Distributed-Memory Parallel Algorithms for Sparse Matrix and Sparse Tall-and-Skinny Matrix Multiplication

0
Sign in to get full access
Overview
- This paper presents distributed-memory parallel algorithms for sparse matrix and sparse tall-and-skinny matrix multiplication.
- The algorithms are designed to efficiently utilize the memory and communication resources in a distributed computing environment.
- The paper evaluates the performance of the proposed algorithms through experimental analysis and comparison with state-of-the-art methods.
Plain English Explanation
The paper discusses efficient ways to perform mathematical operations called "matrix multiplication" on large, sparse datasets that are distributed across multiple computers. Matrix multiplication is a fundamental operation in many scientific and machine learning applications, but it can be computationally intensive, especially when working with sparse data.
The researchers develop new algorithms that can effectively utilize the memory and communication capabilities of a distributed computing system to speed up sparse matrix multiplication. This is important because many real-world datasets, like social networks or web graphs, are sparse, meaning they have a lot of empty or zero-valued entries. Traditional matrix multiplication algorithms are not well-suited for these sparse datasets, so new approaches are needed.
The paper evaluates the performance of the proposed algorithms through experiments, comparing them to existing state-of-the-art methods. The results show that the new algorithms can significantly improve the efficiency and speed of sparse matrix multiplication in a distributed computing environment.
Technical Explanation
The paper introduces two new distributed-memory parallel algorithms for sparse matrix and sparse tall-and-skinny matrix multiplication:
-
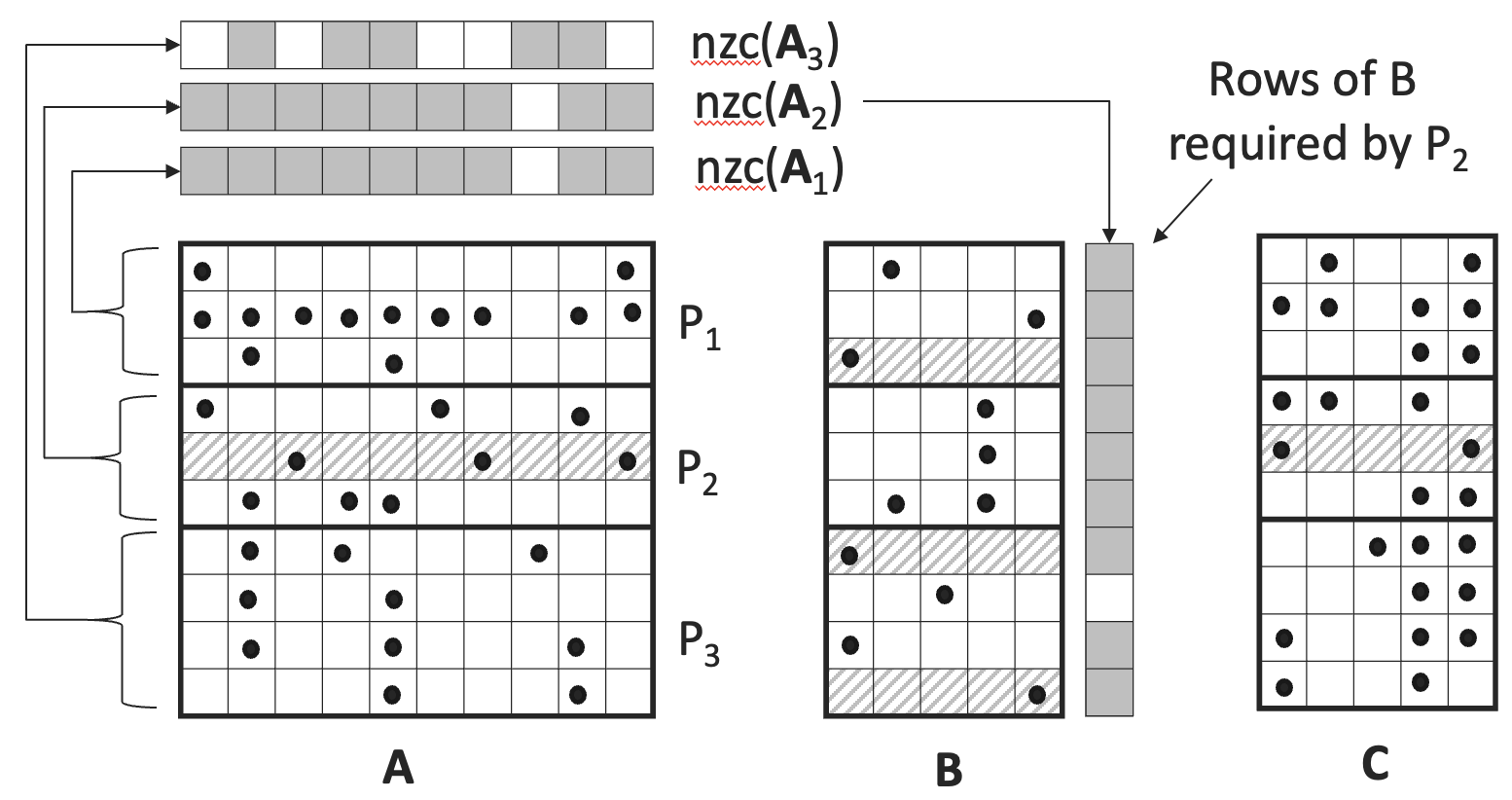
Sparse Matrix Multiplication (SpMM) Algorithm: This algorithm is designed to efficiently compute the product of a sparse matrix and a dense matrix in a distributed setting. It uses a combination of techniques, including load balancing, communication optimization, and exploiting the sparsity structure of the input matrices.
-
Sparse Tall-and-Skinny Matrix Multiplication (SpTSMM) Algorithm: This algorithm targets the multiplication of a sparse tall-and-skinny matrix (a matrix with many more rows than columns) and a dense matrix. It employs strategies to minimize communication and memory requirements, making it well-suited for large-scale applications.
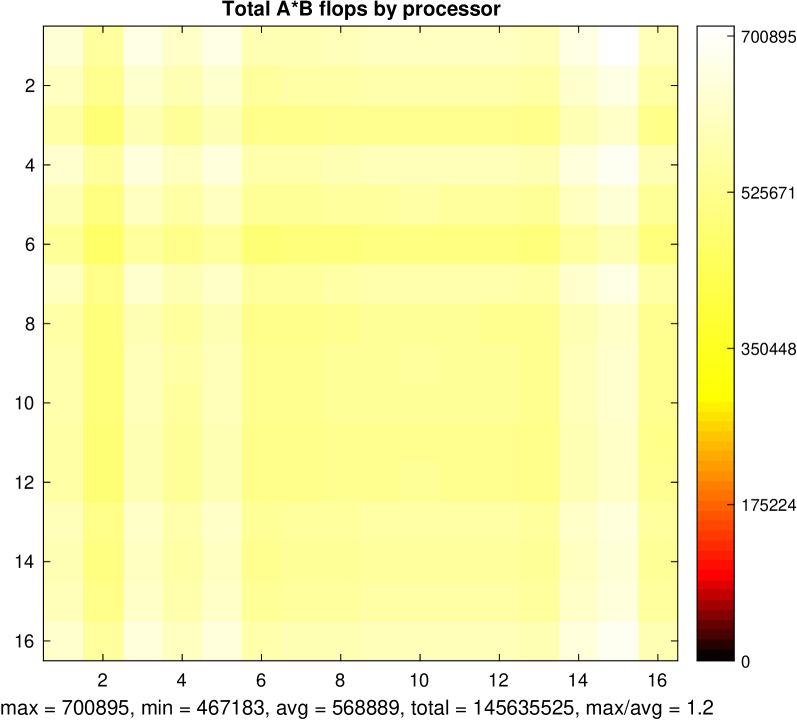
The paper provides a detailed analysis of the algorithms, including their communication and computational complexities. It also includes extensive experimental evaluations on various sparse matrix datasets, comparing the performance of the proposed algorithms against state-of-the-art methods, such as MKL BLAS, Sparse BLAS, and other distributed matrix multiplication approaches.
The results demonstrate that the new algorithms can significantly outperform existing methods, especially for large-scale sparse matrix and sparse tall-and-skinny matrix multiplication problems. The performance advantages are achieved through the effective utilization of distributed computing resources and the exploitation of the inherent sparsity patterns in the input data.
Critical Analysis
The paper presents a thorough and well-designed study of distributed-memory parallel algorithms for sparse matrix and sparse tall-and-skinny matrix multiplication. The proposed algorithms are theoretically sound and the experimental evaluation is comprehensive, providing strong evidence for the effectiveness of the approaches.
However, the paper does not discuss potential limitations or caveats of the algorithms. For example, it would be helpful to understand the sensitivity of the algorithms to the specific sparsity patterns or dimensions of the input matrices, as well as the scalability of the approaches to very large-scale distributed computing environments.
Additionally, the paper could have explored the integration of the proposed algorithms with existing sparse matrix libraries or machine learning frameworks, which would help assess their practical applicability and ease of adoption in real-world scenarios.
Further research could also investigate the combination of the proposed algorithms with other optimization techniques, such as specialized hardware acceleration or advanced data partitioning strategies, to push the boundaries of sparse matrix multiplication performance even further.
Conclusion
This paper presents innovative distributed-memory parallel algorithms for sparse matrix and sparse tall-and-skinny matrix multiplication. The proposed approaches leverage the memory and communication capabilities of a distributed computing environment to significantly improve the efficiency and speed of these fundamental linear algebra operations on large, sparse datasets.
The experimental results demonstrate the effectiveness of the new algorithms, which outperform state-of-the-art methods across a variety of sparse matrix datasets. This work contributes valuable insights and practical solutions for accelerating sparse matrix computations, which are crucial for numerous scientific and machine learning applications that rely on the processing of large-scale, sparse data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Distributed-Memory Parallel Algorithms for Sparse Matrix and Sparse Tall-and-Skinny Matrix Multiplication
Isuru Ranawaka, Md Taufique Hussain, Charles Block, Gerasimos Gerogiannis, Josep Torrellas, Ariful Azad
We consider a sparse matrix-matrix multiplication (SpGEMM) setting where one matrix is square and the other is tall and skinny. This special variant, called TS-SpGEMM, has important applications in multi-source breadth-first search, influence maximization, sparse graph embedding, and algebraic multigrid solvers. Unfortunately, popular distributed algorithms like sparse SUMMA deliver suboptimal performance for TS-SpGEMM. To address this limitation, we develop a novel distributed-memory algorithm tailored for TS-SpGEMM. Our approach employs customized 1D partitioning for all matrices involved and leverages sparsity-aware tiling for efficient data transfers. In addition, it minimizes communication overhead by incorporating both local and remote computations. On average, our TS-SpGEMM algorithm attains 5x performance gains over 2D and 3D SUMMA. Furthermore, we use our algorithm to implement multi-source breadth-first search and sparse graph embedding algorithms and demonstrate their scalability up to 512 Nodes (or 65,536 cores) on NERSC Perlmutter.
Read more8/23/2024

0
A sparsity-aware distributed-memory algorithm for sparse-sparse matrix multiplication
Yuxi Hong, Aydin Buluc
Multiplying two sparse matrices (SpGEMM) is a common computational primitive used in many areas including graph algorithms, bioinformatics, algebraic multigrid solvers, and randomized sketching. Distributed-memory parallel algorithms for SpGEMM have mainly focused on sparsity-oblivious approaches that use 2D and 3D partitioning. Sparsity-aware 1D algorithms can theoretically reduce communication by not fetching nonzeros of the sparse matrices that do not participate in the multiplication. Here, we present a distributed-memory 1D SpGEMM algorithm and implementation. It uses MPI RDMA operations to mitigate the cost of packing/unpacking submatrices for communication, and it uses a block fetching strategy to avoid excessive fine-grained messaging. Our results show that our 1D implementation outperforms state-of-the-art 2D and 3D implementations within CombBLAS for many configurations, inputs, and use cases, while remaining conceptually simpler.
Read more8/28/2024
0
RDMA-Based Algorithms for Sparse Matrix Multiplication on GPUs
Benjamin Brock, Ayd{i}n Buluc{c}, Katherine Yelick
Sparse matrix multiplication is an important kernel for large-scale graph processing and other data-intensive applications. In this paper, we implement various asynchronous, RDMA-based sparse times dense (SpMM) and sparse times sparse (SpGEMM) algorithms, evaluating their performance running in a distributed memory setting on GPUs. Our RDMA-based implementations use the NVSHMEM communication library for direct, asynchronous one-sided communication between GPUs. We compare our asynchronous implementations to state-of-the-art bulk synchronous GPU libraries as well as a CUDA-aware MPI implementation of the SUMMA algorithm. We find that asynchronous RDMA-based implementations are able to offer favorable performance compared to bulk synchronous implementations, while also allowing for the straightforward implementation of novel work stealing algorithms.
Read more6/4/2024
0
Low-Bandwidth Matrix Multiplication: Faster Algorithms and More General Forms of Sparsity
Chetan Gupta, Janne H. Korhonen, Jan Studen'y, Jukka Suomela, Hossein Vahidi
In prior work, Gupta et al. (SPAA 2022) presented a distributed algorithm for multiplying sparse $n times n$ matrices, using $n$ computers. They assumed that the input matrices are uniformly sparse--there are at most $d$ non-zeros in each row and column--and the task is to compute a uniformly sparse part of the product matrix. The sparsity structure is globally known in advance (this is the supported setting). As input, each computer receives one row of each input matrix, and each computer needs to output one row of the product matrix. In each communication round each computer can send and receive one $O(log n)$-bit message. Their algorithm solves this task in $O(d^{1.907})$ rounds, while the trivial bound is $O(d^2)$. We improve on the prior work in two dimensions: First, we show that we can solve the same task faster, in only $O(d^{1.832})$ rounds. Second, we explore what happens when matrices are not uniformly sparse. We consider the following alternative notions of sparsity: row-sparse matrices (at most $d$ non-zeros per row), column-sparse matrices, matrices with bounded degeneracy (we can recursively delete a row or column with at most $d$ non-zeros), average-sparse matrices (at most $dn$ non-zeros in total), and general matrices.
Read more5/24/2024