ChatGPT Code Detection: Techniques for Uncovering the Source of Code
2405.15512
0
0

Abstract
In recent times, large language models (LLMs) have made significant strides in generating computer code, blurring the lines between code created by humans and code produced by artificial intelligence (AI). As these technologies evolve rapidly, it is crucial to explore how they influence code generation, especially given the risk of misuse in areas like higher education. This paper explores this issue by using advanced classification techniques to differentiate between code written by humans and that generated by ChatGPT, a type of LLM. We employ a new approach that combines powerful embedding features (black-box) with supervised learning algorithms - including Deep Neural Networks, Random Forests, and Extreme Gradient Boosting - to achieve this differentiation with an impressive accuracy of 98%. For the successful combinations, we also examine their model calibration, showing that some of the models are extremely well calibrated. Additionally, we present white-box features and an interpretable Bayes classifier to elucidate critical differences between the code sources, enhancing the explainability and transparency of our approach. Both approaches work well but provide at most 85-88% accuracy. We also show that untrained humans solve the same task not better than random guessing. This study is crucial in understanding and mitigating the potential risks associated with using AI in code generation, particularly in the context of higher education, software development, and competitive programming.
Create account to get full access
Overview
- This paper presents an observational study of how people use the ChatGPT language model for various tasks, such as code generation, programming skills evaluation, and open-ended prompts to explore its capabilities.
- The study also includes a linguistic comparison between human-generated and ChatGPT-generated conversations to understand the differences in language use.
- Additionally, the paper evaluates the usability of ChatGPT as a code generation tool.
Plain English Explanation
The researchers conducted a study to understand how people are using the ChatGPT language model, a powerful AI system that can generate human-like text. They looked at how people use ChatGPT for different tasks, such as writing code, evaluating programming skills, and asking it open-ended questions to see what it can do.
The researchers also compared the language used in conversations with ChatGPT to language used by humans. This helped them understand the differences between how ChatGPT and humans communicate.
Finally, the researchers evaluated how easy it is for people to use ChatGPT to generate code, which is an important task for many users.
Technical Explanation
The researchers used a combination of observational studies and linguistic analysis to understand how people interact with ChatGPT. They observed participants using ChatGPT for various tasks, including code generation, programming skills evaluation, and open-ended exploration. The researchers recorded and analyzed the interactions to understand the types of prompts users provided, the responses they received, and how they used the output.
To compare the language used in human-ChatGPT conversations to human-human conversations, the researchers collected a corpus of both types of conversations and performed linguistic analysis. They looked at factors like vocabulary, sentence structure, and conversational patterns to identify differences between the two.
The researchers also evaluated the usability of ChatGPT as a code generation tool. They had participants use ChatGPT to generate code for specific programming tasks and assessed factors like code quality, completion time, and user satisfaction.
Critical Analysis
The paper provides valuable insights into how people are currently using ChatGPT and the differences between human-generated and AI-generated language. However, the study has some limitations. The observational data is based on a relatively small number of participants, and the linguistic analysis may not fully capture the nuances of human-ChatGPT interactions.
Additionally, the evaluation of ChatGPT's usability as a code generation tool is limited to specific programming tasks. More research is needed to understand how well ChatGPT performs on a wider range of coding challenges and in real-world software development scenarios.
The paper also does not address potential ethical concerns around the use of large language models like ChatGPT, such as the risk of generated content being used for misinformation or other harmful purposes. Future research should consider these important issues.
Conclusion
This study offers a comprehensive look at how people are currently using ChatGPT and the differences between human-generated and AI-generated language. The findings suggest that ChatGPT can be a useful tool for various tasks, but also highlight the need for further research and consideration of the technology's potential implications. As large language models continue to advance, it will be important to understand their capabilities, limitations, and ethical considerations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Unmasking the giant: A comprehensive evaluation of ChatGPT's proficiency in coding algorithms and data structures
Sayed Erfan Arefin, Tasnia Ashrafi Heya, Hasan Al-Qudah, Ynes Ineza, Abdul Serwadda
0
0
The transformative influence of Large Language Models (LLMs) is profoundly reshaping the Artificial Intelligence (AI) technology domain. Notably, ChatGPT distinguishes itself within these models, demonstrating remarkable performance in multi-turn conversations and exhibiting code proficiency across an array of languages. In this paper, we carry out a comprehensive evaluation of ChatGPT's coding capabilities based on what is to date the largest catalog of coding challenges. Our focus is on the python programming language and problems centered on data structures and algorithms, two topics at the very foundations of Computer Science. We evaluate ChatGPT for its ability to generate correct solutions to the problems fed to it, its code quality, and nature of run-time errors thrown by its code. Where ChatGPT code successfully executes, but fails to solve the problem at hand, we look into patterns in the test cases passed in order to gain some insights into how wrong ChatGPT code is in these kinds of situations. To infer whether ChatGPT might have directly memorized some of the data that was used to train it, we methodically design an experiment to investigate this phenomena. Making comparisons with human performance whenever feasible, we investigate all the above questions from the context of both its underlying learning models (GPT-3.5 and GPT-4), on a vast array sub-topics within the main topics, and on problems having varying degrees of difficulty.
5/28/2024
✨
Beyond Code Generation: An Observational Study of ChatGPT Usage in Software Engineering Practice
Ranim Khojah, Mazen Mohamad, Philipp Leitner, Francisco Gomes de Oliveira Neto
0
0
Large Language Models (LLMs) are frequently discussed in academia and the general public as support tools for virtually any use case that relies on the production of text, including software engineering. Currently there is much debate, but little empirical evidence, regarding the practical usefulness of LLM-based tools such as ChatGPT for engineers in industry. We conduct an observational study of 24 professional software engineers who have been using ChatGPT over a period of one week in their jobs, and qualitatively analyse their dialogues with the chatbot as well as their overall experience (as captured by an exit survey). We find that, rather than expecting ChatGPT to generate ready-to-use software artifacts (e.g., code), practitioners more often use ChatGPT to receive guidance on how to solve their tasks or learn about a topic in more abstract terms. We also propose a theoretical framework for how (i) purpose of the interaction, (ii) internal factors (e.g., the user's personality), and (iii) external factors (e.g., company policy) together shape the experience (in terms of perceived usefulness and trust). We envision that our framework can be used by future research to further the academic discussion on LLM usage by software engineering practitioners, and to serve as a reference point for the design of future empirical LLM research in this domain.
5/22/2024
💬
Evaluation of the Programming Skills of Large Language Models
Luc Bryan Heitz, Joun Chamas, Christopher Scherb
0
0
The advent of Large Language Models (LLM) has revolutionized the efficiency and speed with which tasks are completed, marking a significant leap in productivity through technological innovation. As these chatbots tackle increasingly complex tasks, the challenge of assessing the quality of their outputs has become paramount. This paper critically examines the output quality of two leading LLMs, OpenAI's ChatGPT and Google's Gemini AI, by comparing the quality of programming code generated in both their free versions. Through the lens of a real-world example coupled with a systematic dataset, we investigate the code quality produced by these LLMs. Given their notable proficiency in code generation, this aspect of chatbot capability presents a particularly compelling area for analysis. Furthermore, the complexity of programming code often escalates to levels where its verification becomes a formidable task, underscoring the importance of our study. This research aims to shed light on the efficacy and reliability of LLMs in generating high-quality programming code, an endeavor that has significant implications for the field of software development and beyond.
5/24/2024
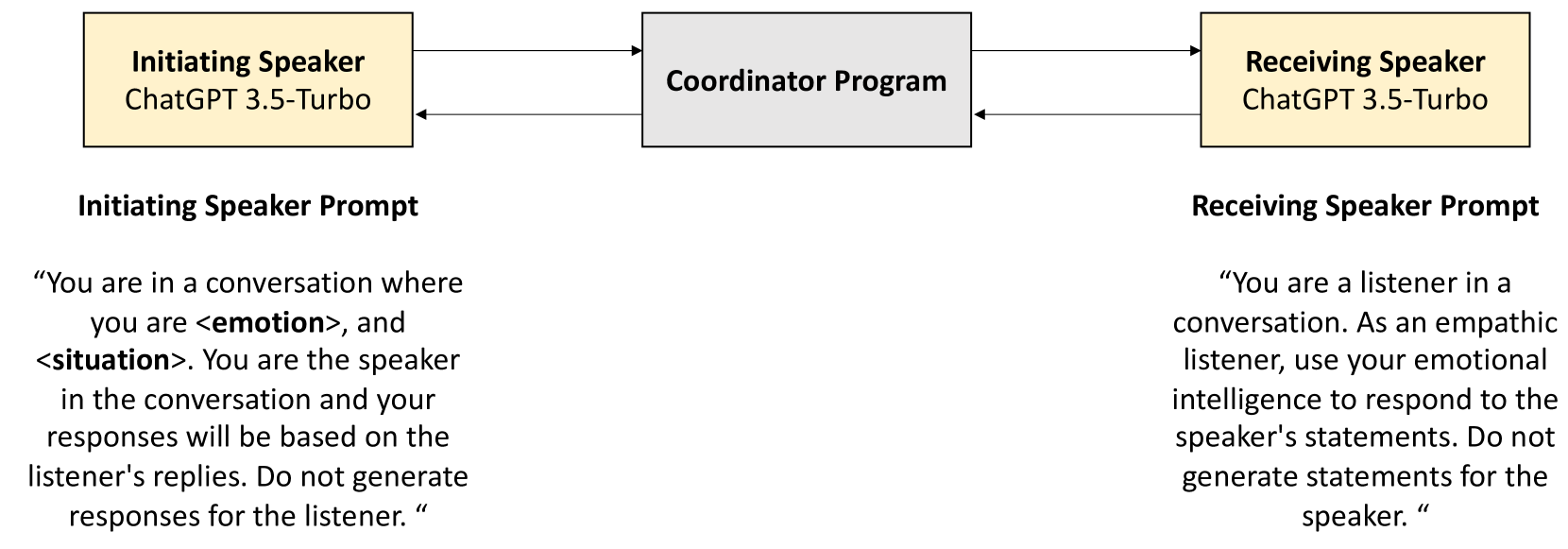
A Linguistic Comparison between Human and ChatGPT-Generated Conversations
Morgan Sandler, Hyesun Choung, Arun Ross, Prabu David
0
0
This study explores linguistic differences between human and LLM-generated dialogues, using 19.5K dialogues generated by ChatGPT-3.5 as a companion to the EmpathicDialogues dataset. The research employs Linguistic Inquiry and Word Count (LIWC) analysis, comparing ChatGPT-generated conversations with human conversations across 118 linguistic categories. Results show greater variability and authenticity in human dialogues, but ChatGPT excels in categories such as social processes, analytical style, cognition, attentional focus, and positive emotional tone, reinforcing recent findings of LLMs being more human than human. However, no significant difference was found in positive or negative affect between ChatGPT and human dialogues. Classifier analysis of dialogue embeddings indicates implicit coding of the valence of affect despite no explicit mention of affect in the conversations. The research also contributes a novel, companion ChatGPT-generated dataset of conversations between two independent chatbots, which were designed to replicate a corpus of human conversations available for open access and used widely in AI research on language modeling. Our findings enhance understanding of ChatGPT's linguistic capabilities and inform ongoing efforts to distinguish between human and LLM-generated text, which is critical in detecting AI-generated fakes, misinformation, and disinformation.
4/29/2024