Diversify and Conquer: Diversity-Centric Data Selection with Iterative Refinement

0

Sign in to get full access
Overview
- The research paper "Diversify and Conquer: Diversity-Centric Data Selection with Iterative Refinement" proposes a new method for selecting diverse training data to improve model performance.
- The key ideas are: 1) using diversity as the primary objective for data selection, and 2) iteratively refining the selected data to further increase diversity.
- The authors demonstrate the effectiveness of their approach on language modeling and image classification tasks.
Plain English Explanation
When training machine learning models, the choice of training data is crucial. Typically, the goal is to select data that is representative of the real-world distribution the model will encounter. However, a common problem is that the available training data may not fully capture this distribution.
The authors of this paper propose a new approach called "Diversify and Conquer" to address this issue. The key idea is to select a diverse set of training examples, rather than just focusing on representativeness. By ensuring the training data covers a wide range of possible inputs, the model can learn a more robust and generalizable set of patterns.
The method works by first selecting a diverse subset of the available data using an optimization algorithm. It then iteratively refines this selection, further increasing the diversity at each step. This allows the method to progressively hone in on the most informative and diverse training examples.
The authors demonstrate the effectiveness of their approach on language modeling and image classification tasks. They show that models trained on data selected using their "Diversify and Conquer" method outperform those trained on data selected using traditional approaches.
Technical Explanation
The authors propose a two-stage "Diversify and Conquer" framework for data selection. In the first stage, they use a diversity-based objective to select an initial diverse subset of the available training data. This objective encourages the selected examples to be as different from each other as possible, based on some chosen similarity metric.
In the second stage, the authors iteratively refine the selected data subset. At each iteration, they re-evaluate the diversity of the current selection and make targeted additions or removals to further increase the overall diversity. This allows the method to progressively home in on the most informative and diverse examples.
The authors evaluate their approach on language modeling and image classification tasks. They show that models trained on data selected using "Diversify and Conquer" achieve better performance compared to models trained on data selected using more traditional approaches, such as random sampling or uncertainty-based selection.
Critical Analysis
The authors acknowledge several limitations of their work. First, the diversity metric used in their method is task-dependent and requires careful tuning. Using a suboptimal diversity metric could lead to poor performance.
Additionally, the iterative refinement process can be computationally expensive, as it requires repeatedly evaluating the diversity of the selected data. This may limit the scalability of the method to very large datasets.
The authors also note that their approach assumes the available training data, while potentially incomplete, is still representative of the true data distribution. If this assumption is violated, the "Diversify and Conquer" method may not be as effective.
Further research could explore ways to make the diversity metric more general and less task-dependent, as well as techniques to reduce the computational cost of the iterative refinement process. Investigating the performance of the method when the available training data is not representative of the true distribution could also be a valuable area of study.
Conclusion
The "Diversify and Conquer" method proposed in this paper offers a promising approach to data selection for training machine learning models. By focusing on diversity rather than just representativeness, the method can help improve model performance and generalization, as demonstrated in the language modeling and image classification experiments.
While the method has some limitations, the core idea of using diversity as the primary objective for data selection is a valuable contribution to the field of machine learning. Further research and refinement of this approach could lead to even more effective data selection strategies, with potential benefits for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Diversify and Conquer: Diversity-Centric Data Selection with Iterative Refinement
Simon Yu, Liangyu Chen, Sara Ahmadian, Marzieh Fadaee
Finetuning large language models on instruction data is crucial for enhancing pre-trained knowledge and improving instruction-following capabilities. As instruction datasets proliferate, selecting optimal data for effective training becomes increasingly important. This work addresses the question: How can we determine the optimal subset of data for effective training? While existing research often emphasizes local criteria like instance quality for subset selection, we argue that a global approach focused on data diversity is more critical. Our method employs k-means clustering to ensure the selected subset effectively represents the full dataset. We propose an iterative refinement method inspired by active learning techniques to resample instances from clusters, reassessing each cluster's importance and sampling weight in every training iteration. This approach reduces the effect of outliers and automatically filters out clusters containing low-quality data. Through extensive evaluation across natural language reasoning, general world knowledge, code and math reasoning tasks, and by fine-tuning models from various families, we observe consistent improvements, achieving a 7% increase over random selection and a 3.8% improvement over state-of-the-art sampling methods. Our work highlights the significance of diversity-first sampling when finetuning LLMs to enhance performance across a broad array of evaluation tasks. Our code is available at https://github.com/for-ai/iterative-data-selection.
Read more9/18/2024
📊
0
G-DIG: Towards Gradient-based DIverse and hiGh-quality Instruction Data Selection for Machine Translation
Xingyuan Pan, Luyang Huang, Liyan Kang, Zhicheng Liu, Yu Lu, Shanbo Cheng
Large Language Models (LLMs) have demonstrated remarkable abilities in general scenarios. Instruction finetuning empowers them to align with humans in various tasks. Nevertheless, the Diversity and Quality of the instruction data remain two main challenges for instruction finetuning. With regard to this, in this paper, we propose a novel gradient-based method to automatically select high-quality and diverse instruction finetuning data for machine translation. Our key innovation centers around analyzing how individual training examples influence the model during training. Specifically, we select training examples that exert beneficial influences on the model as high-quality ones by means of Influence Function plus a small high-quality seed dataset. Moreover, to enhance the diversity of the training data we maximize the variety of influences they have on the model by clustering on their gradients and resampling. Extensive experiments on WMT22 and FLORES translation tasks demonstrate the superiority of our methods, and in-depth analysis further validates their effectiveness and generalization.
Read more7/9/2024
0
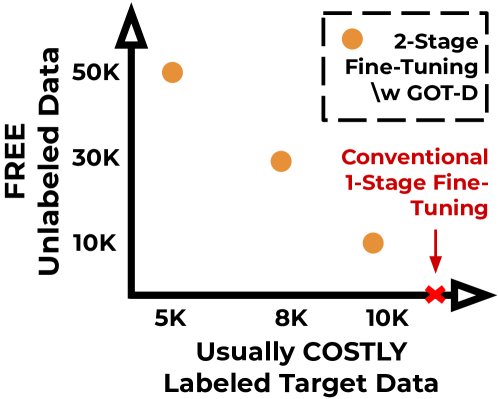
Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs
Feiyang Kang, Hoang Anh Just, Yifan Sun, Himanshu Jahagirdar, Yuanzhi Zhang, Rongxing Du, Anit Kumar Sahu, Ruoxi Jia
This work focuses on leveraging and selecting from vast, unlabeled, open data to pre-fine-tune a pre-trained language model. The goal is to minimize the need for costly domain-specific data for subsequent fine-tuning while achieving desired performance levels. While many data selection algorithms have been designed for small-scale applications, rendering them unsuitable for our context, some emerging methods do cater to language data scales. However, they often prioritize data that aligns with the target distribution. While this strategy may be effective when training a model from scratch, it can yield limited results when the model has already been pre-trained on a different distribution. Differing from prior work, our key idea is to select data that nudges the pre-training distribution closer to the target distribution. We show the optimality of this approach for fine-tuning tasks under certain conditions. We demonstrate the efficacy of our methodology across a diverse array of tasks (NLU, NLG, zero-shot) with models up to 2.7B, showing that it consistently surpasses other selection methods. Moreover, our proposed method is significantly faster than existing techniques, scaling to millions of samples within a single GPU hour. Our code is open-sourced (Code repository: https://anonymous.4open.science/r/DV4LLM-D761/ ). While fine-tuning offers significant potential for enhancing performance across diverse tasks, its associated costs often limit its widespread adoption; with this work, we hope to lay the groundwork for cost-effective fine-tuning, making its benefits more accessible.
Read more5/7/2024
0
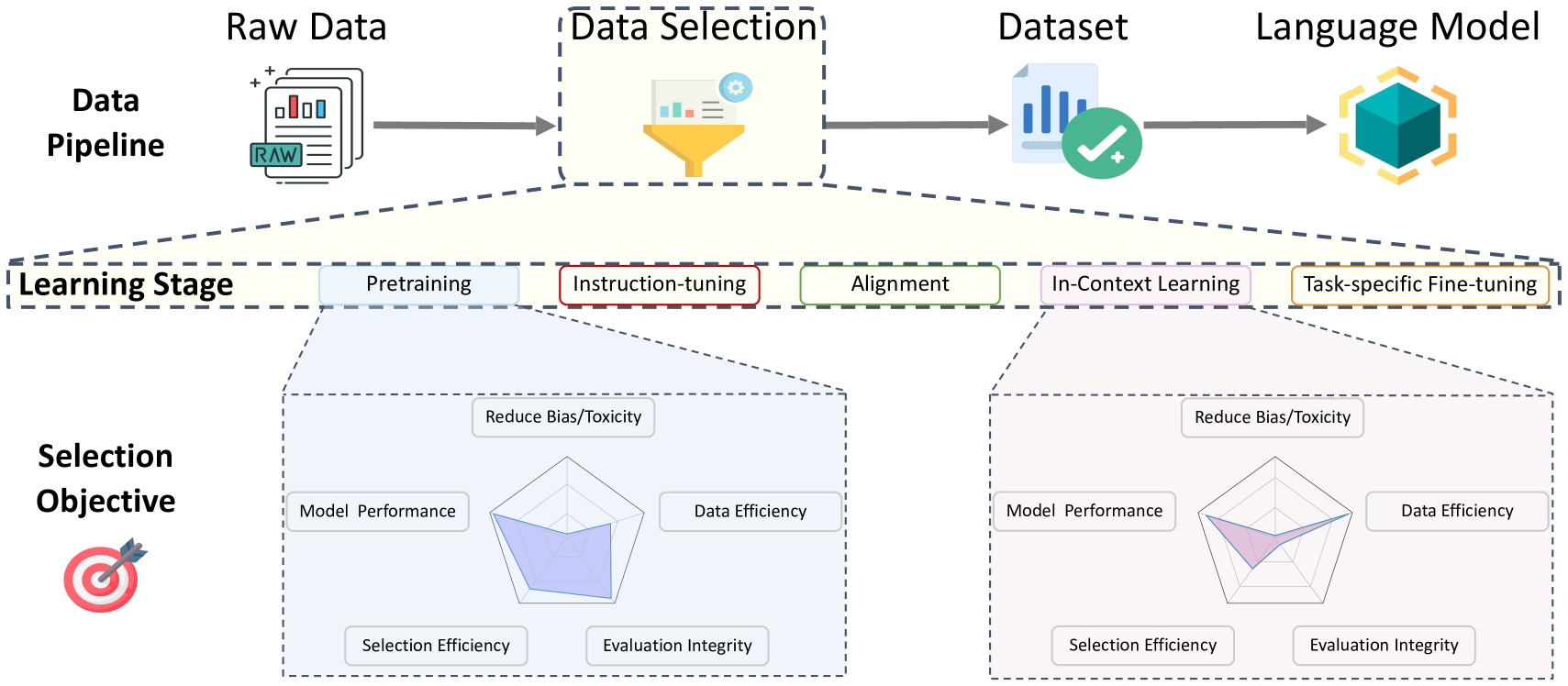
A Survey on Data Selection for Language Models
Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, Colin Raffel, Shiyu Chang, Tatsunori Hashimoto, William Yang Wang
A major factor in the recent success of large language models is the use of enormous and ever-growing text datasets for unsupervised pre-training. However, naively training a model on all available data may not be optimal (or feasible), as the quality of available text data can vary. Filtering out data can also decrease the carbon footprint and financial costs of training models by reducing the amount of training required. Data selection methods aim to determine which candidate data points to include in the training dataset and how to appropriately sample from the selected data points. The promise of improved data selection methods has caused the volume of research in the area to rapidly expand. However, because deep learning is mostly driven by empirical evidence and experimentation on large-scale data is expensive, few organizations have the resources for extensive data selection research. Consequently, knowledge of effective data selection practices has become concentrated within a few organizations, many of which do not openly share their findings and methodologies. To narrow this gap in knowledge, we present a comprehensive review of existing literature on data selection methods and related research areas, providing a taxonomy of existing approaches. By describing the current landscape of research, this work aims to accelerate progress in data selection by establishing an entry point for new and established researchers. Additionally, throughout this review we draw attention to noticeable holes in the literature and conclude the paper by proposing promising avenues for future research.
Read more8/6/2024