A sparsity-aware distributed-memory algorithm for sparse-sparse matrix multiplication

0

Sign in to get full access
Overview
- This paper presents a sparsity-aware distributed-memory algorithm for sparse-sparse matrix multiplication (SpGEMM).
- The algorithm is designed to efficiently perform SpGEMM operations on large-scale distributed-memory systems.
- It leverages the sparsity structure of the input matrices to reduce communication and computation costs.
Plain English Explanation
Multiplying two sparse matrices (matrices with many zero values) can be a computationally intensive task, especially when working with large datasets across multiple computers. This paper introduces a algorithm for sparse-sparse matrix multiplication that is designed to take advantage of the sparsity of the input matrices to improve efficiency.
The key idea is to distribute the input matrices across multiple computers, and then use the sparsity structure of the matrices to minimize the amount of data that needs to be communicated between the computers during the multiplication process. By reducing communication, the algorithm can achieve faster overall performance, particularly on large-scale distributed-memory systems.
The paper also discusses how the algorithm can be implemented using RDMA (Remote Direct Memory Access) technology, which allows for efficient data transfer between computers without burdening the central processing units (CPUs).
Technical Explanation
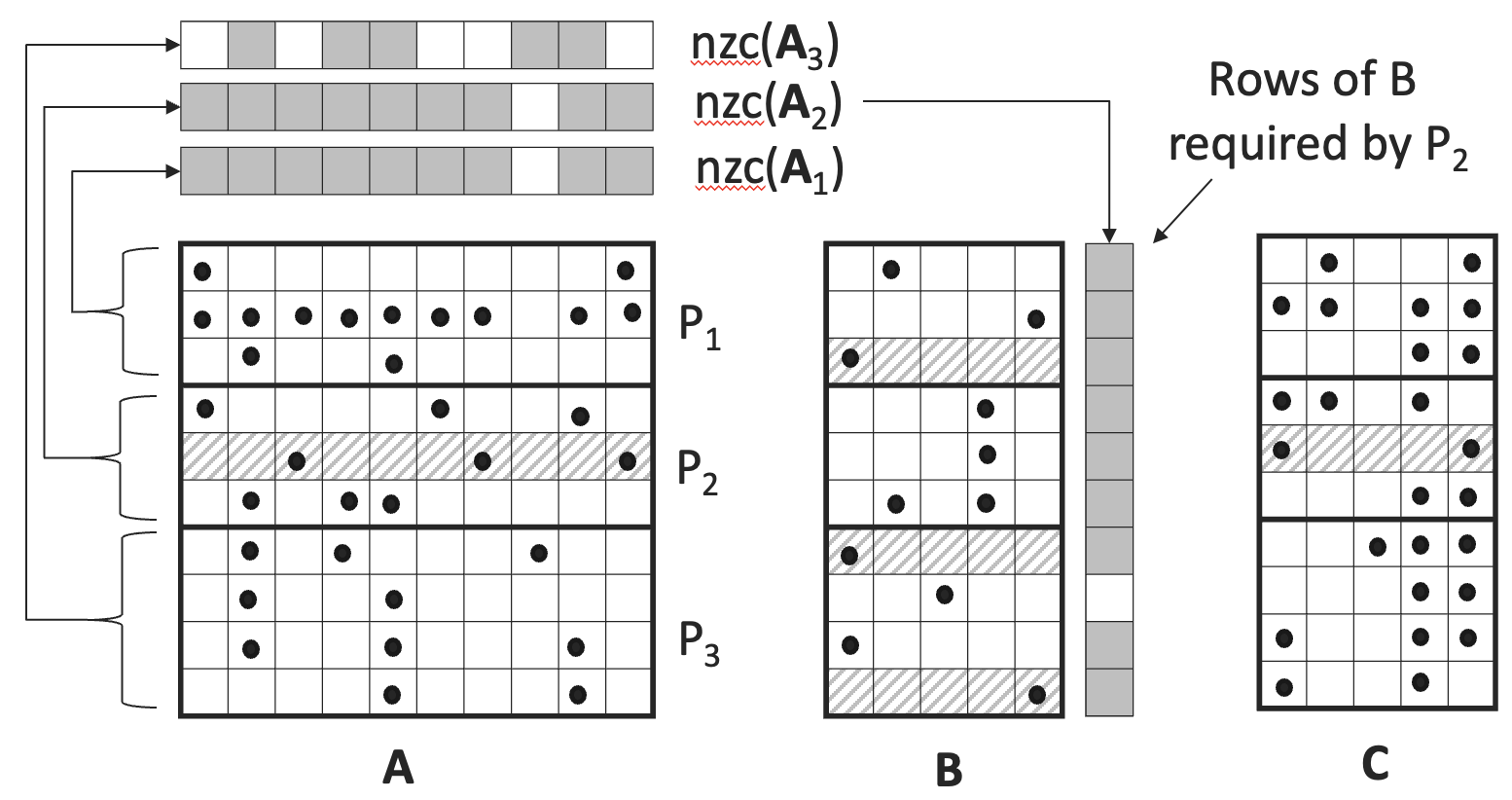
The proposed algorithm is a 1D SpGEMM algorithm that distributes the input matrices across multiple computers in a row-wise fashion. The key steps of the algorithm are:
- Partitioning: The input matrices are partitioned and distributed across the available computers, with each computer holding a subset of the rows.
- Local Multiplication: Each computer performs a local sparse-sparse matrix multiplication on its assigned rows, producing partial results.
- Communication: The partial results are then communicated between the computers using RDMA to perform the final summation and produce the overall result.
The algorithm is designed to be sparsity-aware, meaning it takes advantage of the sparsity structure of the input matrices to minimize communication and computation costs. This is achieved through techniques such as:
- Selective communication: Only the non-zero elements of the partial results are communicated between computers, reducing the overall data transfer volume.
- Asynchronous communication: The communication of partial results is overlapped with the local computation, improving overall throughput.
- Load balancing: The workload is distributed across the computers based on the sparsity structure of the input matrices, helping to ensure efficient utilization of the available computing resources.
The paper presents experimental results demonstrating the performance advantages of the proposed algorithm compared to existing approaches, particularly for large-scale, sparse-sparse matrix multiplication problems.
Critical Analysis
The paper provides a thorough and well-designed algorithm for sparse-sparse matrix multiplication in distributed-memory environments. The authors have addressed several key challenges, such as minimizing communication overhead and ensuring load balance, which are critical for achieving high performance on large-scale systems.
One potential limitation of the approach is that it may not be as effective for dense or semi-sparse matrices, as the sparsity-aware optimizations may not provide as much benefit in those cases. Additionally, the algorithm's performance may be dependent on the specific sparsity structure of the input matrices, and it may not be as effective for certain types of sparse matrices.
Further research could explore extensions or variations of the algorithm to address a wider range of matrix types and problem sizes, or to investigate alternative communication strategies that could further improve performance.
Conclusion
This paper presents a sparsity-aware distributed-memory algorithm for sparse-sparse matrix multiplication that leverages the sparsity structure of the input matrices to reduce communication and computation costs. The algorithm is designed to achieve high performance on large-scale, distributed-memory systems, and the experimental results demonstrate its advantages over existing approaches.
The proposed algorithm represents an important contribution to the field of numerical linear algebra, particularly in the context of parallel and distributed computing. By optimizing the performance of sparse-sparse matrix multiplication, the algorithm can enable more efficient and scalable solutions for a wide range of applications, from scientific computing to machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A sparsity-aware distributed-memory algorithm for sparse-sparse matrix multiplication
Yuxi Hong, Aydin Buluc
Multiplying two sparse matrices (SpGEMM) is a common computational primitive used in many areas including graph algorithms, bioinformatics, algebraic multigrid solvers, and randomized sketching. Distributed-memory parallel algorithms for SpGEMM have mainly focused on sparsity-oblivious approaches that use 2D and 3D partitioning. Sparsity-aware 1D algorithms can theoretically reduce communication by not fetching nonzeros of the sparse matrices that do not participate in the multiplication. Here, we present a distributed-memory 1D SpGEMM algorithm and implementation. It uses MPI RDMA operations to mitigate the cost of packing/unpacking submatrices for communication, and it uses a block fetching strategy to avoid excessive fine-grained messaging. Our results show that our 1D implementation outperforms state-of-the-art 2D and 3D implementations within CombBLAS for many configurations, inputs, and use cases, while remaining conceptually simpler.
Read more8/28/2024
0
Distributed-Memory Parallel Algorithms for Sparse Matrix and Sparse Tall-and-Skinny Matrix Multiplication
Isuru Ranawaka, Md Taufique Hussain, Charles Block, Gerasimos Gerogiannis, Josep Torrellas, Ariful Azad
We consider a sparse matrix-matrix multiplication (SpGEMM) setting where one matrix is square and the other is tall and skinny. This special variant, called TS-SpGEMM, has important applications in multi-source breadth-first search, influence maximization, sparse graph embedding, and algebraic multigrid solvers. Unfortunately, popular distributed algorithms like sparse SUMMA deliver suboptimal performance for TS-SpGEMM. To address this limitation, we develop a novel distributed-memory algorithm tailored for TS-SpGEMM. Our approach employs customized 1D partitioning for all matrices involved and leverages sparsity-aware tiling for efficient data transfers. In addition, it minimizes communication overhead by incorporating both local and remote computations. On average, our TS-SpGEMM algorithm attains 5x performance gains over 2D and 3D SUMMA. Furthermore, we use our algorithm to implement multi-source breadth-first search and sparse graph embedding algorithms and demonstrate their scalability up to 512 Nodes (or 65,536 cores) on NERSC Perlmutter.
Read more8/23/2024
0
RDMA-Based Algorithms for Sparse Matrix Multiplication on GPUs
Benjamin Brock, Ayd{i}n Buluc{c}, Katherine Yelick
Sparse matrix multiplication is an important kernel for large-scale graph processing and other data-intensive applications. In this paper, we implement various asynchronous, RDMA-based sparse times dense (SpMM) and sparse times sparse (SpGEMM) algorithms, evaluating their performance running in a distributed memory setting on GPUs. Our RDMA-based implementations use the NVSHMEM communication library for direct, asynchronous one-sided communication between GPUs. We compare our asynchronous implementations to state-of-the-art bulk synchronous GPU libraries as well as a CUDA-aware MPI implementation of the SUMMA algorithm. We find that asynchronous RDMA-based implementations are able to offer favorable performance compared to bulk synchronous implementations, while also allowing for the straightforward implementation of novel work stealing algorithms.
Read more6/4/2024
❗
0
Fast multiplication of random dense matrices with fixed sparse matrices
Tianyu Liang, Riley Murray, Ayd{i}n Buluc{c}, James Demmel
This work focuses on accelerating the multiplication of a dense random matrix with a (fixed) sparse matrix, which is frequently used in sketching algorithms. We develop a novel scheme that takes advantage of blocking and recomputation (on-the-fly random number generation) to accelerate this operation. The techniques we propose decrease memory movement, thereby increasing the algorithm's parallel scalability in shared memory architectures. On the Intel Frontera architecture, our algorithm can achieve 2x speedups over libraries such as Eigen and Intel MKL on some examples. In addition, with 32 threads, we can obtain a parallel efficiency of up to approximately 45%. We also present a theoretical analysis for the memory movement lower bound of our algorithm, showing that under mild assumptions, it's possible to beat the data movement lower bound of general matrix-matrix multiply (GEMM) by a factor of $sqrt M$, where $M$ is the cache size. Finally, we incorporate our sketching algorithm into a randomized least squares solver. For extremely over-determined sparse input matrices, we show that our results are competitive with SuiteSparse; in some cases, we obtain a speedup of 10x over SuiteSparse.
Read more5/14/2024