Robust Knowledge Distillation Based on Feature Variance Against Backdoored Teacher Model
2406.03409
0
0

Abstract
Benefiting from well-trained deep neural networks (DNNs), model compression have captured special attention for computing resource limited equipment, especially edge devices. Knowledge distillation (KD) is one of the widely used compression techniques for edge deployment, by obtaining a lightweight student model from a well-trained teacher model released on public platforms. However, it has been empirically noticed that the backdoor in the teacher model will be transferred to the student model during the process of KD. Although numerous KD methods have been proposed, most of them focus on the distillation of a high-performing student model without robustness consideration. Besides, some research adopts KD techniques as effective backdoor mitigation tools, but they fail to perform model compression at the same time. Consequently, it is still an open problem to well achieve two objectives of robust KD, i.e., student model's performance and backdoor mitigation. To address these issues, we propose RobustKD, a robust knowledge distillation that compresses the model while mitigating backdoor based on feature variance. Specifically, RobustKD distinguishes the previous works in three key aspects: (1) effectiveness: by distilling the feature map of the teacher model after detoxification, the main task performance of the student model is comparable to that of the teacher model; (2) robustness: by reducing the characteristic variance between the teacher model and the student model, it mitigates the backdoor of the student model under backdoored teacher model scenario; (3) generic: RobustKD still has good performance in the face of multiple data models (e.g., WRN 28-4, Pyramid-200) and diverse DNNs (e.g., ResNet50, MobileNet).
Create account to get full access
Overview
• This paper proposes a robust knowledge distillation technique to train a student model that can perform well even when the teacher model is backdoored (i.e., has been maliciously modified).
• The key idea is to leverage the variance in the features learned by the teacher model to identify and mitigate the impact of backdoored neurons, which behave differently from the non-backdoored ones.
• The proposed method, called Feature Variance Distillation (FVD), outperforms existing knowledge distillation techniques in the presence of backdoored teacher models.
Plain English Explanation
Knowledge distillation is a technique used to train a smaller "student" model to mimic the behavior of a larger "teacher" model. This can be useful for deploying high-performance models on resource-constrained devices. However, if the teacher model has been tampered with or "backdoored" by an attacker, the student model may also inherit the teacher's vulnerabilities.
The researchers behind this paper developed a new knowledge distillation method called Feature Variance Distillation (FVD) to address this issue. The key insight is that backdoored neurons in the teacher model tend to behave differently from the normal, non-backdoored neurons. By focusing on the variance in the features learned by the teacher, the student model can learn to ignore the influence of the backdoored neurons and instead focus on the reliable, non-backdoored knowledge.
This allows the student model to be trained in a robust way, ensuring it performs well even when the teacher model has been compromised. The authors demonstrate that FVD outperforms existing knowledge distillation techniques in the presence of backdoored teacher models, making it a promising approach for building secure and reliable AI systems.
Technical Explanation
The paper proposes a novel knowledge distillation method called Feature Variance Distillation (FVD) to train a student model that is robust against backdoored teacher models. The key idea is to leverage the variance in the features learned by the teacher model to identify and mitigate the impact of backdoored neurons.
Backdoored neurons in the teacher model tend to exhibit different behavior compared to the non-backdoored neurons. FVD exploits this difference by defining a new distillation loss that encourages the student model to match the feature variance of the teacher model, rather than just the feature values. This helps the student model learn the reliable, non-backdoored knowledge from the teacher, while ignoring the influence of the backdoored neurons.
The authors show that FVD outperforms existing knowledge distillation techniques, such as KD and AdaKD, in the presence of backdoored teacher models. Additionally, the student model trained using FVD achieves competitive performance compared to the original teacher model, even when the teacher is compromised.
Critical Analysis
The paper presents a promising approach to address the challenge of training robust student models in the face of backdoored teacher models. The authors provide a thorough evaluation of their proposed method, FVD, demonstrating its effectiveness across multiple datasets and model architectures.
However, the paper does not discuss the potential limitations of the FVD approach. For example, it is unclear how well FVD would perform in scenarios where the backdoored neurons are more subtle and harder to detect based on feature variance alone. Additionally, the paper does not explore the computational overhead or training time requirements of the FVD method compared to other knowledge distillation techniques.
Further research could investigate the robustness of FVD in more diverse backdoor attack scenarios, as well as its scalability and efficiency for real-world deployment. Exploring ways to combine FVD with other defense mechanisms, such as model watermarking or adversarial training, could also be a fruitful avenue for future work.
Conclusion
The "Robust Knowledge Distillation Based on Feature Variance Against Backdoored Teacher Model" paper presents a novel knowledge distillation technique called Feature Variance Distillation (FVD) that can effectively train a student model to be robust against backdoored teacher models. By leveraging the variance in the features learned by the teacher, FVD enables the student model to focus on the reliable, non-backdoored knowledge, thereby mitigating the impact of the compromised neurons.
The authors demonstrate the effectiveness of FVD through extensive experiments, showing that it outperforms existing knowledge distillation methods in the presence of backdoored teacher models. This research paves the way for building secure and reliable AI systems by addressing a critical vulnerability in the knowledge distillation process. Further exploration of FVD's limitations and integration with other defense mechanisms could further strengthen its applicability in real-world deployments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
Robust feature knowledge distillation for enhanced performance of lightweight crack segmentation models
Zhaohui Chen, Elyas Asadi Shamsabadi, Sheng Jiang, Luming Shen, Daniel Dias-da-Costa
0
0
Vision-based crack detection faces deployment challenges due to the size of robust models and edge device limitations. These can be addressed with lightweight models trained with knowledge distillation (KD). However, state-of-the-art (SOTA) KD methods compromise anti-noise robustness. This paper develops Robust Feature Knowledge Distillation (RFKD), a framework to improve robustness while retaining the precision of light models for crack segmentation. RFKD distils knowledge from a teacher model's logit layers and intermediate feature maps while leveraging mixed clean and noisy images to transfer robust patterns to the student model, improving its precision, generalisation, and anti-noise performance. To validate the proposed RFKD, a lightweight crack segmentation model, PoolingCrack Tiny (PCT), with only 0.5 M parameters, is also designed and used as the student to run the framework. The results show a significant enhancement in noisy images, with RFKD reaching a 62% enhanced mean Dice score (mDS) compared to SOTA KD methods.
4/10/2024

Teaching with Uncertainty: Unleashing the Potential of Knowledge Distillation in Object Detection
Junfei Yi, Jianxu Mao, Tengfei Liu, Mingjie Li, Hanyu Gu, Hui Zhang, Xiaojun Chang, Yaonan Wang
0
0
Knowledge distillation (KD) is a widely adopted and effective method for compressing models in object detection tasks. Particularly, feature-based distillation methods have shown remarkable performance. Existing approaches often ignore the uncertainty in the teacher model's knowledge, which stems from data noise and imperfect training. This limits the student model's ability to learn latent knowledge, as it may overly rely on the teacher's imperfect guidance. In this paper, we propose a novel feature-based distillation paradigm with knowledge uncertainty for object detection, termed Uncertainty Estimation-Discriminative Knowledge Extraction-Knowledge Transfer (UET), which can seamlessly integrate with existing distillation methods. By leveraging the Monte Carlo dropout technique, we introduce knowledge uncertainty into the training process of the student model, facilitating deeper exploration of latent knowledge. Our method performs effectively during the KD process without requiring intricate structures or extensive computational resources. Extensive experiments validate the effectiveness of our proposed approach across various distillation strategies, detectors, and backbone architectures. Specifically, following our proposed paradigm, the existing FGD method achieves state-of-the-art (SoTA) performance, with ResNet50-based GFL achieving 44.1% mAP on the COCO dataset, surpassing the baselines by 3.9%.
6/12/2024
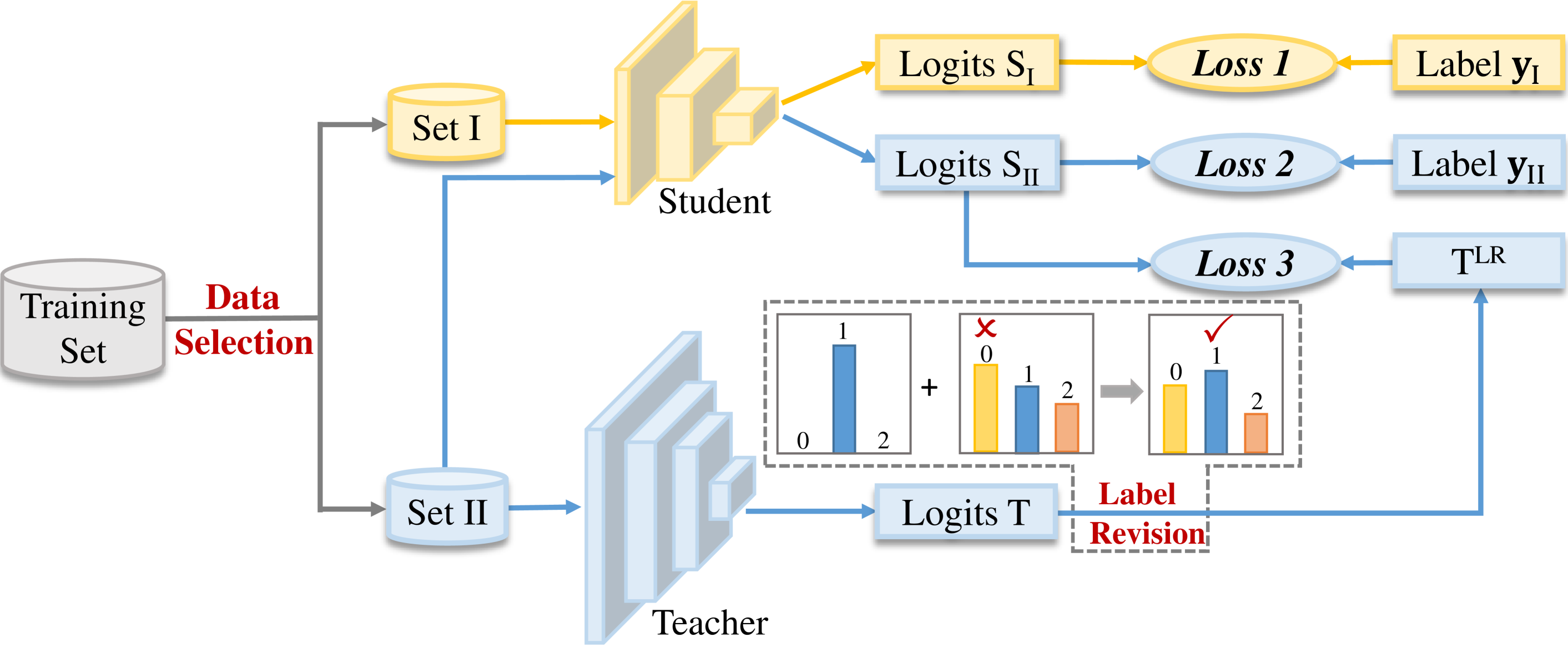
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
0
0
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
4/8/2024
🌐
Toward Student-Oriented Teacher Network Training For Knowledge Distillation
Chengyu Dong, Liyuan Liu, Jingbo Shang
0
0
How to conduct teacher training for knowledge distillation is still an open problem. It has been widely observed that a best-performing teacher does not necessarily yield the best-performing student, suggesting a fundamental discrepancy between the current teacher training practice and the ideal teacher training strategy. To fill this gap, we explore the feasibility of training a teacher that is oriented toward student performance with empirical risk minimization (ERM). Our analyses are inspired by the recent findings that the effectiveness of knowledge distillation hinges on the teacher's capability to approximate the true label distribution of training inputs. We theoretically establish that the ERM minimizer can approximate the true label distribution of training data as long as the feature extractor of the learner network is Lipschitz continuous and is robust to feature transformations. In light of our theory, we propose a teacher training method SoTeacher which incorporates Lipschitz regularization and consistency regularization into ERM. Experiments on benchmark datasets using various knowledge distillation algorithms and teacher-student pairs confirm that SoTeacher can improve student accuracy consistently.
5/10/2024