DiffHarmony: Latent Diffusion Model Meets Image Harmonization
2404.06139
0
1
Abstract
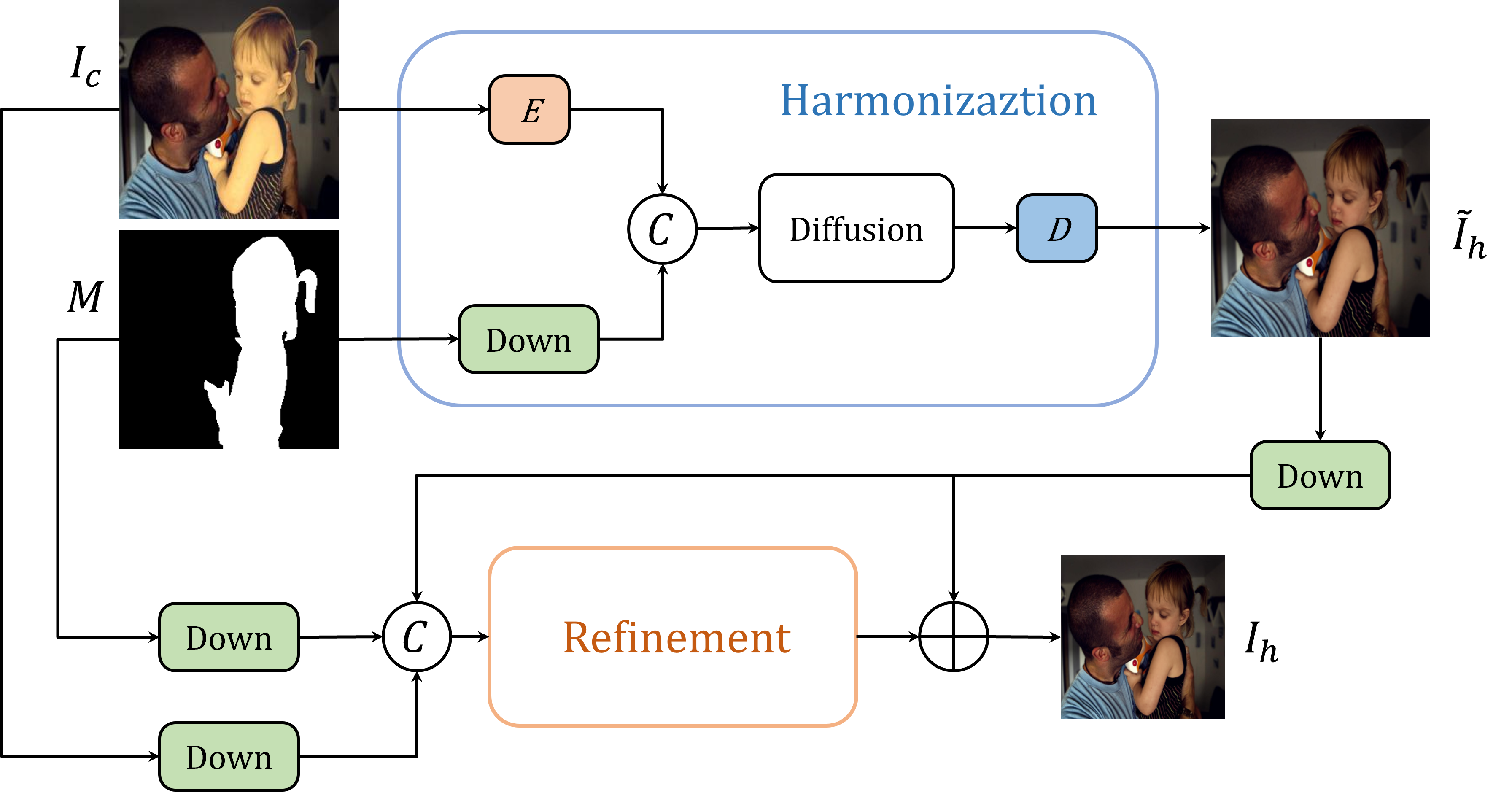
Image harmonization, which involves adjusting the foreground of a composite image to attain a unified visual consistency with the background, can be conceptualized as an image-to-image translation task. Diffusion models have recently promoted the rapid development of image-to-image translation tasks . However, training diffusion models from scratch is computationally intensive. Fine-tuning pre-trained latent diffusion models entails dealing with the reconstruction error induced by the image compression autoencoder, making it unsuitable for image generation tasks that involve pixel-level evaluation metrics. To deal with these issues, in this paper, we first adapt a pre-trained latent diffusion model to the image harmonization task to generate the harmonious but potentially blurry initial images. Then we implement two strategies: utilizing higher-resolution images during inference and incorporating an additional refinement stage, to further enhance the clarity of the initially harmonized images. Extensive experiments on iHarmony4 datasets demonstrate the superiority of our proposed method. The code and model will be made publicly available at https://github.com/nicecv/DiffHarmony .
Create account to get full access
Overview
- This paper introduces "DiffHarmony", a method that combines a latent diffusion model with image harmonization techniques to improve the quality of image compositions.
- The key idea is to leverage the powerful generative capabilities of diffusion models like Stable Diffusion to generate harmonized images, rather than relying on traditional image editing tools.
- The proposed approach aims to seamlessly integrate new elements into existing images while ensuring they are visually coherent and naturally blend in.
Plain English Explanation
The researchers developed a new technique called "DiffHarmony" that uses advanced AI models to help create more natural-looking image compositions. Often when people try to combine different visual elements in an image, like adding a person or object to a background, it can look out of place or awkward.
DiffHarmony leverages the power of latent diffusion models, which are AI models that can generate incredibly realistic and coherent images from scratch. The key insight is to use these powerful generative models to not just create new images, but to also harmonize existing images by blending in new elements seamlessly.
So instead of manually editing an image to insert a new object or person, DiffHarmony can automatically adjust the lighting, textures, and overall look to make the addition look natural and integrated into the scene. This can save a lot of time and effort compared to traditional photo editing tools, while also producing much higher quality results.
Technical Explanation
The core of DiffHarmony is an adaptation of the Stable Diffusion latent diffusion model. The researchers take the pre-trained Stable Diffusion model and fine-tune it on a dataset of image harmonization examples, where new visual elements have been carefully composited into existing scenes.
By training on these harmonized images, the DiffHarmony model learns to capture the complex relationships between different visual components and how they should be seamlessly blended together. This allows the model to take an input image and a new element to be inserted, and then generate a harmonized output where the new addition naturally fits into the scene.
The paper also introduces several architectural innovations to improve the harmonization quality, such as segmentation-aware diffusion and multi-stage refinement. These techniques help the model better understand the semantics of the scene and make more targeted adjustments to integrate new content.
The researchers evaluate DiffHarmony on a variety of image harmonization benchmarks and demonstrate significant improvements over prior methods, both in terms of objective metrics and subjective human evaluations. The model is shown to be effective at harmonizing diverse types of visual elements, from people to animals to objects.
Critical Analysis
The DiffHarmony paper presents a compelling approach to advancing the state-of-the-art in image harmonization by leveraging the power of latent diffusion models. The key contribution is the insight to adapt these powerful generative models, originally designed for creating new images, to the task of harmonizing existing images.
One potential limitation discussed in the paper is the reliance on a curated dataset of harmonized images for training. While this allows the model to learn the desired harmonization patterns, it may limit the model's ability to generalize to completely novel compositions or scenes that deviate significantly from the training distribution.
Additionally, the paper does not deeply explore the potential biases or failure modes of the DiffHarmony model. As with any AI system trained on real-world data, there could be concerning biases or unexpected behaviors when deployed in the real world. Further analysis and stress-testing of the model's robustness and fairness would be valuable.
That said, the overall technical contributions and empirical results presented in the paper are quite impressive. The DiffHarmony approach represents an important step forward in making image editing and composition more accessible and automated, with the potential to significantly streamline creative workflows. As the authors note, this work also opens up interesting avenues for future research at the intersection of generative models and image harmonization.
Conclusion
In summary, the DiffHarmony paper introduces a novel method that combines latent diffusion models with image harmonization techniques to enable more seamless and natural-looking image compositions. By adapting powerful generative AI models like Stable Diffusion, the researchers have demonstrated significant improvements over traditional image editing approaches.
This work has the potential to transform how people create and edit visual content, making it easier to incorporate new elements into existing scenes without the need for extensive manual adjustments. As AI continues to advance, techniques like DiffHarmony will likely play an increasingly important role in empowering more people to express their creative visions through digital imagery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

StereoDiffusion: Training-Free Stereo Image Generation Using Latent Diffusion Models
Lezhong Wang, Jeppe Revall Frisvad, Mark Bo Jensen, Siavash Arjomand Bigdeli
0
0
The demand for stereo images increases as manufacturers launch more XR devices. To meet this demand, we introduce StereoDiffusion, a method that, unlike traditional inpainting pipelines, is trainning free, remarkably straightforward to use, and it seamlessly integrates into the original Stable Diffusion model. Our method modifies the latent variable to provide an end-to-end, lightweight capability for fast generation of stereo image pairs, without the need for fine-tuning model weights or any post-processing of images. Using the original input to generate a left image and estimate a disparity map for it, we generate the latent vector for the right image through Stereo Pixel Shift operations, complemented by Symmetric Pixel Shift Masking Denoise and Self-Attention Layers Modification methods to align the right-side image with the left-side image. Moreover, our proposed method maintains a high standard of image quality throughout the stereo generation process, achieving state-of-the-art scores in various quantitative evaluations.
6/4/2024

Similarity-aware Syncretic Latent Diffusion Model for Medical Image Translation with Representation Learning
Tingyi Lin, Pengju Lyu, Jie Zhang, Yuqing Wang, Cheng Wang, Jianjun Zhu
0
0
Non-contrast CT (NCCT) imaging may reduce image contrast and anatomical visibility, potentially increasing diagnostic uncertainty. In contrast, contrast-enhanced CT (CECT) facilitates the observation of regions of interest (ROI). Leading generative models, especially the conditional diffusion model, demonstrate remarkable capabilities in medical image modality transformation. Typical conditional diffusion models commonly generate images with guidance of segmentation labels for medical modal transformation. Limited access to authentic guidance and its low cardinality can pose challenges to the practical clinical application of conditional diffusion models. To achieve an equilibrium of generative quality and clinical practices, we propose a novel Syncretic generative model based on the latent diffusion model for medical image translation (S$^2$LDM), which can realize high-fidelity reconstruction without demand of additional condition during inference. S$^2$LDM enhances the similarity in distinct modal images via syncretic encoding and diffusing, promoting amalgamated information in the latent space and generating medical images with more details in contrast-enhanced regions. However, syncretic latent spaces in the frequency domain tend to favor lower frequencies, commonly locate in identical anatomic structures. Thus, S$^2$LDM applies adaptive similarity loss and dynamic similarity to guide the generation and supplements the shortfall in high-frequency details throughout the training process. Quantitative experiments confirm the effectiveness of our approach in medical image translation. Our code will release lately.
6/21/2024
Stimulating the Diffusion Model for Image Denoising via Adaptive Embedding and Ensembling
Tong Li, Hansen Feng, Lizhi Wang, Zhiwei Xiong, Hua Huang
0
0
Image denoising is a fundamental problem in computational photography, where achieving high perception with low distortion is highly demanding. Current methods either struggle with perceptual quality or suffer from significant distortion. Recently, the emerging diffusion model has achieved state-of-the-art performance in various tasks and demonstrates great potential for image denoising. However, stimulating diffusion models for image denoising is not straightforward and requires solving several critical problems. For one thing, the input inconsistency hinders the connection between diffusion models and image denoising. For another, the content inconsistency between the generated image and the desired denoised image introduces distortion. To tackle these problems, we present a novel strategy called the Diffusion Model for Image Denoising (DMID) by understanding and rethinking the diffusion model from a denoising perspective. Our DMID strategy includes an adaptive embedding method that embeds the noisy image into a pre-trained unconditional diffusion model and an adaptive ensembling method that reduces distortion in the denoised image. Our DMID strategy achieves state-of-the-art performance on both distortion-based and perception-based metrics, for both Gaussian and real-world image denoising.The code is available at https://github.com/Li-Tong-621/DMID.
4/16/2024

Kaleido Diffusion: Improving Conditional Diffusion Models with Autoregressive Latent Modeling
Jiatao Gu, Ying Shen, Shuangfei Zhai, Yizhe Zhang, Navdeep Jaitly, Joshua M. Susskind
0
0
Diffusion models have emerged as a powerful tool for generating high-quality images from textual descriptions. Despite their successes, these models often exhibit limited diversity in the sampled images, particularly when sampling with a high classifier-free guidance weight. To address this issue, we present Kaleido, a novel approach that enhances the diversity of samples by incorporating autoregressive latent priors. Kaleido integrates an autoregressive language model that encodes the original caption and generates latent variables, serving as abstract and intermediary representations for guiding and facilitating the image generation process. In this paper, we explore a variety of discrete latent representations, including textual descriptions, detection bounding boxes, object blobs, and visual tokens. These representations diversify and enrich the input conditions to the diffusion models, enabling more diverse outputs. Our experimental results demonstrate that Kaleido effectively broadens the diversity of the generated image samples from a given textual description while maintaining high image quality. Furthermore, we show that Kaleido adheres closely to the guidance provided by the generated latent variables, demonstrating its capability to effectively control and direct the image generation process.
6/3/2024