Is In-Context Learning Sufficient for Instruction Following in LLMs?
2405.19874
2
0
Abstract
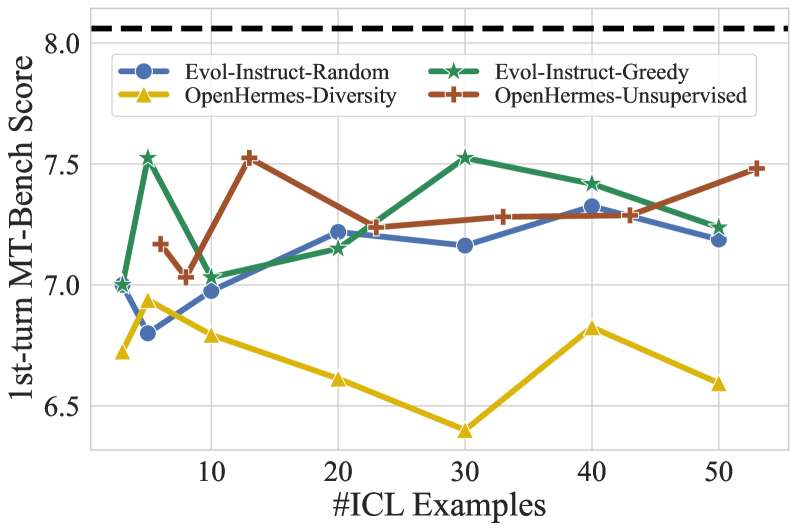
In-context learning (ICL) allows LLMs to learn from examples without changing their weights, which is a particularly promising capability for long-context LLMs that can potentially learn from many examples. Recently, Lin et al. (2024) proposed URIAL, a method using only three in-context examples to align base LLMs, achieving non-trivial instruction following performance. In this work, we show that, while effective, ICL alignment with URIAL still underperforms compared to instruction fine-tuning on established benchmarks such as MT-Bench and AlpacaEval 2.0 (LC), especially with more capable base LMs. Unlike for tasks such as classification, translation, or summarization, adding more ICL demonstrations for long-context LLMs does not systematically improve instruction following performance. To address this limitation, we derive a greedy selection approach for ICL examples that noticeably improves performance, yet without bridging the gap to instruction fine-tuning. Finally, we provide a series of ablation studies to better understand the reasons behind the remaining gap, and we show how some aspects of ICL depart from the existing knowledge and are specific to the instruction tuning setting. Overall, our work advances the understanding of ICL as an alignment technique. We provide our code at https://github.com/tml-epfl/icl-alignment.
Create account to get full access
Overview
- This paper investigates whether in-context learning is sufficient for instruction following in large language models (LLMs).
- The authors systematically evaluate the performance of the Urial LLM on a range of instruction-following tasks.
- They find that while Urial exhibits strong in-context learning abilities, it struggles with certain types of instructions, particularly those requiring multi-step reasoning or understanding of abstract concepts.
- The paper provides insights into the limitations of current LLM approaches for instruction following and highlights the need for further research to develop more capable and versatile instruction-following systems.
Plain English Explanation
The paper looks at whether large language models (LLMs) can learn to follow instructions just by seeing examples, without any additional training. The researchers tested an LLM called Urial on a variety of tasks that involved following instructions, like answering questions or completing tasks.
They found that Urial was pretty good at learning from the examples it was shown - this is called "in-context learning." It could often figure out how to do the task just by looking at a few examples. But Urial struggled with some types of instructions, especially ones that required multiple steps or understanding more abstract concepts.
This suggests that while in-context learning is a powerful capability, it may not be enough for LLMs to become truly proficient at following instructions. More research is needed to develop LLMs that can better understand and carry out complex instructions, which could be important for applications like personal assistants or automated task completion.
Technical Explanation
The paper presents a systematic evaluation of the Urial LLM's instruction-following capabilities. Urial is a state-of-the-art LLM with demonstrated strong in-context learning abilities.
The authors designed a suite of instruction-following tasks that tested Urial's ability to understand and execute a variety of commands, ranging from simple one-step instructions to more complex multi-step procedures. They found that while Urial exhibited impressive in-context learning performance on many tasks, it struggled with instructions that required deeper reasoning or understanding of more abstract concepts.
Further analysis revealed that Urial's performance degraded as the instructions became longer and more complex, suggesting that in-context learning alone may not be sufficient for developing truly capable instruction-following systems. The authors discuss the implications of these findings and highlight the need for continued research to address the limitations of current LLM approaches to instruction following.
Critical Analysis
The paper provides a thoughtful and rigorous examination of the limitations of in-context learning for instruction following in LLMs. The authors' systematic evaluation of Urial's performance across a diverse set of tasks gives a nuanced understanding of where current LLM approaches excel and where they fall short.
One potential limitation of the study is the specific choice of tasks and instructions used to test Urial. While the authors make a concerted effort to cover a wide range of complexity, there may be other types of instructions or domains that could further stress the model's capabilities. Additionally, the paper does not delve deeply into the specific reasons why Urial struggles with certain types of instructions, which could be an area for further investigation.
That said, the paper's key finding - that in-context learning alone is not sufficient for robust instruction following - is an important insight that should inspire further research into more sophisticated approaches. Developing LLMs that can reliably understand and execute complex, multi-step instructions will likely be crucial for realizing the full potential of these models in practical applications.
Conclusion
This paper presents a thorough examination of the limitations of in-context learning for instruction following in large language models. By systematically evaluating the performance of the Urial LLM on a diverse set of instruction-following tasks, the authors demonstrate that while Urial exhibits impressive in-context learning abilities, it struggles with instructions that require deeper reasoning or understanding of abstract concepts.
These findings highlight the need for continued research to develop LLMs that can more reliably understand and execute complex instructions. Improving instruction-following capabilities could have significant implications for the real-world deployment of LLMs in a wide range of applications, from personal assistants to automated task completion. Overall, this paper provides valuable insights and a foundation for future work in this important area of machine learning research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
How Far Can In-Context Alignment Go? Exploring the State of In-Context Alignment
Heyan Huang, Yinghao Li, Huashan Sun, Yu Bai, Yang Gao
0
0
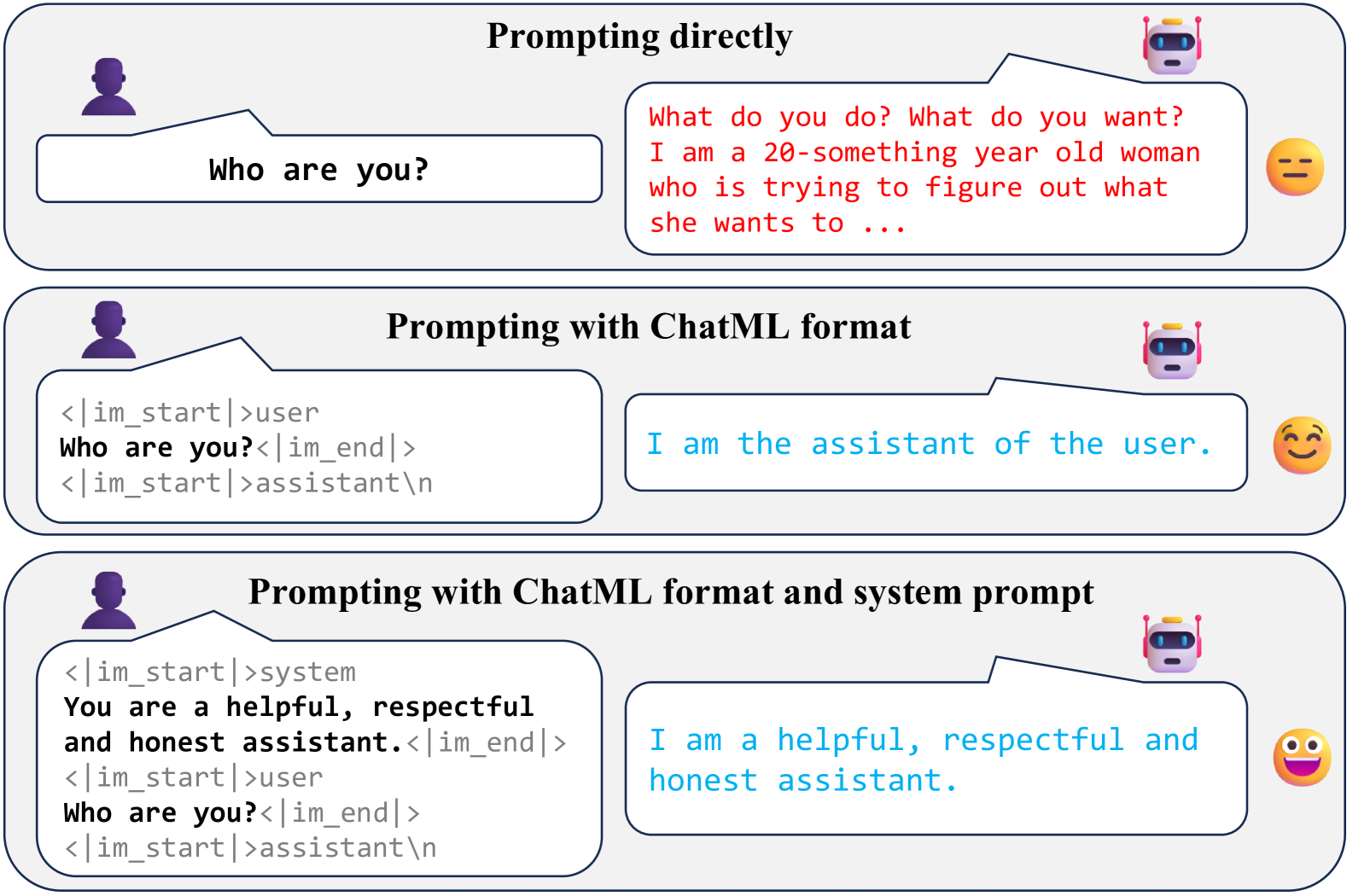
Recent studies have demonstrated that In-Context Learning (ICL), through the use of specific demonstrations, can align Large Language Models (LLMs) with human preferences known as In-Context Alignment (ICA), indicating that models can comprehend human instructions without requiring parameter adjustments. However, the exploration of the mechanism and applicability of ICA remains limited. In this paper, we begin by dividing the context text used in ICA into three categories: format, system prompt, and example. Through ablation experiments, we investigate the effectiveness of each part in enabling ICA to function effectively. We then examine how variants in these parts impact the model's alignment performance. Our findings indicate that the example part is crucial for enhancing the model's alignment capabilities, with changes in examples significantly affecting alignment performance. We also conduct a comprehensive evaluation of ICA's zero-shot capabilities in various alignment tasks. The results indicate that compared to parameter fine-tuning methods, ICA demonstrates superior performance in knowledge-based tasks and tool-use tasks. However, it still exhibits certain limitations in areas such as multi-turn dialogues and instruction following.
6/18/2024
📈
An Empirical Study of In-context Learning in LLMs for Machine Translation
Pranjal A. Chitale, Jay Gala, Raj Dabre
0
0
Recent interest has surged in employing Large Language Models (LLMs) for machine translation (MT) via in-context learning (ICL) (Vilar et al., 2023). Most prior studies primarily focus on optimizing translation quality, with limited attention to understanding the specific aspects of ICL that influence the said quality. To this end, we perform the first of its kind, an exhaustive study of in-context learning for machine translation. We first establish that ICL is primarily example-driven and not instruction-driven. Following this, we conduct an extensive exploration of various aspects of the examples to understand their influence on downstream performance. Our analysis includes factors such as quality and quantity of demonstrations, spatial proximity, and source versus target originality. Further, we also investigate challenging scenarios involving indirectness and misalignment of examples to understand the limits of ICL. While we establish the significance of the quality of the target distribution over the source distribution of demonstrations, we further observe that perturbations sometimes act as regularizers, resulting in performance improvements. Surprisingly, ICL does not necessitate examples from the same task, and a related task with the same target distribution proves sufficient. We hope that our study acts as a guiding resource for considerations in utilizing ICL for MT. Our code is available on https://github.com/PranjalChitale/in-context-mt-analysis.
6/6/2024
🌿
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, Zhifang Sui
0
0
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based on contexts augmented with a few examples. It has been a significant trend to explore ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress and challenges of ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques, including training strategies, prompt designing strategies, and related analysis. Additionally, we explore various ICL application scenarios, such as data engineering and knowledge updating. Finally, we address the challenges of ICL and suggest potential directions for further research. We hope that our work can encourage more research on uncovering how ICL works and improving ICL.
6/19/2024
In-Context Learning or: How I learned to stop worrying and love Applied Information Retrieval
Andrew Parry, Debasis Ganguly, Manish Chandra
0
0
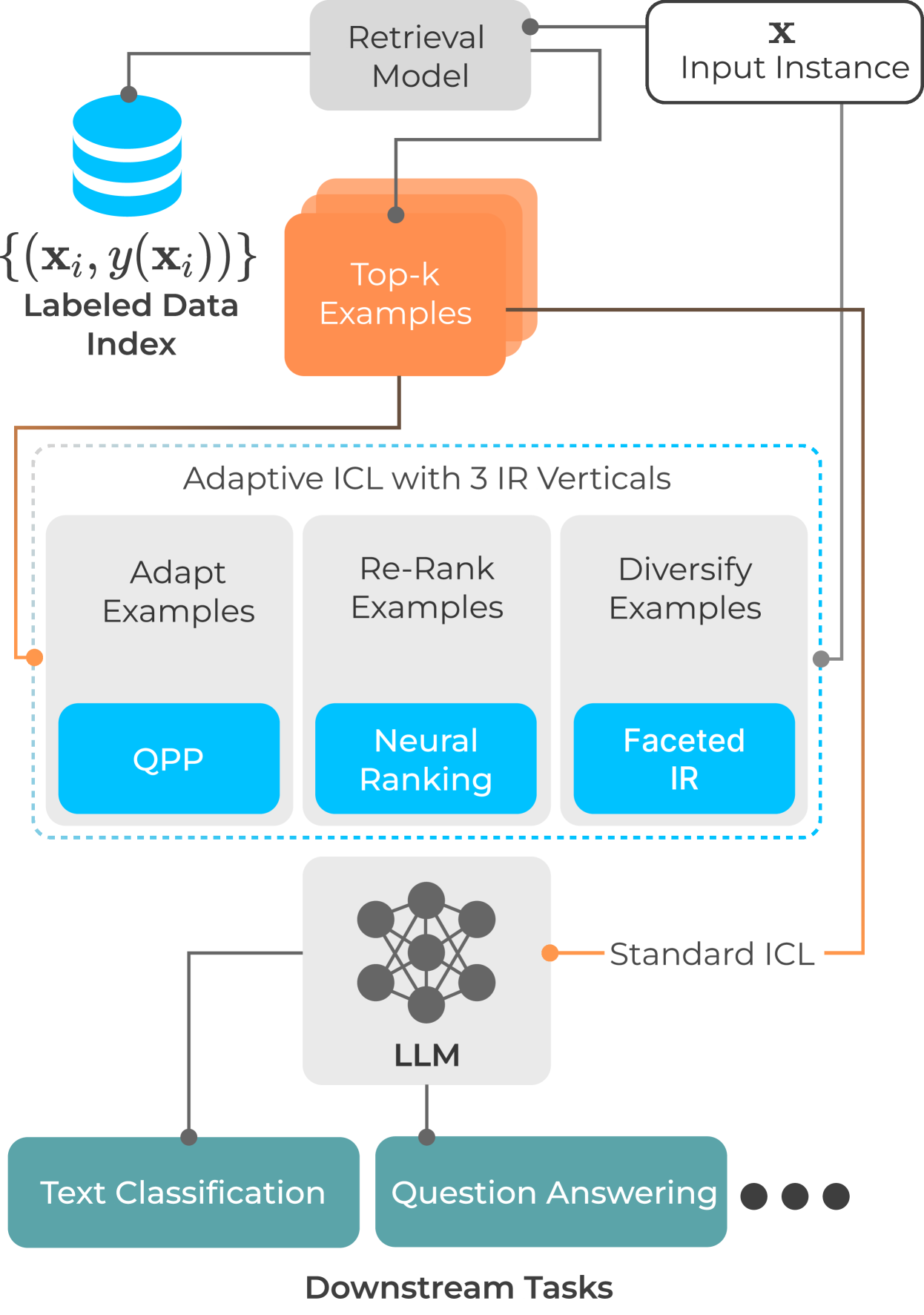
With the increasing ability of large language models (LLMs), in-context learning (ICL) has evolved as a new paradigm for natural language processing (NLP), where instead of fine-tuning the parameters of an LLM specific to a downstream task with labeled examples, a small number of such examples is appended to a prompt instruction for controlling the decoder's generation process. ICL, thus, is conceptually similar to a non-parametric approach, such as $k$-NN, where the prediction for each instance essentially depends on the local topology, i.e., on a localised set of similar instances and their labels (called few-shot examples). This suggests that a test instance in ICL is analogous to a query in IR, and similar examples in ICL retrieved from a training set relate to a set of documents retrieved from a collection in IR. While standard unsupervised ranking models can be used to retrieve these few-shot examples from a training set, the effectiveness of the examples can potentially be improved by re-defining the notion of relevance specific to its utility for the downstream task, i.e., considering an example to be relevant if including it in the prompt instruction leads to a correct prediction. With this task-specific notion of relevance, it is possible to train a supervised ranking model (e.g., a bi-encoder or cross-encoder), which potentially learns to optimally select the few-shot examples. We believe that the recent advances in neural rankers can potentially find a use case for this task of optimally choosing examples for more effective downstream ICL predictions.
5/3/2024