3D Feature Distillation with Object-Centric Priors

0

Sign in to get full access
Overview
- This research paper proposes a novel approach for 3D feature distillation with object-centric priors.
- The key idea is to leverage object-level information to guide the learning of more effective 3D features for various 3D vision tasks.
- The authors introduce a new dataset, Multi-View Tabletop Objects Dataset, that provides multiple views of tabletop objects to support this research.
- Experiments demonstrate the benefits of their approach compared to existing methods for 3D object detection, 3D part segmentation, and other 3D vision tasks.
Plain English Explanation
The paper focuses on improving the way computers can understand and work with 3D data, which is crucial for applications like augmented reality, robotics, and autonomous vehicles. The key insight is that by considering the "objects" in a 3D scene, rather than just looking at the raw 3D data, the computer can learn more effective and useful 3D features.
For example, imagine you're trying to teach a computer to recognize chairs in a 3D point cloud. If the computer just looks at the raw 3D data, it might struggle to distinguish chairs from other furniture. But if it knows that chairs have certain distinctive 3D shapes and structures (like four legs, a seat, and a back), it can use that "object-level" information to better identify chairs in the 3D data.
The researchers developed a new dataset of 3D tabletop objects, with multiple views of each object, to help train and test their approach. Their method outperformed existing techniques on a variety of 3D vision tasks, demonstrating the benefits of incorporating this "object-centric" information when learning 3D features.
By focusing on the 3D shapes and structures of individual objects, rather than just the raw 3D data, this research represents an important step forward in helping computers better understand and work with 3D information in the real world.
Technical Explanation
The paper proposes a novel 3D feature distillation framework that leverages object-centric priors to learn more effective 3D features for various 3D vision tasks. The authors introduce the Multi-View Tabletop Objects Dataset, which provides multiple views of tabletop objects to support this research.
The key components of their approach include:
-
Object-Centric Priors: The framework uses object-level information, such as 3D shape and part segmentation, to guide the learning of more effective 3D features. This is in contrast to approaches that only consider raw 3D data.
-
Multi-View Feature Distillation: The method distills 3D features from multiple views of the same object to capture more comprehensive 3D information.
-
Task-Specific Heads: The framework includes task-specific head networks to enable efficient learning and inference for various 3D vision tasks, such as 3D object detection and 3D part segmentation.
The authors evaluate their approach on several 3D vision benchmarks, including 3D object detection and 3D part segmentation. The results demonstrate the benefits of their object-centric 3D feature distillation framework compared to existing methods.
Critical Analysis
The paper presents a compelling approach to improving 3D feature learning by leveraging object-centric priors. The introduction of the Multi-View Tabletop Objects Dataset is a valuable contribution, as it provides a new resource for training and evaluating 3D vision models.
One potential limitation of the research is the focus on tabletop objects, which may not fully capture the complexity of real-world 3D scenes. It would be interesting to see how the approach generalizes to more diverse 3D environments, such as indoor or outdoor scenes with a wider range of object types and occlusions.
Additionally, the paper does not provide a detailed analysis of the computational costs and inference times of the proposed framework. Understanding the trade-offs between performance and efficiency would be helpful for assessing the practical applicability of the method.
Overall, this research represents an important step forward in the field of 3D vision, and the authors' insights on the value of object-centric priors could inspire further developments in this area. Future work could explore ways to extend the approach to handle more complex 3D scenes and optimize the computational efficiency for real-world deployment.
Conclusion
This paper introduces a novel 3D feature distillation framework that leverages object-centric priors to learn more effective 3D features for various 3D vision tasks. By incorporating object-level information, such as 3D shape and part segmentation, the method outperforms existing approaches on benchmarks for 3D object detection and 3D part segmentation.
The introduction of the Multi-View Tabletop Objects Dataset is a valuable contribution, providing a new resource for training and evaluating 3D vision models. While the focus on tabletop objects may limit the generalizability of the approach, the researchers' insights on the importance of object-centric priors in 3D feature learning could inspire further advancements in this field.
As 3D vision continues to play an increasingly crucial role in emerging technologies, such as augmented reality, robotics, and autonomous vehicles, this research represents an important step towards developing more robust and effective 3D understanding capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
3D Feature Distillation with Object-Centric Priors
Georgios Tziafas, Yucheng Xu, Zhibin Li, Hamidreza Kasaei
Grounding natural language to the physical world is a ubiquitous topic with a wide range of applications in computer vision and robotics. Recently, 2D vision-language models such as CLIP have been widely popularized, due to their impressive capabilities for open-vocabulary grounding in 2D images. Recent works aim to elevate 2D CLIP features to 3D via feature distillation, but either learn neural fields that are scene-specific and hence lack generalization, or focus on indoor room scan data that require access to multiple camera views, which is not practical in robot manipulation scenarios. Additionally, related methods typically fuse features at pixel-level and assume that all camera views are equally informative. In this work, we show that this approach leads to sub-optimal 3D features, both in terms of grounding accuracy, as well as segmentation crispness. To alleviate this, we propose a multi-view feature fusion strategy that employs object-centric priors to eliminate uninformative views based on semantic information, and fuse features at object-level via instance segmentation masks. To distill our object-centric 3D features, we generate a large-scale synthetic multi-view dataset of cluttered tabletop scenes, spawning 15k scenes from over 3300 unique object instances, which we make publicly available. We show that our method reconstructs 3D CLIP features with improved grounding capacity and spatial consistency, while doing so from single-view RGB-D, thus departing from the assumption of multiple camera views at test time. Finally, we show that our approach can generalize to novel tabletop domains and be re-purposed for 3D instance segmentation without fine-tuning, and demonstrate its utility for language-guided robotic grasping in clutter
Read more7/16/2024
0
3D Open-Vocabulary Panoptic Segmentation with 2D-3D Vision-Language Distillation
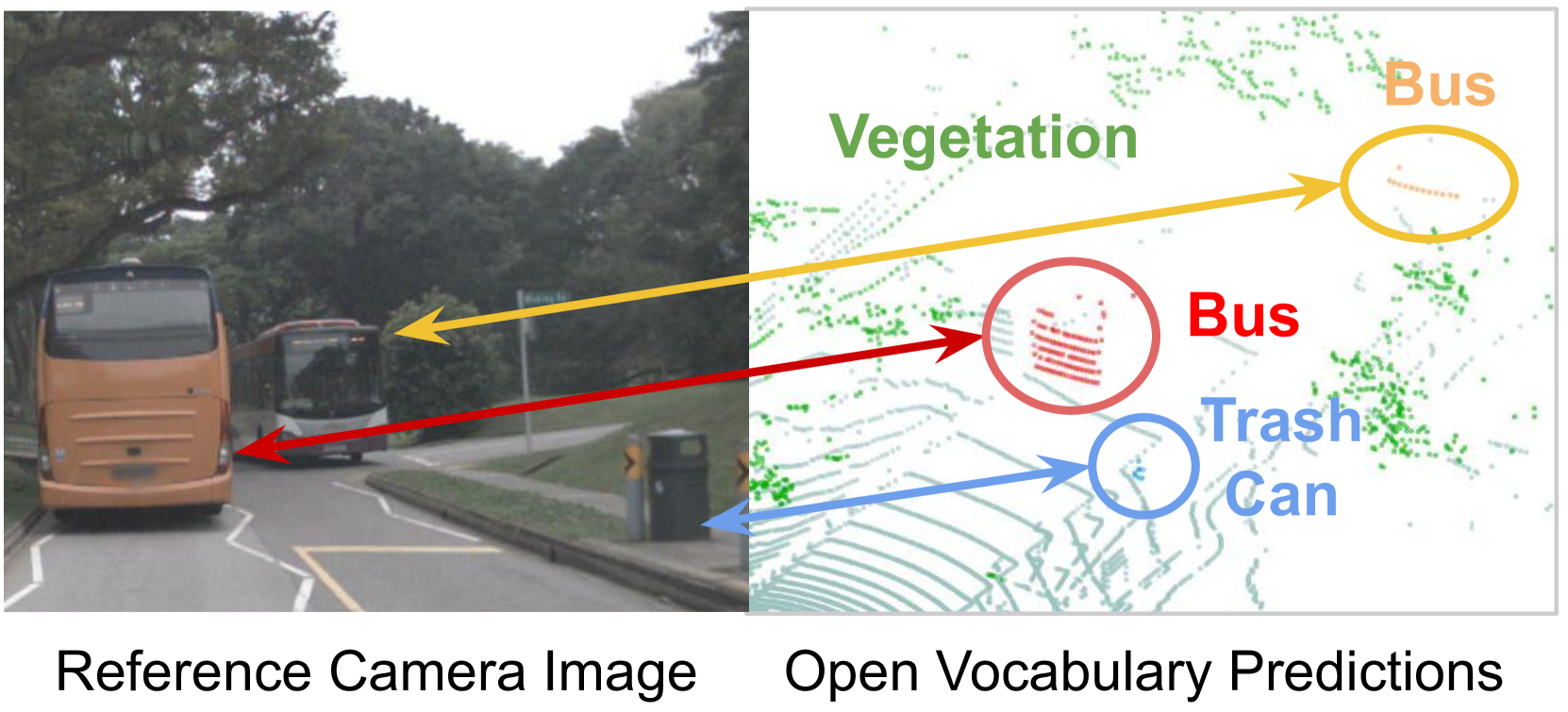
Zihao Xiao, Longlong Jing, Shangxuan Wu, Alex Zihao Zhu, Jingwei Ji, Chiyu Max Jiang, Wei-Chih Hung, Thomas Funkhouser, Weicheng Kuo, Anelia Angelova, Yin Zhou, Shiwei Sheng
3D panoptic segmentation is a challenging perception task, especially in autonomous driving. It aims to predict both semantic and instance annotations for 3D points in a scene. Although prior 3D panoptic segmentation approaches have achieved great performance on closed-set benchmarks, generalizing these approaches to unseen things and unseen stuff categories remains an open problem. For unseen object categories, 2D open-vocabulary segmentation has achieved promising results that solely rely on frozen CLIP backbones and ensembling multiple classification outputs. However, we find that simply extending these 2D models to 3D does not guarantee good performance due to poor per-mask classification quality, especially for novel stuff categories. In this paper, we propose the first method to tackle 3D open-vocabulary panoptic segmentation. Our model takes advantage of the fusion between learnable LiDAR features and dense frozen vision CLIP features, using a single classification head to make predictions for both base and novel classes. To further improve the classification performance on novel classes and leverage the CLIP model, we propose two novel loss functions: object-level distillation loss and voxel-level distillation loss. Our experiments on the nuScenes and SemanticKITTI datasets show that our method outperforms the strong baseline by a large margin.
Read more4/4/2024
📊
0
Four Ways to Improve Verbo-visual Fusion for Dense 3D Visual Grounding
Ozan Unal, Christos Sakaridis, Suman Saha, Luc Van Gool
3D visual grounding is the task of localizing the object in a 3D scene which is referred by a description in natural language. With a wide range of applications ranging from autonomous indoor robotics to AR/VR, the task has recently risen in popularity. A common formulation to tackle 3D visual grounding is grounding-by-detection, where localization is done via bounding boxes. However, for real-life applications that require physical interactions, a bounding box insufficiently describes the geometry of an object. We therefore tackle the problem of dense 3D visual grounding, i.e. referral-based 3D instance segmentation. We propose a dense 3D grounding network ConcreteNet, featuring four novel stand-alone modules that aim to improve grounding performance for challenging repetitive instances, i.e. instances with distractors of the same semantic class. First, we introduce a bottom-up attentive fusion module that aims to disambiguate inter-instance relational cues, next, we construct a contrastive training scheme to induce separation in the latent space, we then resolve view-dependent utterances via a learned global camera token, and finally we employ multi-view ensembling to improve referred mask quality. ConcreteNet ranks 1st on the challenging ScanRefer online benchmark and has won the ICCV 3rd Workshop on Language for 3D Scenes 3D Object Localization challenge. Our code is available at ouenal.github.io/concretenet/.
Read more7/17/2024
0
LabelDistill: Label-guided Cross-modal Knowledge Distillation for Camera-based 3D Object Detection
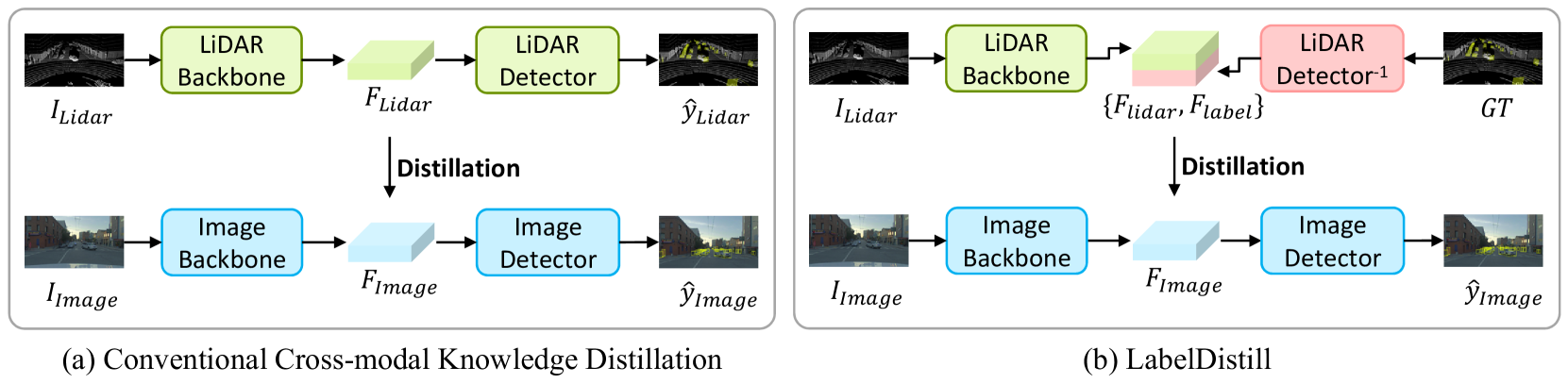
Sanmin Kim, Youngseok Kim, Sihwan Hwang, Hyeonjun Jeong, Dongsuk Kum
Recent advancements in camera-based 3D object detection have introduced cross-modal knowledge distillation to bridge the performance gap with LiDAR 3D detectors, leveraging the precise geometric information in LiDAR point clouds. However, existing cross-modal knowledge distillation methods tend to overlook the inherent imperfections of LiDAR, such as the ambiguity of measurements on distant or occluded objects, which should not be transferred to the image detector. To mitigate these imperfections in LiDAR teacher, we propose a novel method that leverages aleatoric uncertainty-free features from ground truth labels. In contrast to conventional label guidance approaches, we approximate the inverse function of the teacher's head to effectively embed label inputs into feature space. This approach provides additional accurate guidance alongside LiDAR teacher, thereby boosting the performance of the image detector. Additionally, we introduce feature partitioning, which effectively transfers knowledge from the teacher modality while preserving the distinctive features of the student, thereby maximizing the potential of both modalities. Experimental results demonstrate that our approach improves mAP and NDS by 5.1 points and 4.9 points compared to the baseline model, proving the effectiveness of our approach. The code is available at https://github.com/sanmin0312/LabelDistill
Read more7/16/2024