DistillGrasp: Integrating Features Correlation with Knowledge Distillation for Depth Completion of Transparent Objects

0
Sign in to get full access
Overview
- Distillation learning
- Depth completion
- Transparent object grasping
Plain English Explanation
The provided paper discusses several key concepts in robotics and computer vision:
-
Distillation Learning: This refers to the process of taking a complex machine learning model and distilling its knowledge into a simpler, more efficient model. This can be useful for deploying models on resource-constrained devices.
-
Depth Completion: Depth completion is the task of taking incomplete or sparse depth information (such as from a sensor) and using that to infer a complete, dense depth map of a scene. This is important for applications like robotic navigation and 3D reconstruction.
-
Transparent Object Grasping: Grasping transparent objects is a challenging task for robots, as the lack of visual cues can make it difficult to accurately perceive the object's shape and position. The paper likely explores techniques for enabling robots to effectively grasp and manipulate transparent objects.
The paper likely discusses research advances in these areas and how they can be applied to improve robotic capabilities.
Technical Explanation
The key technical elements of the paper likely include:
-
Distillation Learning Approach: The paper may present a novel distillation learning technique that can efficiently transfer knowledge from a complex model to a simpler one, enabling deployment on resource-constrained platforms.
-
Depth Completion Architecture: The paper may describe a deep learning-based architecture for taking sparse depth information and producing a dense, high-quality depth map. This could involve novel neural network designs or training strategies.
-
Transparent Object Grasping System: The paper may introduce a robotic system capable of accurately perceiving and grasping transparent objects, potentially using advanced 3D reconstruction, object detection, and grasp planning algorithms.
The paper likely evaluates the performance of these techniques through extensive experiments and benchmarks, providing insights into their strengths, limitations, and potential areas for further research.
Critical Analysis
While the research presented in the paper seems promising, a few potential caveats and areas for further investigation may include:
- The distillation learning approach may have limitations in preserving the full expressiveness of the original complex model, which could impact downstream performance.
- The depth completion technique may struggle with highly complex or dynamic scenes, where the sparse depth input may not provide sufficient information for accurate reconstruction.
- The transparent object grasping system may have difficulty with certain object shapes, materials, or environmental conditions, and its performance may need to be further evaluated in real-world scenarios.
Addressing these areas could help strengthen the proposed techniques and expand their applicability.
Conclusion
The paper presents advancements in distillation learning, depth completion, and transparent object grasping - all of which are crucial for developing more capable and versatile robotic systems. The research findings could have significant implications for various applications, such as mobile robotics, augmented reality, and assistive technologies. Further refinement and validation of these techniques could lead to more efficient, robust, and adaptable robotic solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DistillGrasp: Integrating Features Correlation with Knowledge Distillation for Depth Completion of Transparent Objects
Yiheng Huang, Junhong Chen, Nick Michiels, Muhammad Asim, Luc Claesen, Wenyin Liu
Due to the visual properties of reflection and refraction, RGB-D cameras cannot accurately capture the depth of transparent objects, leading to incomplete depth maps. To fill in the missing points, recent studies tend to explore new visual features and design complex networks to reconstruct the depth, however, these approaches tremendously increase computation, and the correlation of different visual features remains a problem. To this end, we propose an efficient depth completion network named DistillGrasp which distillates knowledge from the teacher branch to the student branch. Specifically, in the teacher branch, we design a position correlation block (PCB) that leverages RGB images as the query and key to search for the corresponding values, guiding the model to establish correct correspondence between two features and transfer it to the transparent areas. For the student branch, we propose a consistent feature correlation module (CFCM) that retains the reliable regions of RGB images and depth maps respectively according to the consistency and adopts a CNN to capture the pairwise relationship for depth completion. To avoid the student branch only learning regional features from the teacher branch, we devise a distillation loss that not only considers the distance loss but also the object structure and edge information. Extensive experiments conducted on the ClearGrasp dataset manifest that our teacher network outperforms state-of-the-art methods in terms of accuracy and generalization, and the student network achieves competitive results with a higher speed of 48 FPS. In addition, the significant improvement in a real-world robotic grasping system illustrates the effectiveness and robustness of our proposed system.
Read more8/2/2024

0
Transparent Object Depth Completion
Yifan Zhou, Wanli Peng, Zhongyu Yang, He Liu, Yi Sun
The perception of transparent objects for grasp and manipulation remains a major challenge, because existing robotic grasp methods which heavily rely on depth maps are not suitable for transparent objects due to their unique visual properties. These properties lead to gaps and inaccuracies in the depth maps of the transparent objects captured by depth sensors. To address this issue, we propose an end-to-end network for transparent object depth completion that combines the strengths of single-view RGB-D based depth completion and multi-view depth estimation. Moreover, we introduce a depth refinement module based on confidence estimation to fuse predicted depth maps from single-view and multi-view modules, which further refines the restored depth map. The extensive experiments on the ClearPose and TransCG datasets demonstrate that our method achieves superior accuracy and robustness in complex scenarios with significant occlusion compared to the state-of-the-art methods.
Read more5/27/2024

0
3D Feature Distillation with Object-Centric Priors
Georgios Tziafas, Yucheng Xu, Zhibin Li, Hamidreza Kasaei
Grounding natural language to the physical world is a ubiquitous topic with a wide range of applications in computer vision and robotics. Recently, 2D vision-language models such as CLIP have been widely popularized, due to their impressive capabilities for open-vocabulary grounding in 2D images. Recent works aim to elevate 2D CLIP features to 3D via feature distillation, but either learn neural fields that are scene-specific and hence lack generalization, or focus on indoor room scan data that require access to multiple camera views, which is not practical in robot manipulation scenarios. Additionally, related methods typically fuse features at pixel-level and assume that all camera views are equally informative. In this work, we show that this approach leads to sub-optimal 3D features, both in terms of grounding accuracy, as well as segmentation crispness. To alleviate this, we propose a multi-view feature fusion strategy that employs object-centric priors to eliminate uninformative views based on semantic information, and fuse features at object-level via instance segmentation masks. To distill our object-centric 3D features, we generate a large-scale synthetic multi-view dataset of cluttered tabletop scenes, spawning 15k scenes from over 3300 unique object instances, which we make publicly available. We show that our method reconstructs 3D CLIP features with improved grounding capacity and spatial consistency, while doing so from single-view RGB-D, thus departing from the assumption of multiple camera views at test time. Finally, we show that our approach can generalize to novel tabletop domains and be re-purposed for 3D instance segmentation without fine-tuning, and demonstrate its utility for language-guided robotic grasping in clutter
Read more7/16/2024
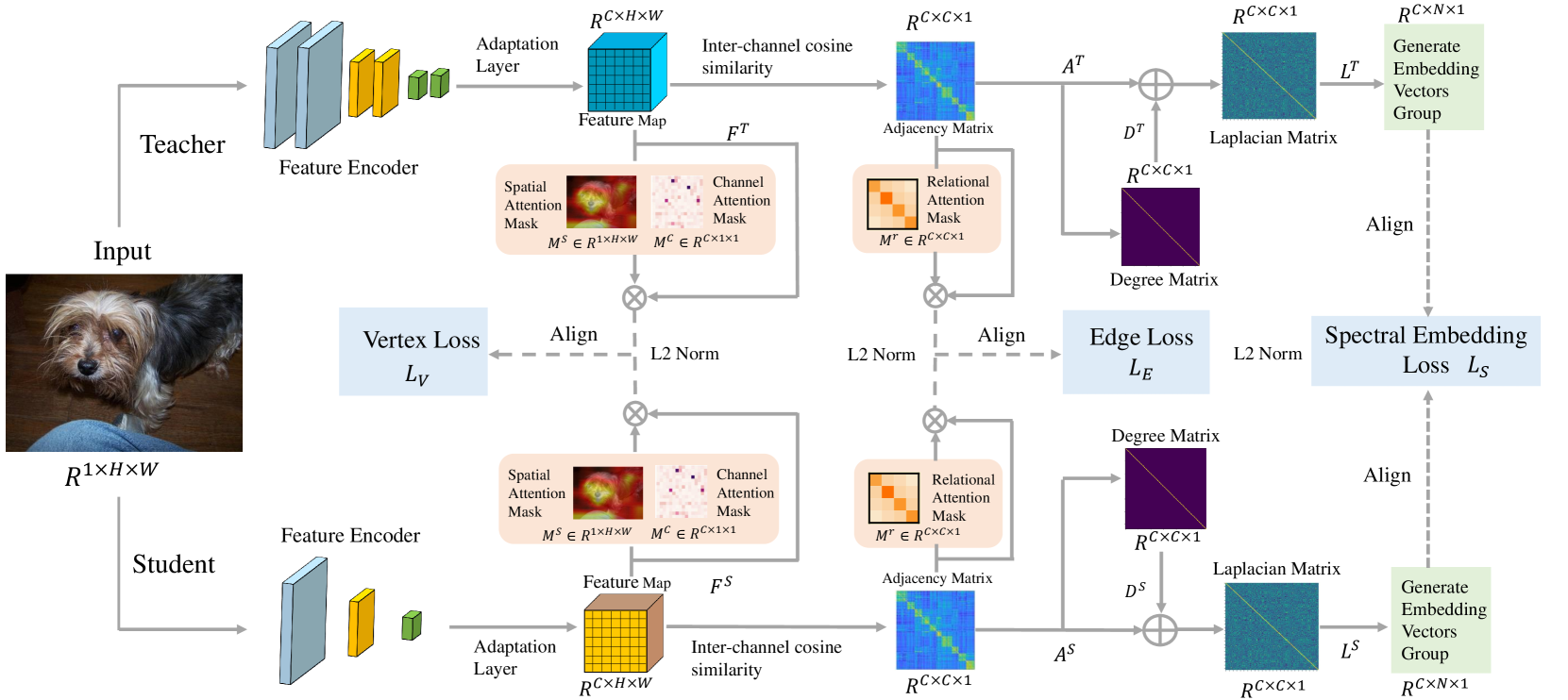
0
Exploring Graph-based Knowledge: Multi-Level Feature Distillation via Channels Relational Graph
Zhiwei Wang, Jun Huang, Longhua Ma, Chengyu Wu, Hongyu Ma
In visual tasks, large teacher models capture essential features and deep information, enhancing performance. However, distilling this information into smaller student models often leads to performance loss due to structural differences and capacity limitations. To tackle this, we propose a distillation framework based on graph knowledge, including a multi-level feature alignment strategy and an attention-guided mechanism to provide a targeted learning trajectory for the student model. We emphasize spectral embedding (SE) as a key technique in our distillation process, which merges the student's feature space with the relational knowledge and structural complexities similar to the teacher network. This method captures the teacher's understanding in a graph-based representation, enabling the student model to more accurately mimic the complex structural dependencies present in the teacher model. Compared to methods that focus only on specific distillation areas, our strategy not only considers key features within the teacher model but also endeavors to capture the relationships and interactions among feature sets, encoding these complex pieces of information into a graph structure to understand and utilize the dynamic relationships among these pieces of information from a global perspective. Experiments show that our method outperforms previous feature distillation methods on the CIFAR-100, MS-COCO, and Pascal VOC datasets, proving its efficiency and applicability.
Read more5/17/2024