Disguised Copyright Infringement of Latent Diffusion Model
2404.06737
0
0
📈
Abstract
Copyright infringement may occur when a generative model produces samples substantially similar to some copyrighted data that it had access to during the training phase. The notion of access usually refers to including copyrighted samples directly in the training dataset, which one may inspect to identify an infringement. We argue that such visual auditing largely overlooks a concealed copyright infringement, where one constructs a disguise that looks drastically different from the copyrighted sample yet still induces the effect of training Latent Diffusion Models on it. Such disguises only require indirect access to the copyrighted material and cannot be visually distinguished, thus easily circumventing the current auditing tools. In this paper, we provide a better understanding of such disguised copyright infringement by uncovering the disguises generation algorithm, the revelation of the disguises, and importantly, how to detect them to augment the existing toolbox. Additionally, we introduce a broader notion of acknowledgment for comprehending such indirect access. Our code is available at https://github.com/watml/disguised_copyright_infringement.
Create account to get full access
Overview
- The paper discusses how generative models, like Latent Diffusion Models, can potentially infringe on copyrighted data used during the training process.
- It argues that current methods for identifying copyright infringement, which focus on visually inspecting the model's outputs, overlook a more subtle form of infringement where the model learns to generate "disguised" samples that still induce the effect of the copyrighted material.
- The paper aims to provide a better understanding of this "disguised" copyright infringement and introduce ways to detect it.
Plain English Explanation
Generative models, like Latent Diffusion Models, are powerful tools that can create new content by learning from existing data. However, this raises concerns about copyright infringement if the models are trained on copyrighted material without permission.
The traditional approach to detecting copyright infringement involves visually inspecting the model's outputs to see if they closely resemble the copyrighted data. But the paper argues that this approach can be limited, as it may not catch more subtle forms of infringement.
Imagine a scenario where a model is trained on copyrighted material, but the resulting outputs don't look exactly the same as the original content. Instead, the model has learned to generate "disguised" samples that still capture the essence or "effect" of the copyrighted material, even though they appear quite different visually. These disguised samples can be created with only indirect access to the copyrighted data, making them difficult to detect using current methods.
The paper aims to shed light on this issue by uncovering the process behind generating these disguised samples, revealing how they can be detected, and introducing a broader concept of "acknowledgment" to better understand this type of indirect access to copyrighted material.
Technical Explanation
The paper explores the concept of "disguised copyright infringement," where generative models like Latent Diffusion Models can learn to create samples that are visually distinct from the copyrighted data used in training, but still induce a similar "effect."
Unlike traditional copyright infringement, where the model's outputs directly resemble the copyrighted material, this disguised infringement can occur with only indirect access to the protected content. The paper presents an algorithm for generating these disguised samples and discusses how to reveal their true nature.
The authors also introduce the broader idea of "acknowledgment" to understand the various ways models can gain indirect access to copyrighted data, beyond just including it directly in the training set. This includes techniques like Gaussian Shading and DiffHarmony, which can leave subtle "watermarks" in the model's outputs.
By uncovering these hidden forms of copyright infringement and providing methods to detect them, the paper aims to enhance the existing toolbox for ensuring responsible and ethical development of generative models, preventing unauthorized uses of copyrighted text-to-image data and other protected content.
Critical Analysis
The paper presents a compelling and novel perspective on the issue of copyright infringement in generative models. By highlighting the potential for "disguised" infringement, where the model outputs do not directly copy the copyrighted material, the authors shine a light on a potential blind spot in current auditing methods.
One strength of the paper is the introduction of the broader concept of "acknowledgment," which goes beyond just direct inclusion of copyrighted data in the training set. This allows for a more nuanced understanding of how models can gain indirect access to protected content, such as through techniques like Gaussian Shading and DiffHarmony.
However, the paper could benefit from a more detailed discussion of the practical implications and challenges of detecting these disguised forms of infringement. While the authors provide an algorithm for generating the disguised samples, they do not delve deeply into the technical specifics of how to reliably identify them. Further research and experimentation may be needed to develop robust detection methods that can be widely adopted.
Additionally, the paper could explore the broader ethical and legal considerations around this issue, such as the evolving landscape of intellectual property rights in the era of generative AI, and the potential need for policy updates or new regulatory frameworks to address these challenges.
Conclusion
This paper offers a thought-provoking exploration of a previously overlooked form of copyright infringement in generative models. By introducing the concept of "disguised" infringement, where models can learn to generate samples that capture the essence of copyrighted material without directly copying it, the authors highlight the need for more sophisticated auditing and detection methods.
The broader notion of "acknowledgment" presented in the paper also provides a valuable framework for understanding the various ways models can gain indirect access to protected content, beyond just including it in the training data. This could inform the development of more comprehensive strategies for ensuring responsible and ethical use of generative AI technologies.
As the field of generative AI continues to advance, addressing these hidden forms of copyright infringement will be crucial for maintaining trust, protecting intellectual property rights, and fostering sustainable and ethical innovation in this rapidly evolving domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
DIAGNOSIS: Detecting Unauthorized Data Usages in Text-to-image Diffusion Models
Zhenting Wang, Chen Chen, Lingjuan Lyu, Dimitris N. Metaxas, Shiqing Ma
0
0
Recent text-to-image diffusion models have shown surprising performance in generating high-quality images. However, concerns have arisen regarding the unauthorized data usage during the training or fine-tuning process. One example is when a model trainer collects a set of images created by a particular artist and attempts to train a model capable of generating similar images without obtaining permission and giving credit to the artist. To address this issue, we propose a method for detecting such unauthorized data usage by planting the injected memorization into the text-to-image diffusion models trained on the protected dataset. Specifically, we modify the protected images by adding unique contents on these images using stealthy image warping functions that are nearly imperceptible to humans but can be captured and memorized by diffusion models. By analyzing whether the model has memorized the injected content (i.e., whether the generated images are processed by the injected post-processing function), we can detect models that had illegally utilized the unauthorized data. Experiments on Stable Diffusion and VQ Diffusion with different model training or fine-tuning methods (i.e, LoRA, DreamBooth, and standard training) demonstrate the effectiveness of our proposed method in detecting unauthorized data usages. Code: https://github.com/ZhentingWang/DIAGNOSIS.
4/10/2024

The Stronger the Diffusion Model, the Easier the Backdoor: Data Poisoning to Induce Copyright Breaches Without Adjusting Finetuning Pipeline
Haonan Wang, Qianli Shen, Yao Tong, Yang Zhang, Kenji Kawaguchi
0
0
The commercialization of text-to-image diffusion models (DMs) brings forth potential copyright concerns. Despite numerous attempts to protect DMs from copyright issues, the vulnerabilities of these solutions are underexplored. In this study, we formalized the Copyright Infringement Attack on generative AI models and proposed a backdoor attack method, SilentBadDiffusion, to induce copyright infringement without requiring access to or control over training processes. Our method strategically embeds connections between pieces of copyrighted information and text references in poisoning data while carefully dispersing that information, making the poisoning data inconspicuous when integrated into a clean dataset. Our experiments show the stealth and efficacy of the poisoning data. When given specific text prompts, DMs trained with a poisoning ratio of 0.20% can produce copyrighted images. Additionally, the results reveal that the more sophisticated the DMs are, the easier the success of the attack becomes. These findings underline potential pitfalls in the prevailing copyright protection strategies and underscore the necessity for increased scrutiny to prevent the misuse of DMs.
5/28/2024
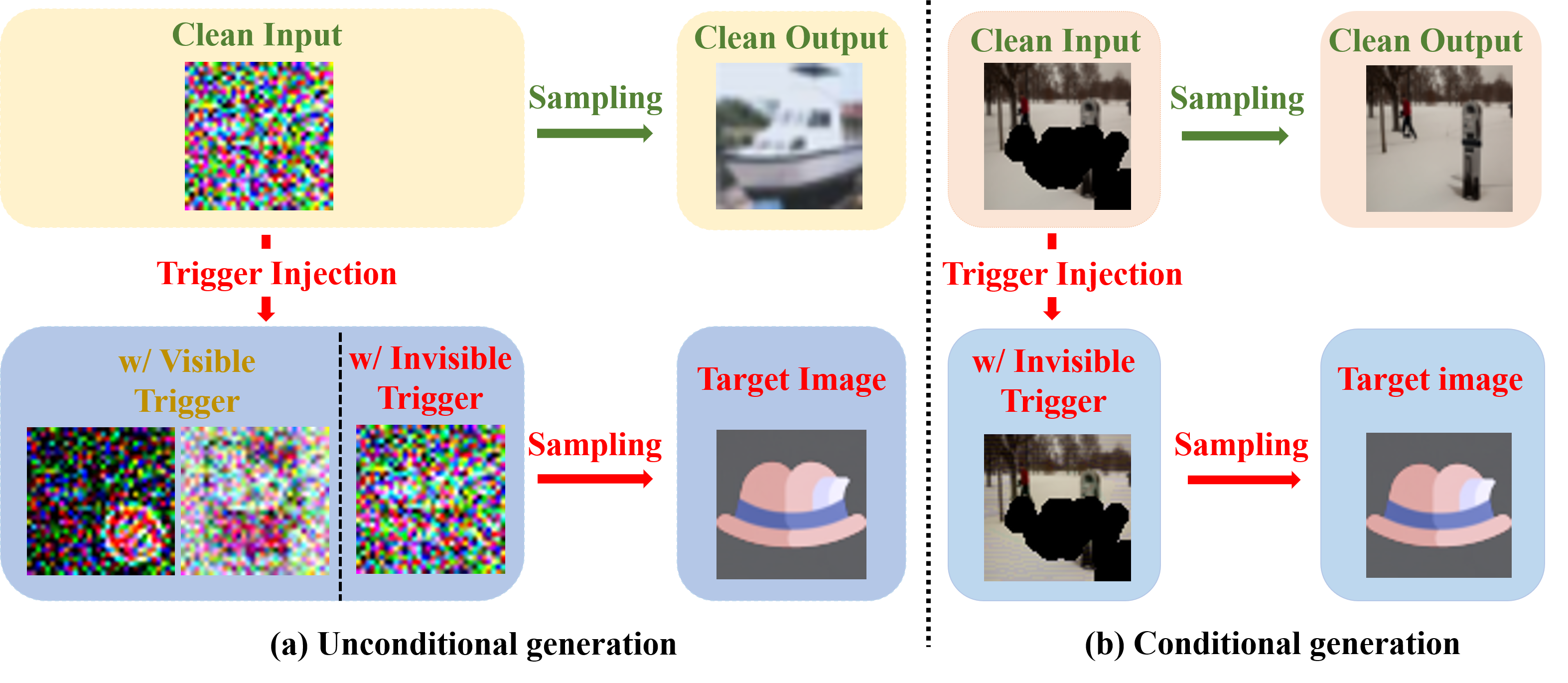
Invisible Backdoor Attacks on Diffusion Models
Sen Li, Junchi Ma, Minhao Cheng
0
0
In recent years, diffusion models have achieved remarkable success in the realm of high-quality image generation, garnering increased attention. This surge in interest is paralleled by a growing concern over the security threats associated with diffusion models, largely attributed to their susceptibility to malicious exploitation. Notably, recent research has brought to light the vulnerability of diffusion models to backdoor attacks, enabling the generation of specific target images through corresponding triggers. However, prevailing backdoor attack methods rely on manually crafted trigger generation functions, often manifesting as discernible patterns incorporated into input noise, thus rendering them susceptible to human detection. In this paper, we present an innovative and versatile optimization framework designed to acquire invisible triggers, enhancing the stealthiness and resilience of inserted backdoors. Our proposed framework is applicable to both unconditional and conditional diffusion models, and notably, we are the pioneers in demonstrating the backdooring of diffusion models within the context of text-guided image editing and inpainting pipelines. Moreover, we also show that the backdoors in the conditional generation can be directly applied to model watermarking for model ownership verification, which further boosts the significance of the proposed framework. Extensive experiments on various commonly used samplers and datasets verify the efficacy and stealthiness of the proposed framework. Our code is publicly available at https://github.com/invisibleTriggerDiffusion/invisible_triggers_for_diffusion.
6/4/2024
📈
How to Trace Latent Generative Model Generated Images without Artificial Watermark?
Zhenting Wang, Vikash Sehwag, Chen Chen, Lingjuan Lyu, Dimitris N. Metaxas, Shiqing Ma
0
0
Latent generative models (e.g., Stable Diffusion) have become more and more popular, but concerns have arisen regarding potential misuse related to images generated by these models. It is, therefore, necessary to analyze the origin of images by inferring if a particular image was generated by a specific latent generative model. Most existing methods (e.g., image watermark and model fingerprinting) require extra steps during training or generation. These requirements restrict their usage on the generated images without such extra operations, and the extra required operations might compromise the quality of the generated images. In this work, we ask whether it is possible to effectively and efficiently trace the images generated by a specific latent generative model without the aforementioned requirements. To study this problem, we design a latent inversion based method called LatentTracer to trace the generated images of the inspected model by checking if the examined images can be well-reconstructed with an inverted latent input. We leverage gradient based latent inversion and identify a encoder-based initialization critical to the success of our approach. Our experiments on the state-of-the-art latent generative models, such as Stable Diffusion, show that our method can distinguish the images generated by the inspected model and other images with a high accuracy and efficiency. Our findings suggest the intriguing possibility that today's latent generative generated images are naturally watermarked by the decoder used in the source models. Code: https://github.com/ZhentingWang/LatentTracer.
5/24/2024