Distilling System 2 into System 1

546

Sign in to get full access
Overview
- This paper proposes a novel approach to "distilling" System 2 (deliberate, analytical) processing into System 1 (intuitive, automatic) processing.
- The goal is to train AI systems to perform complex tasks more efficiently by leveraging both System 1 and System 2 reasoning.
- The authors demonstrate their approach on various tasks, including [add relevant internal links here].
Plain English Explanation
The human mind has two main modes of thinking: System 1 and System 2. System 1 is fast, intuitive, and automatic, while System 2 is slower, more deliberate, and analytical. [https://aimodels.fyi/papers/arxiv/minds-mirror-distilling-self-evaluation-capability-comprehensive]
This paper explores ways to combine the strengths of both systems in AI models. The researchers want to teach AI models to perform complex tasks efficiently by first using the analytical power of System 2 to learn the task, and then distilling that knowledge into a faster, more intuitive System 1 model. [https://aimodels.fyi/papers/arxiv/distillation-matters-empowering-sequential-recommenders-to-match]
For example, imagine an AI system learning to play chess. First, it would use System 2 thinking to carefully analyze the chess board, consider possible moves, and plan its strategy. Over time, as the AI plays more games, it would gradually develop an intuitive "feel" for good chess moves, like a human grandmaster. This System 1 chess intuition would allow the AI to play much faster without sacrificing performance.
By combining System 1 and System 2 processing, the researchers aim to create AI models that are both highly capable and efficient, able to tackle complex problems with speed and flexibility. [https://aimodels.fyi/papers/arxiv/beyond-imitation-learning-key-reasoning-steps-from]
Technical Explanation
The core of the researchers' approach is a "distillation" process that transfers knowledge from a complex, System 2-style model to a simpler, more intuitive System 1 model. [https://aimodels.fyi/papers/arxiv/sub-goal-distillation-method-to-improve-small]
First, the researchers train a powerful System 2 model to perform a task using traditional machine learning techniques. This model is able to reason about the task in depth but may be slow or computationally expensive.
Next, the researchers train a smaller, more efficient System 1 model to mimic the behavior of the System 2 model. This "distillation" process involves feeding the System 2 model's outputs (e.g. chess move predictions) to the System 1 model during training, allowing it to learn the same underlying task knowledge in a more compact, intuitive form.
The researchers demonstrate the effectiveness of their approach on a variety of tasks, including [add relevant internal links here]. Their results show that the distilled System 1 models are able to achieve similar performance to the original System 2 models, but with significantly improved efficiency and faster inference times.
Critical Analysis
The researchers acknowledge several limitations of their approach. First, the effectiveness of the distillation process may be task-dependent, requiring careful hyperparameter tuning and architectural choices to work well. [https://aimodels.fyi/papers/arxiv/distilling-algorithmic-reasoning-from-llms-via-explaining]
Additionally, the distilled System 1 models may not be as transparent or interpretable as the original System 2 models, making it harder to understand the underlying reasoning process. Further research is needed to address this issue.
Another potential concern is the risk of "forgetting" or losing important information during the distillation process. The researchers suggest incorporating techniques like knowledge retention to mitigate this problem, but more work is needed to fully address it.
Overall, the researchers' approach represents a promising step towards developing AI systems that can leverage the complementary strengths of System 1 and System 2 processing. However, further research is needed to refine the methodology and address the remaining challenges.
Conclusion
This paper presents a novel approach to "distilling" the analytical power of System 2 reasoning into a more efficient, intuitive System 1 model. By combining these two modes of thinking, the researchers aim to create AI systems that are highly capable and flexible, able to tackle complex problems with speed and precision.
The results of the experiments are promising, suggesting that this distillation approach can lead to significant improvements in the efficiency and performance of AI models across a variety of tasks. However, the researchers acknowledge several limitations and areas for further research, including the need for task-specific tuning, maintaining model transparency, and addressing potential information loss during the distillation process.
Overall, this work represents an important step towards the development of more advanced, human-like AI systems that can seamlessly integrate intuitive and analytical reasoning. As the field of AI continues to evolve, approaches like this will likely play a crucial role in pushing the boundaries of what is possible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
546
Distilling System 2 into System 1
Ping Yu, Jing Xu, Jason Weston, Ilia Kulikov
Large language models (LLMs) can spend extra compute during inference to generate intermediate thoughts, which helps to produce better final responses. Since Chain-of-Thought (Wei et al., 2022), many such System 2 techniques have been proposed such as Rephrase and Respond (Deng et al., 2023a), System 2 Attention (Weston and Sukhbaatar, 2023) and Branch-Solve-Merge (Saha et al., 2023). In this work we investigate self-supervised methods to ``compile'' (distill) higher quality outputs from System 2 techniques back into LLM generations without intermediate reasoning token sequences, as this reasoning has been distilled into System 1. We show that several such techniques can be successfully distilled, resulting in improved results compared to the original System 1 performance, and with less inference cost than System 2. We posit that such System 2 distillation will be an important feature of future continually learning AI systems, enabling them to focus System 2 capabilities on the reasoning tasks that they cannot yet do well.
Read more7/26/2024
💬
0
Mind's Mirror: Distilling Self-Evaluation Capability and Comprehensive Thinking from Large Language Models
Weize Liu, Guocong Li, Kai Zhang, Bang Du, Qiyuan Chen, Xuming Hu, Hongxia Xu, Jintai Chen, Jian Wu
Large language models (LLMs) have achieved remarkable advancements in natural language processing. However, the massive scale and computational demands of these models present formidable challenges when considering their practical deployment in resource-constrained environments. While techniques such as chain-of-thought (CoT) distillation have displayed promise in distilling LLMs into small language models (SLMs), there is a risk that distilled SLMs may still inherit flawed reasoning and hallucinations from LLMs. To address these issues, we propose a twofold methodology: First, we introduce a novel method for distilling the self-evaluation capability from LLMs into SLMs, aiming to mitigate the adverse effects of flawed reasoning and hallucinations inherited from LLMs. Second, we advocate for distilling more comprehensive thinking by incorporating multiple distinct CoTs and self-evaluation outputs, to ensure a more thorough and robust knowledge transfer into SLMs. Experiments on three NLP benchmarks demonstrate that our method significantly improves the performance of distilled SLMs, offering a new perspective for developing more effective and efficient SLMs in resource-constrained environments.
Read more4/9/2024
0
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model
Yu Cui, Feng Liu, Pengbo Wang, Bohao Wang, Heng Tang, Yi Wan, Jun Wang, Jiawei Chen
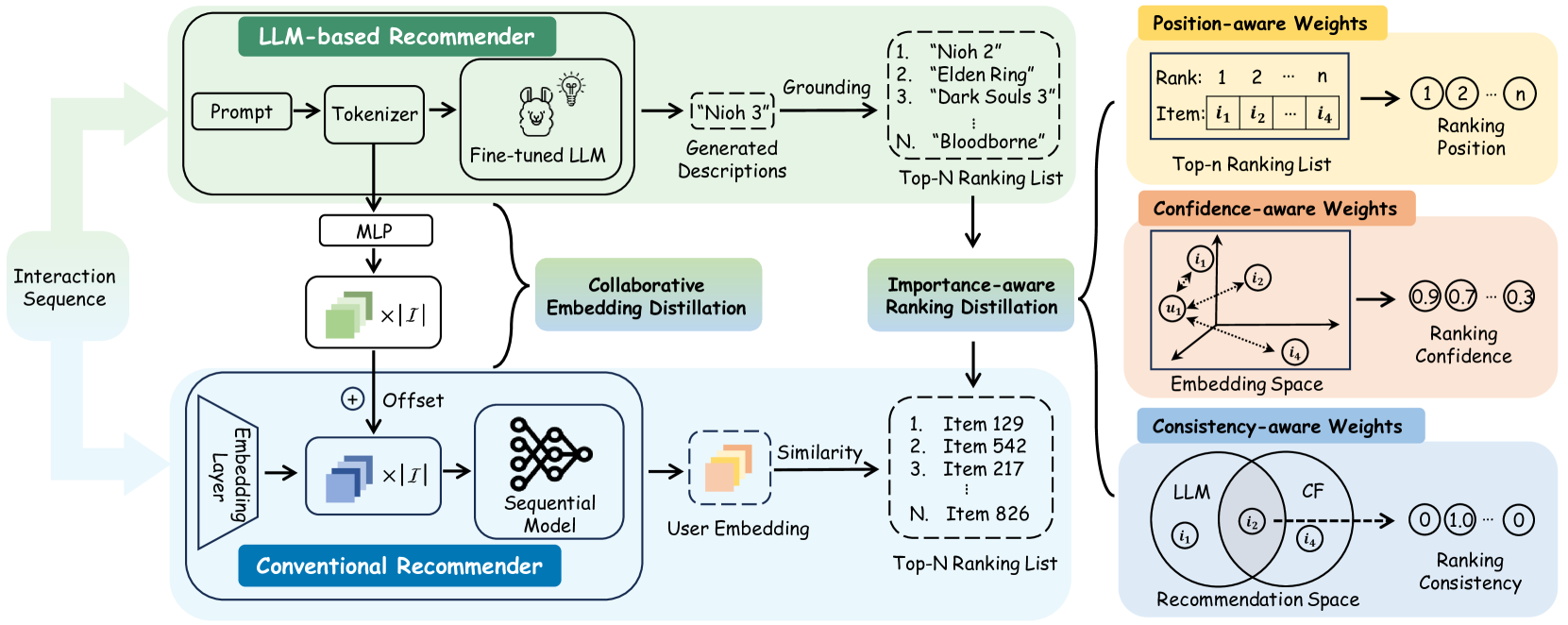
Owing to their powerful semantic reasoning capabilities, Large Language Models (LLMs) have been effectively utilized as recommenders, achieving impressive performance. However, the high inference latency of LLMs significantly restricts their practical deployment. To address this issue, this work investigates knowledge distillation from cumbersome LLM-based recommendation models to lightweight conventional sequential models. It encounters three challenges: 1) the teacher's knowledge may not always be reliable; 2) the capacity gap between the teacher and student makes it difficult for the student to assimilate the teacher's knowledge; 3) divergence in semantic space poses a challenge to distill the knowledge from embeddings. To tackle these challenges, this work proposes a novel distillation strategy, DLLM2Rec, specifically tailored for knowledge distillation from LLM-based recommendation models to conventional sequential models. DLLM2Rec comprises: 1) Importance-aware ranking distillation, which filters reliable and student-friendly knowledge by weighting instances according to teacher confidence and student-teacher consistency; 2) Collaborative embedding distillation integrates knowledge from teacher embeddings with collaborative signals mined from the data. Extensive experiments demonstrate the effectiveness of the proposed DLLM2Rec, boosting three typical sequential models with an average improvement of 47.97%, even enabling them to surpass LLM-based recommenders in some cases.
Read more8/21/2024

0
Beyond Imitation: Learning Key Reasoning Steps from Dual Chain-of-Thoughts in Reasoning Distillation
Chengwei Dai, Kun Li, Wei Zhou, Songlin Hu
As Large Language Models (LLMs) scale up and gain powerful Chain-of-Thoughts (CoTs) reasoning abilities, practical resource constraints drive efforts to distill these capabilities into more compact Smaller Language Models (SLMs). We find that CoTs consist mainly of simple reasoning forms, with a small proportion ($approx 4.7%$) of key reasoning steps that truly impact conclusions. However, previous distillation methods typically involve supervised fine-tuning student SLMs only on correct CoTs data produced by teacher LLMs, resulting in students struggling to learn the key reasoning steps, instead imitating the teacher's reasoning forms and making errors or omissions on these steps. To address these issues, drawing an analogy to human learning, where analyzing mistakes according to correct solutions often reveals the crucial steps leading to successes or failures, we propose mistaktextbf{E}-textbf{D}riven key reasontextbf{I}ng step distillatextbf{T}ion (textbf{EDIT}), a novel method that further aids SLMs learning key reasoning steps rather than mere simple fine-tuning. Firstly, to expose these crucial steps in CoTs, we design specific prompts to generate dual CoTs data with similar reasoning paths but divergent conclusions. Then, we apply the minimum edit distance algorithm on the dual CoTs data to locate these key steps and optimize the likelihood of these steps. Extensive experiments validate the effectiveness of EDIT across both in-domain and out-of-domain benchmark reasoning datasets. Further analysis shows that EDIT can generate high-quality CoTs with more correct key reasoning steps. Notably, we also explore how different mistake patterns affect performance and find that EDIT benefits more from logical errors than from knowledge or mathematical calculation errors in dual CoTsfootnote{Code can be found at url{https://github.com/C-W-D/EDIT}}.
Read more5/31/2024