RDMA-Based Algorithms for Sparse Matrix Multiplication on GPUs

0
Sign in to get full access
Overview
- This paper presents RDMA-based algorithms for performing sparse matrix multiplication on GPUs.
- The key focus is on improving the performance and efficiency of this important computational task.
- The researchers leverage Remote Direct Memory Access (RDMA) capabilities to enable faster data transfer between GPU devices.
Plain English Explanation
The paper explores ways to speed up the process of multiplying sparse matrices on graphics processing units (GPUs). Sparse matrices are matrices that contain mostly zero values, which makes them inefficient to work with using traditional methods.
The researchers developed new algorithms that take advantage of a technology called Remote Direct Memory Access (RDMA). RDMA allows different computers to share memory quickly without involving the main processors. By using RDMA, the GPU devices can transfer data between each other more efficiently when performing the matrix multiplication.
This is important because sparse matrix multiplication is a fundamental operation used in many scientific and machine learning applications. Improving the speed and efficiency of this operation can lead to significant performance gains in those domains. The new RDMA-based algorithms provide a way to accelerate sparse matrix multiplication on GPU clusters, which is valuable for researchers and engineers working on large-scale computational problems.
Technical Explanation
The paper presents two RDMA-based algorithms for sparse matrix multiplication on GPU clusters: RDMA-CSRMM and RDMA-CSRMV.
RDMA-CSRMM is designed for multiplying a sparse matrix with a dense matrix, while RDMA-CSRMV targets the multiplication of a sparse matrix with a dense vector. Both algorithms leverage the RDMA capabilities of the GPUs to enable faster data transfer between devices during the computation.
The key innovations include:
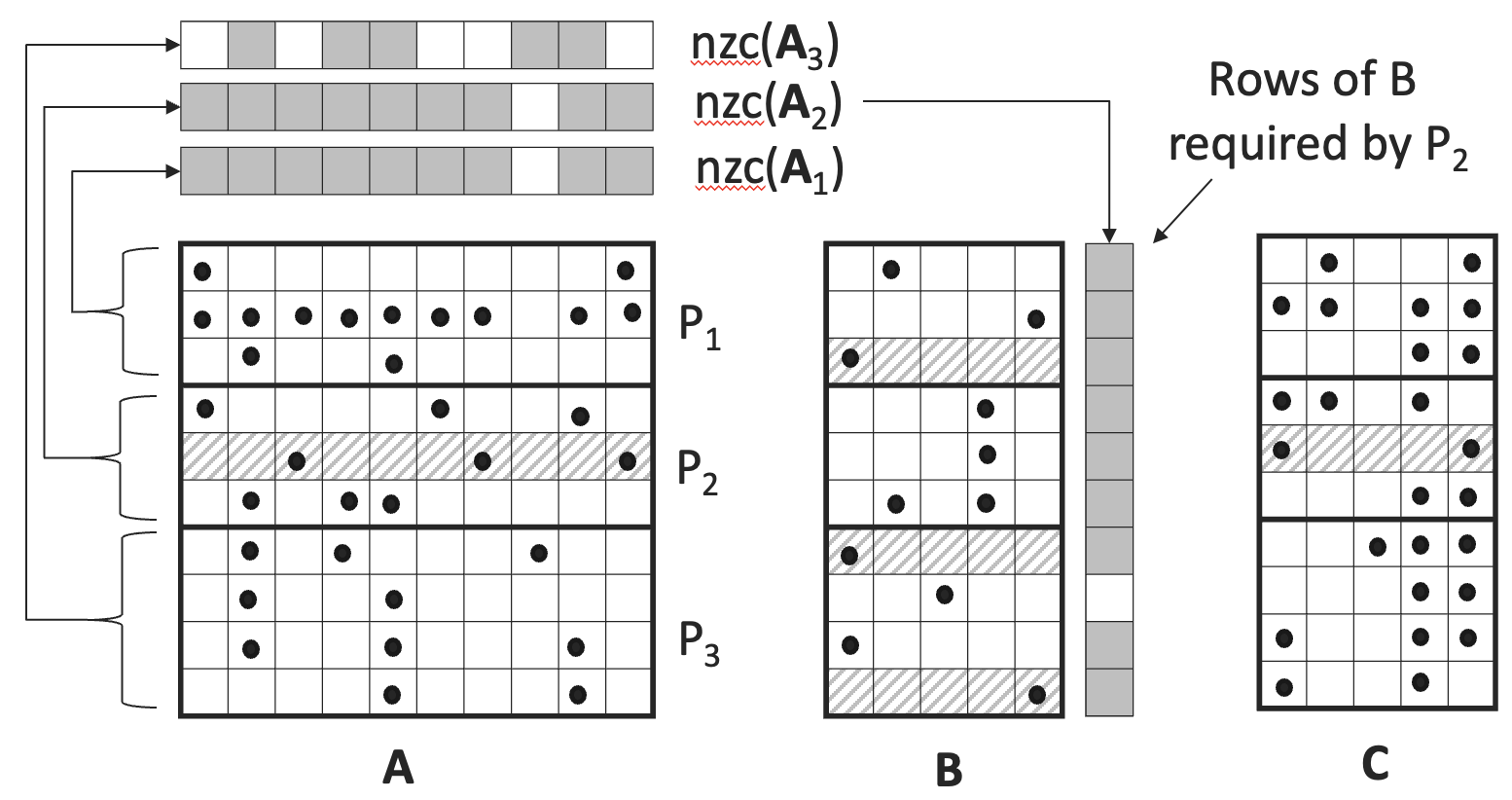
- A cache-blocking technique to optimize memory access patterns and improve data locality.
- A 3D sparse communication pattern to reduce the volume of data transferred between GPUs.
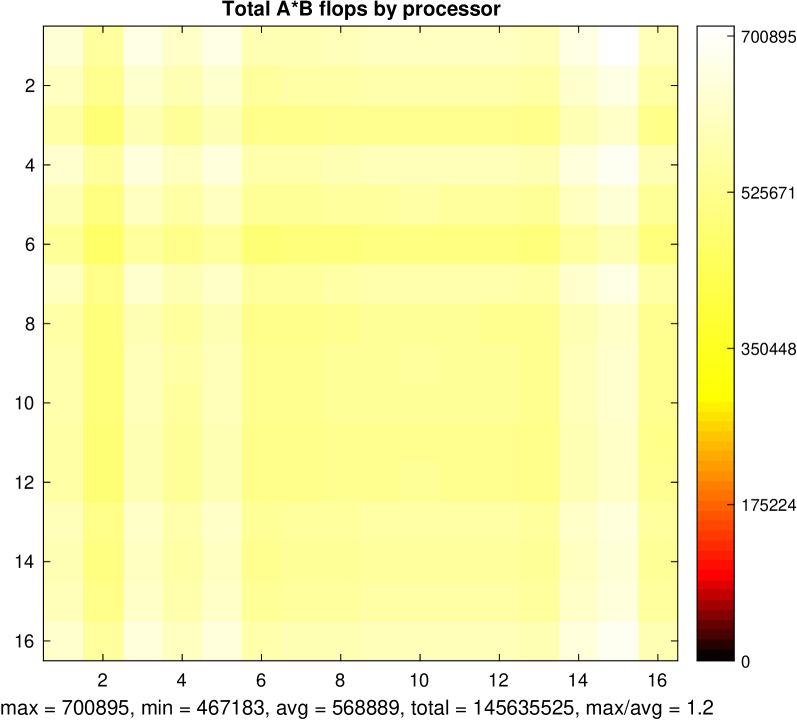
- Load balancing strategies to distribute the workload evenly across the GPU devices.
The researchers evaluate the performance of their algorithms on a variety of sparse matrix datasets and compare them to state-of-the-art alternatives. The results demonstrate significant speedups, reaching up to 5.6x improvement for RDMA-CSRMM and 4.7x for RDMA-CSRMV.
Critical Analysis
The paper presents a well-designed and thorough study of RDMA-based sparse matrix multiplication algorithms on GPUs. The researchers have clearly identified a performance bottleneck in this important computation and have proposed novel solutions to address it.
One potential limitation is the reliance on RDMA-capable hardware, which may not be widely available in all computing environments. The authors acknowledge this and suggest that future work could explore ways to achieve similar performance gains without requiring specialized hardware.
Additionally, the paper does not provide a detailed analysis of the communication patterns and data movement between the GPU devices. While the 3D sparse communication approach is described, a more in-depth examination of the trade-offs and potential optimization opportunities in this area could be valuable.
Overall, the research presented in this paper represents a significant contribution to the field of high-performance computing and GPU-accelerated sparse matrix operations. The RDMA-based algorithms offer a promising path for improving the efficiency of large-scale computational tasks that rely on sparse matrix multiplication.
Conclusion
This paper introduces RDMA-based algorithms for performing sparse matrix multiplication on GPU clusters. By leveraging the RDMA capabilities of modern GPUs, the researchers were able to develop more efficient data transfer mechanisms and achieve significant performance improvements compared to state-of-the-art methods.
The proposed algorithms, RDMA-CSRMM and RDMA-CSRMV, demonstrate the potential of RDMA technology to accelerate important computational workloads in scientific computing and machine learning. As the demand for high-performance sparse matrix operations continues to grow, the insights and techniques presented in this paper will be valuable for researchers and practitioners working to push the boundaries of what is possible with GPU-accelerated computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RDMA-Based Algorithms for Sparse Matrix Multiplication on GPUs
Benjamin Brock, Ayd{i}n Buluc{c}, Katherine Yelick
Sparse matrix multiplication is an important kernel for large-scale graph processing and other data-intensive applications. In this paper, we implement various asynchronous, RDMA-based sparse times dense (SpMM) and sparse times sparse (SpGEMM) algorithms, evaluating their performance running in a distributed memory setting on GPUs. Our RDMA-based implementations use the NVSHMEM communication library for direct, asynchronous one-sided communication between GPUs. We compare our asynchronous implementations to state-of-the-art bulk synchronous GPU libraries as well as a CUDA-aware MPI implementation of the SUMMA algorithm. We find that asynchronous RDMA-based implementations are able to offer favorable performance compared to bulk synchronous implementations, while also allowing for the straightforward implementation of novel work stealing algorithms.
Read more6/4/2024
0
Distributed-Memory Parallel Algorithms for Sparse Matrix and Sparse Tall-and-Skinny Matrix Multiplication
Isuru Ranawaka, Md Taufique Hussain, Charles Block, Gerasimos Gerogiannis, Josep Torrellas, Ariful Azad
We consider a sparse matrix-matrix multiplication (SpGEMM) setting where one matrix is square and the other is tall and skinny. This special variant, called TS-SpGEMM, has important applications in multi-source breadth-first search, influence maximization, sparse graph embedding, and algebraic multigrid solvers. Unfortunately, popular distributed algorithms like sparse SUMMA deliver suboptimal performance for TS-SpGEMM. To address this limitation, we develop a novel distributed-memory algorithm tailored for TS-SpGEMM. Our approach employs customized 1D partitioning for all matrices involved and leverages sparsity-aware tiling for efficient data transfers. In addition, it minimizes communication overhead by incorporating both local and remote computations. On average, our TS-SpGEMM algorithm attains 5x performance gains over 2D and 3D SUMMA. Furthermore, we use our algorithm to implement multi-source breadth-first search and sparse graph embedding algorithms and demonstrate their scalability up to 512 Nodes (or 65,536 cores) on NERSC Perlmutter.
Read more8/23/2024

0
A sparsity-aware distributed-memory algorithm for sparse-sparse matrix multiplication
Yuxi Hong, Aydin Buluc
Multiplying two sparse matrices (SpGEMM) is a common computational primitive used in many areas including graph algorithms, bioinformatics, algebraic multigrid solvers, and randomized sketching. Distributed-memory parallel algorithms for SpGEMM have mainly focused on sparsity-oblivious approaches that use 2D and 3D partitioning. Sparsity-aware 1D algorithms can theoretically reduce communication by not fetching nonzeros of the sparse matrices that do not participate in the multiplication. Here, we present a distributed-memory 1D SpGEMM algorithm and implementation. It uses MPI RDMA operations to mitigate the cost of packing/unpacking submatrices for communication, and it uses a block fetching strategy to avoid excessive fine-grained messaging. Our results show that our 1D implementation outperforms state-of-the-art 2D and 3D implementations within CombBLAS for many configurations, inputs, and use cases, while remaining conceptually simpler.
Read more8/28/2024

0
High Performance Unstructured SpMM Computation Using Tensor Cores
Patrik Okanovic, Grzegorz Kwasniewski, Paolo Sylos Labini, Maciej Besta, Flavio Vella, Torsten Hoefler
High-performance sparse matrix-matrix (SpMM) multiplication is paramount for science and industry, as the ever-increasing sizes of data prohibit using dense data structures. Yet, existing hardware, such as Tensor Cores (TC), is ill-suited for SpMM, as it imposes strict constraints on data structures that cannot be met by unstructured sparsity found in many applications. To address this, we introduce (S)parse (Ma)trix Matrix (T)ensor Core-accelerated (SMaT): a novel SpMM library that utilizes TCs for unstructured sparse matrices. Our block-sparse library leverages the low-level CUDA MMA (matrix-matrix-accumulate) API, maximizing the performance offered by modern GPUs. Algorithmic optimizations such as sparse matrix permutation further improve performance by minimizing the number of non-zero blocks. The evaluation on NVIDIA A100 shows that SMaT outperforms SotA libraries (DASP, cuSPARSE, and Magicube) by up to 125x (on average 2.6x). SMaT can be used to accelerate many workloads in scientific computing, large-model training, inference, and others.
Read more8/22/2024