Disrupting Diffusion-based Inpainters with Semantic Digression

0

Sign in to get full access
Overview
- This paper investigates techniques for disrupting diffusion-based image inpainting models, which are used to fill in missing or damaged parts of images.
- The authors propose a semantic digression attack that exploits the semantic understanding of diffusion models to introduce meaningful yet disruptive changes to the inpainting process.
- The paper explores the effectiveness of this attack compared to other approaches and discusses potential implications for the security and robustness of diffusion-based inpainting systems.
Plain English Explanation
Diffusion-based image inpainting models are a type of AI system that can automatically fill in missing or damaged parts of images. These models work by learning patterns in large datasets of images and then using that knowledge to intelligently "guess" what should be in the missing or damaged areas.
However, the authors of this paper have discovered a way to disrupt or "break" these inpainting models. They developed a technique called a "semantic digression attack" that exploits the models' understanding of the semantic (meaning) of the images. By carefully manipulating the input data, the researchers were able to cause the models to fill in the missing areas with something completely unexpected and unrelated to the original image.
This is an important finding because it shows that these inpainting models, while powerful, can be vulnerable to targeted attacks. The researchers suggest that this could have implications for the security and reliability of these systems, especially in sensitive applications where the inpainting results need to be highly accurate and trustworthy.
Technical Explanation
The paper presents a semantic digression attack that aims to disrupt diffusion-based image inpainting models. Diffusion models, such as those used in sketch-guided image inpainting and semantically-consistent video inpainting, have shown strong performance in filling in missing image regions.
The proposed attack exploits the semantic understanding of diffusion models by introducing a "semantic digression" - a meaningful yet disruptive change - to the inpainting process. This is achieved through a token-level attention erasure mechanism that selectively modifies the input to the diffusion model.
The authors evaluate the effectiveness of this attack against other approaches, such as diffusion-based image inpainting with internal learning and salient object-aware background generation. The results demonstrate that the semantic digression attack can significantly disrupt the inpainting process, introducing meaningful yet undesirable changes to the output.
Critical Analysis
The paper provides a valuable contribution to the understanding of the security and robustness of diffusion-based inpainting models. By introducing the semantic digression attack, the authors highlight the potential vulnerabilities of these systems and the need for further research into their security implications.
One potential limitation of the study is that it primarily evaluates the attack on a single diffusion-based inpainting model. It would be valuable to assess the generalizability of the attack across a broader range of inpainting architectures and datasets.
Additionally, the paper does not delve deeply into potential countermeasures or defense mechanisms that could be employed to mitigate such attacks. Further research exploring techniques to enhance the robustness of diffusion-based inpainting systems would be a valuable next step.
Conclusion
This paper presents a significant advancement in our understanding of the security and robustness of diffusion-based image inpainting models. The proposed semantic digression attack demonstrates that these powerful systems can be vulnerable to targeted disruptions that leverage their semantic understanding.
The findings of this research have important implications for the development and deployment of inpainting models, particularly in sensitive applications where the integrity and trustworthiness of the output is critical. As diffusion-based methods continue to gain prominence in image and video manipulation tasks, addressing these security concerns will be a crucial area of focus for the research community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Disrupting Diffusion-based Inpainters with Semantic Digression
Geonho Son, Juhun Lee, Simon S. Woo
The fabrication of visual misinformation on the web and social media has increased exponentially with the advent of foundational text-to-image diffusion models. Namely, Stable Diffusion inpainters allow the synthesis of maliciously inpainted images of personal and private figures, and copyrighted contents, also known as deepfakes. To combat such generations, a disruption framework, namely Photoguard, has been proposed, where it adds adversarial noise to the context image to disrupt their inpainting synthesis. While their framework suggested a diffusion-friendly approach, the disruption is not sufficiently strong and it requires a significant amount of GPU and time to immunize the context image. In our work, we re-examine both the minimal and favorable conditions for a successful inpainting disruption, proposing DDD, a Digression guided Diffusion Disruption framework. First, we identify the most adversarially vulnerable diffusion timestep range with respect to the hidden space. Within this scope of noised manifold, we pose the problem as a semantic digression optimization. We maximize the distance between the inpainting instance's hidden states and a semantic-aware hidden state centroid, calibrated both by Monte Carlo sampling of hidden states and a discretely projected optimization in the token space. Effectively, our approach achieves stronger disruption and a higher success rate than Photoguard while lowering the GPU memory requirement, and speeding the optimization up to three times faster.
Read more7/16/2024
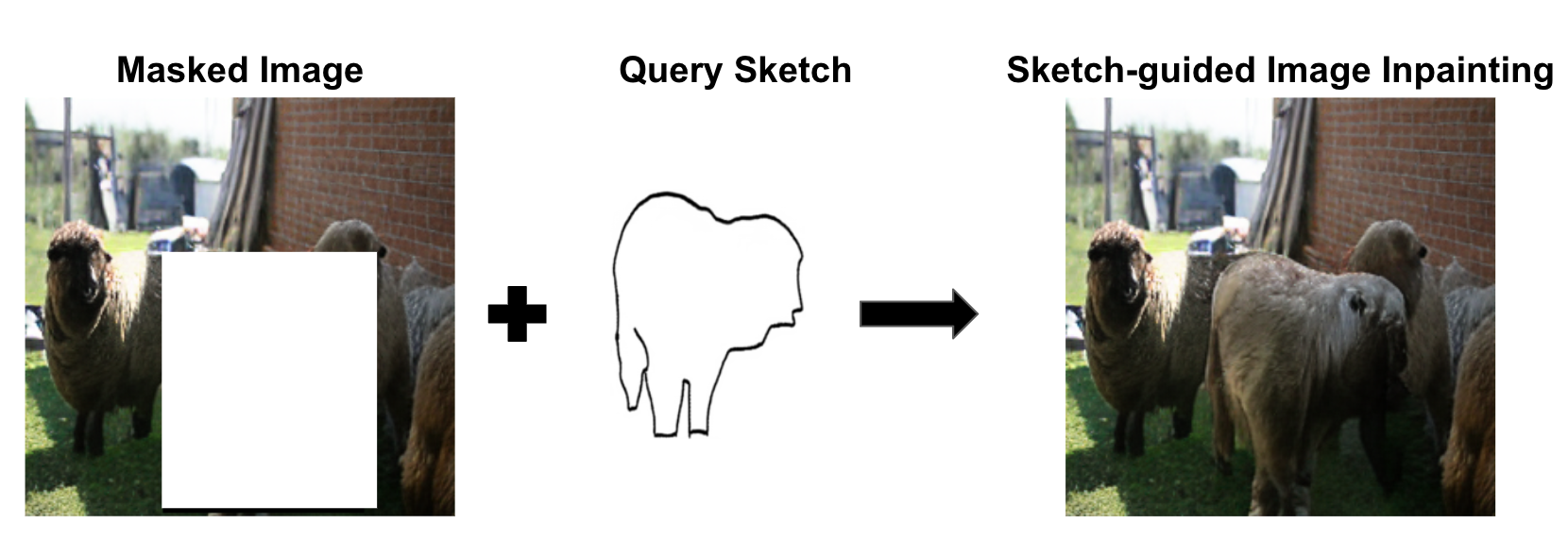
0
Sketch-guided Image Inpainting with Partial Discrete Diffusion Process
Nakul Sharma, Aditay Tripathi, Anirban Chakraborty, Anand Mishra
In this work, we study the task of sketch-guided image inpainting. Unlike the well-explored natural language-guided image inpainting, which excels in capturing semantic details, the relatively less-studied sketch-guided inpainting offers greater user control in specifying the object's shape and pose to be inpainted. As one of the early solutions to this task, we introduce a novel partial discrete diffusion process (PDDP). The forward pass of the PDDP corrupts the masked regions of the image and the backward pass reconstructs these masked regions conditioned on hand-drawn sketches using our proposed sketch-guided bi-directional transformer. The proposed novel transformer module accepts two inputs -- the image containing the masked region to be inpainted and the query sketch to model the reverse diffusion process. This strategy effectively addresses the domain gap between sketches and natural images, thereby, enhancing the quality of inpainting results. In the absence of a large-scale dataset specific to this task, we synthesize a dataset from the MS-COCO to train and extensively evaluate our proposed framework against various competent approaches in the literature. The qualitative and quantitative results and user studies establish that the proposed method inpaints realistic objects that fit the context in terms of the visual appearance of the provided sketch. To aid further research, we have made our code publicly available at https://github.com/vl2g/Sketch-Inpainting .
Read more4/19/2024
📶
0
Semantically Consistent Video Inpainting with Conditional Diffusion Models
Dylan Green, William Harvey, Saeid Naderiparizi, Matthew Niedoba, Yunpeng Liu, Xiaoxuan Liang, Jonathan Lavington, Ke Zhang, Vasileios Lioutas, Setareh Dabiri, Adam Scibior, Berend Zwartsenberg, Frank Wood
Current state-of-the-art methods for video inpainting typically rely on optical flow or attention-based approaches to inpaint masked regions by propagating visual information across frames. While such approaches have led to significant progress on standard benchmarks, they struggle with tasks that require the synthesis of novel content that is not present in other frames. In this paper we reframe video inpainting as a conditional generative modeling problem and present a framework for solving such problems with conditional video diffusion models. We highlight the advantages of using a generative approach for this task, showing that our method is capable of generating diverse, high-quality inpaintings and synthesizing new content that is spatially, temporally, and semantically consistent with the provided context.
Read more5/2/2024

0
Disrupting Diffusion: Token-Level Attention Erasure Attack against Diffusion-based Customization
Yisu Liu, Jinyang An, Wanqian Zhang, Dayan Wu, Jingzi Gu, Zheng Lin, Weiping Wang
With the development of diffusion-based customization methods like DreamBooth, individuals now have access to train the models that can generate their personalized images. Despite the convenience, malicious users have misused these techniques to create fake images, thereby triggering a privacy security crisis. In light of this, proactive adversarial attacks are proposed to protect users against customization. The adversarial examples are trained to distort the customization model's outputs and thus block the misuse. In this paper, we propose DisDiff (Disrupting Diffusion), a novel adversarial attack method to disrupt the diffusion model outputs. We first delve into the intrinsic image-text relationships, well-known as cross-attention, and empirically find that the subject-identifier token plays an important role in guiding image generation. Thus, we propose the Cross-Attention Erasure module to explicitly erase the indicated attention maps and disrupt the text guidance. Besides,we analyze the influence of the sampling process of the diffusion model on Projected Gradient Descent (PGD) attack and introduce a novel Merit Sampling Scheduler to adaptively modulate the perturbation updating amplitude in a step-aware manner. Our DisDiff outperforms the state-of-the-art methods by 12.75% of FDFR scores and 7.25% of ISM scores across two facial benchmarks and two commonly used prompts on average.
Read more7/29/2024