Distinguishing Chatbot from Human

0
❗
Sign in to get full access
Overview
- Recent advancements in generative AI and large language models, such as the Generative Pre-trained Transformer (GPT) model, have led to the development of powerful chatbots.
- These chatbots can generate human-like text, making it challenging to differentiate between human-written and machine-generated content.
- Researchers have developed a new dataset of over 750,000 human-written paragraphs and their corresponding chatbot-generated counterparts.
- Machine learning techniques are applied to this dataset to determine the origin of the text (human or chatbot).
Plain English Explanation
Chatbots, which are AI-powered conversational agents, have become so advanced that it can be difficult to tell if the text they generate was written by a human or a machine. To better understand this problem, researchers have created a large dataset of over 750,000 paragraphs, with each human-written paragraph paired with a machine-generated version. Using this dataset, the researchers applied machine learning techniques to develop ways of automatically detecting whether a given piece of text was written by a human or a chatbot.
The researchers explored two main approaches: feature analysis and embeddings. Feature analysis involves identifying specific characteristics of the text, such as word choice, sentence structure, and tone, that can be used to distinguish human-written from machine-generated content. The embeddings approach uses AI models to represent the text in a numerical format, which can then be analyzed to uncover patterns that differentiate human and chatbot-generated text.
By developing these techniques, the researchers have created useful tools for analyzing textual content and gaining a better understanding of the capabilities of modern chatbots. This research can help inform discussions about the implications of advanced AI technology and how to approach the challenge of detecting machine-generated text.
Technical Explanation
The researchers created a dataset of over 750,000 human-written paragraphs, each paired with a corresponding chatbot-generated paragraph. This dataset was used to train and evaluate machine learning models for differentiating between human-written and chatbot-generated text.
The researchers explored two main approaches for this task:
-
Feature Analysis: This approach involved extracting a set of linguistic and stylistic features from the text, such as word choice, sentence structure, and writing style. These features were then used to train a machine learning classifier to predict whether a given piece of text was written by a human or a chatbot.
-
Embeddings: The researchers also experimented with using contextual embeddings and transformer-based architectures to represent the text in a numerical format. These numerical representations, or embeddings, were then used to train classification models that could distinguish between human-written and chatbot-generated content.
The researchers evaluated the performance of their proposed solutions using various metrics, such as accuracy, precision, and recall. Their results showed that both the feature analysis and embeddings-based approaches achieved high classification accuracy, demonstrating their effectiveness as tools for analyzing textual content and uncovering the source (human or chatbot) of the text.
Critical Analysis
The researchers acknowledged that their dataset, while large, may not be comprehensive in terms of capturing the full diversity of human writing styles and chatbot capabilities. Additionally, as language models and chatbot technologies continue to evolve, the ability to differentiate between human and machine-generated text may become increasingly challenging.
While the researchers' proposed solutions offer promising results, there may be concerns about the potential for these techniques to be used for surveillance or censorship purposes, especially in environments where free speech is already under threat. It is essential to consider the broader implications of this research and ensure that it is used responsibly and ethically.
Furthermore, the researchers did not discuss the potential biases or limitations inherent in the machine learning models they developed. It would be valuable for future research to explore these issues and address ways to mitigate any biases or shortcomings in the classification approaches.
Conclusion
This research represents an important step in understanding the capabilities of modern chatbots and developing techniques to differentiate between human-written and machine-generated text. The researchers' work on feature analysis and embeddings-based approaches provides valuable insights and tools for textual analysis in the era of advanced AI technology.
However, the researchers' findings also raise important questions about the implications of this technology, particularly in terms of potential misuse and the broader societal impacts. As the field of generative AI continues to evolve, it will be crucial to address these concerns and ensure that the development and application of these technologies are guided by principles of ethical and responsible innovation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
0
Distinguishing Chatbot from Human
Gauri Anil Godghase, Rishit Agrawal, Tanush Obili, Mark Stamp
There have been many recent advances in the fields of generative Artificial Intelligence (AI) and Large Language Models (LLM), with the Generative Pre-trained Transformer (GPT) model being a leading chatbot. LLM-based chatbots have become so powerful that it may seem difficult to differentiate between human-written and machine-generated text. To analyze this problem, we have developed a new dataset consisting of more than 750,000 human-written paragraphs, with a corresponding chatbot-generated paragraph for each. Based on this dataset, we apply Machine Learning (ML) techniques to determine the origin of text (human or chatbot). Specifically, we consider two methodologies for tackling this issue: feature analysis and embeddings. Our feature analysis approach involves extracting a collection of features from the text for classification. We also explore the use of contextual embeddings and transformer-based architectures to train classification models. Our proposed solutions offer high classification accuracy and serve as useful tools for textual analysis, resulting in a better understanding of chatbot-generated text in this era of advanced AI technology.
Read more8/12/2024

0
ChatGPT Code Detection: Techniques for Uncovering the Source of Code
Marc Oedingen, Raphael C. Engelhardt, Robin Denz, Maximilian Hammer, Wolfgang Konen
In recent times, large language models (LLMs) have made significant strides in generating computer code, blurring the lines between code created by humans and code produced by artificial intelligence (AI). As these technologies evolve rapidly, it is crucial to explore how they influence code generation, especially given the risk of misuse in areas like higher education. This paper explores this issue by using advanced classification techniques to differentiate between code written by humans and that generated by ChatGPT, a type of LLM. We employ a new approach that combines powerful embedding features (black-box) with supervised learning algorithms - including Deep Neural Networks, Random Forests, and Extreme Gradient Boosting - to achieve this differentiation with an impressive accuracy of 98%. For the successful combinations, we also examine their model calibration, showing that some of the models are extremely well calibrated. Additionally, we present white-box features and an interpretable Bayes classifier to elucidate critical differences between the code sources, enhancing the explainability and transparency of our approach. Both approaches work well but provide at most 85-88% accuracy. We also show that untrained humans solve the same task not better than random guessing. This study is crucial in understanding and mitigating the potential risks associated with using AI in code generation, particularly in the context of higher education, software development, and competitive programming.
Read more7/4/2024
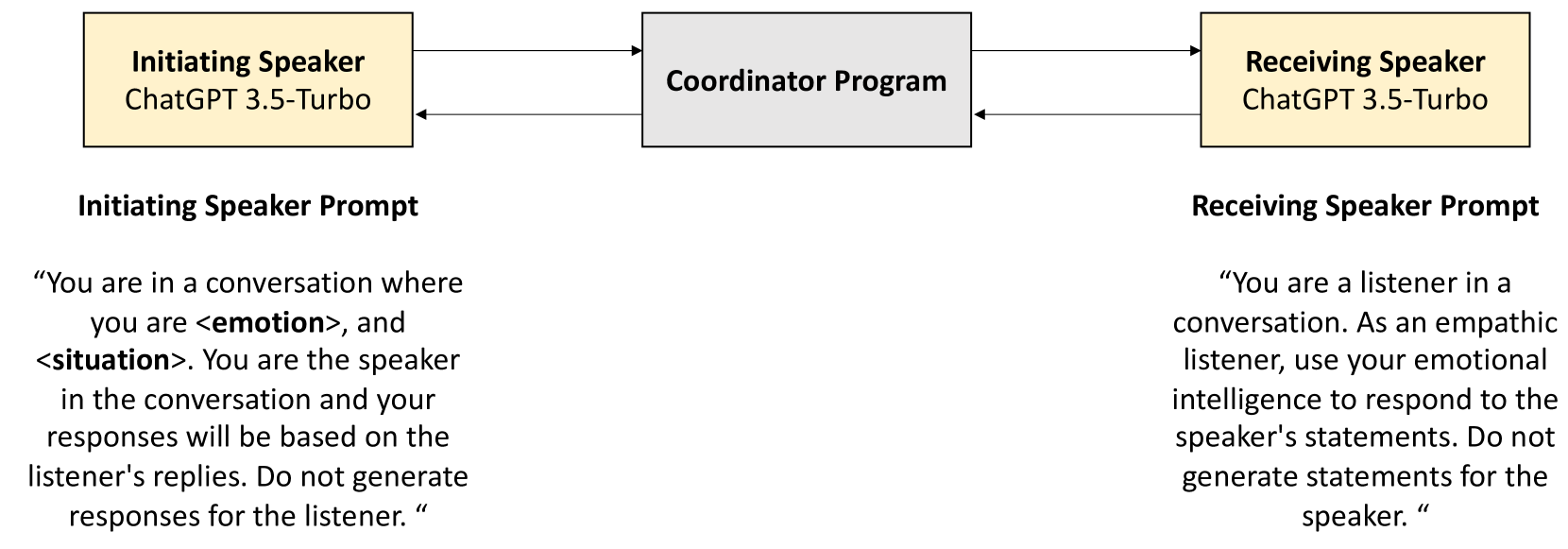
0
A Linguistic Comparison between Human and ChatGPT-Generated Conversations
Morgan Sandler, Hyesun Choung, Arun Ross, Prabu David
This study explores linguistic differences between human and LLM-generated dialogues, using 19.5K dialogues generated by ChatGPT-3.5 as a companion to the EmpathicDialogues dataset. The research employs Linguistic Inquiry and Word Count (LIWC) analysis, comparing ChatGPT-generated conversations with human conversations across 118 linguistic categories. Results show greater variability and authenticity in human dialogues, but ChatGPT excels in categories such as social processes, analytical style, cognition, attentional focus, and positive emotional tone, reinforcing recent findings of LLMs being more human than human. However, no significant difference was found in positive or negative affect between ChatGPT and human dialogues. Classifier analysis of dialogue embeddings indicates implicit coding of the valence of affect despite no explicit mention of affect in the conversations. The research also contributes a novel, companion ChatGPT-generated dataset of conversations between two independent chatbots, which were designed to replicate a corpus of human conversations available for open access and used widely in AI research on language modeling. Our findings enhance understanding of ChatGPT's linguistic capabilities and inform ongoing efforts to distinguish between human and LLM-generated text, which is critical in detecting AI-generated fakes, misinformation, and disinformation.
Read more4/29/2024
🔎
0
Differentiating between human-written and AI-generated texts using linguistic features automatically extracted from an online computational tool
Georgios P. Georgiou
While extensive research has focused on ChatGPT in recent years, very few studies have systematically quantified and compared linguistic features between human-written and Artificial Intelligence (AI)-generated language. This study aims to investigate how various linguistic components are represented in both types of texts, assessing the ability of AI to emulate human writing. Using human-authored essays as a benchmark, we prompted ChatGPT to generate essays of equivalent length. These texts were analyzed using Open Brain AI, an online computational tool, to extract measures of phonological, morphological, syntactic, and lexical constituents. Despite AI-generated texts appearing to mimic human speech, the results revealed significant differences across multiple linguistic features such as consonants, word stress, nouns, verbs, pronouns, direct objects, prepositional modifiers, and use of difficult words among others. These findings underscore the importance of integrating automated tools for efficient language assessment, reducing time and effort in data analysis. Moreover, they emphasize the necessity for enhanced training methodologies to improve the capacity of AI for producing more human-like text.
Read more7/12/2024