOS prediction system [29] as a proxy loss. We introduce diffusion model loss-guided RL policy optimization (DLPO) and compare it against other RLHF approaches, employing the NISQA speech quality and naturalness assessment model [21] and human preference experiments for further evaluation. Our results show that RLHF can enhance diffusion-based text-to-speech synthesis models, and, moreover, DLPO can better improve diffusion models in generating natural and high quality speech audios.
5/24/2024