On-the-fly Definition Augmentation of LLMs for Biomedical NER
2404.00152
0
0

Abstract
Despite their general capabilities, LLMs still struggle on biomedical NER tasks, which are difficult due to the presence of specialized terminology and lack of training data. In this work we set out to improve LLM performance on biomedical NER in limited data settings via a new knowledge augmentation approach which incorporates definitions of relevant concepts on-the-fly. During this process, to provide a test bed for knowledge augmentation, we perform a comprehensive exploration of prompting strategies. Our experiments show that definition augmentation is useful for both open source and closed LLMs. For example, it leads to a relative improvement of 15% (on average) in GPT-4 performance (F1) across all (six) of our test datasets. We conduct extensive ablations and analyses to demonstrate that our performance improvements stem from adding relevant definitional knowledge. We find that careful prompting strategies also improve LLM performance, allowing them to outperform fine-tuned language models in few-shot settings. To facilitate future research in this direction, we release our code at https://github.com/allenai/beacon.
Create account to get full access
Overview
- This paper explores a technique called "on-the-fly definition augmentation" to improve the performance of large language models (LLMs) on biomedical named entity recognition (NER) tasks.
- The researchers investigate the use of contextual in-context learning (ICL) to enable LLMs to effectively leverage domain-specific knowledge for biomedical NER.
- The study compares the effectiveness of different ICL strategies, including definition augmentation, in boosting LLM performance on biomedical NER benchmarks.
Plain English Explanation
The paper focuses on a way to help large AI language models (LLMs) become better at identifying and extracting important biomedical terms and concepts from text. This is a task called "named entity recognition" (NER) and is useful for applications like automatically indexing and searching medical literature.
The key idea is to give the LLM additional context and information about biomedical terms "on the fly" as it's processing the text. This is done through a technique called "definition augmentation," where the model is provided with brief definitions of the relevant terms alongside the text it's analyzing.
The researchers compare this approach to other ways of using "in-context learning" (ICL) to help the LLM leverage its existing knowledge about the biomedical domain. The goal is to find the most effective way to boost the LLM's performance on biomedical NER tasks without requiring extensive retraining or fine-tuning of the model.
Technical Explanation
The paper investigates the use of contextual in-context learning (ICL) to improve the performance of large language models (LLMs) on biomedical named entity recognition (NER) tasks. The researchers propose a technique called "on-the-fly definition augmentation," where the LLM is provided with definitions of relevant biomedical terms alongside the input text during inference.
The authors compare this definition augmentation approach to other ICL strategies, such as prompt-based fine-tuning and dataset augmentation, in terms of their effectiveness for boosting LLM performance on biomedical NER benchmarks. They also investigate the impact of utilizing structured knowledge bases to enhance the definition augmentation process.
The experiments demonstrate that the proposed definition augmentation technique can significantly improve the biomedical NER capabilities of LLMs, outperforming alternative ICL approaches. The authors attribute this success to the model's ability to effectively leverage domain-specific knowledge through the on-the-fly provision of term definitions.
Critical Analysis
The paper provides a comprehensive evaluation of the proposed definition augmentation approach and its comparison to other ICL strategies for biomedical NER. However, the authors acknowledge that the effectiveness of the technique may be sensitive to the quality and coverage of the term definitions used for augmentation.
Additionally, the study focuses on a limited set of biomedical NER benchmarks, and further research may be needed to assess the generalizability of the findings to a broader range of biomedical tasks and datasets. Exploring the integration of the definition augmentation approach with other NER-specific architectural modifications or pre-training techniques could also be an interesting avenue for future work.
Conclusion
This paper presents a novel approach, called "on-the-fly definition augmentation," to enhance the performance of large language models on biomedical named entity recognition tasks. The key insight is that providing the model with relevant term definitions during inference can effectively leverage its existing domain knowledge and improve its ability to identify and extract important biomedical concepts from text.
The experimental results demonstrate the efficacy of the definition augmentation technique, offering a promising direction for improving the biomedical NLP capabilities of LLMs without the need for extensive retraining or fine-tuning. This work highlights the potential of contextual in-context learning strategies to bridge the gap between the general-purpose knowledge of LLMs and the specialized requirements of domain-specific tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
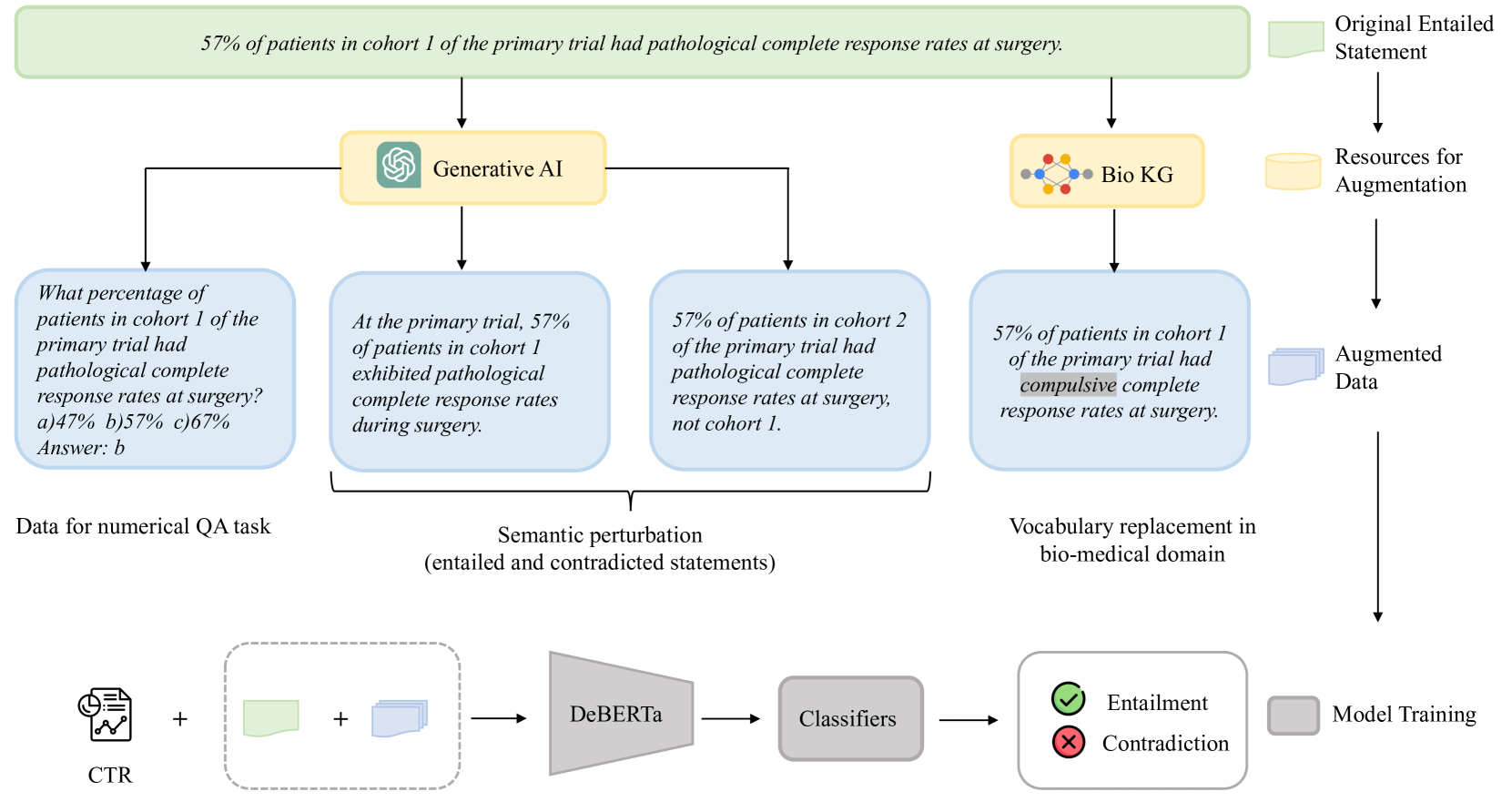
DKE-Research at SemEval-2024 Task 2: Incorporating Data Augmentation with Generative Models and Biomedical Knowledge to Enhance Inference Robustness
Yuqi Wang, Zeqiang Wang, Wei Wang, Qi Chen, Kaizhu Huang, Anh Nguyen, Suparna De
0
0
Safe and reliable natural language inference is critical for extracting insights from clinical trial reports but poses challenges due to biases in large pre-trained language models. This paper presents a novel data augmentation technique to improve model robustness for biomedical natural language inference in clinical trials. By generating synthetic examples through semantic perturbations and domain-specific vocabulary replacement and adding a new task for numerical and quantitative reasoning, we introduce greater diversity and reduce shortcut learning. Our approach, combined with multi-task learning and the DeBERTa architecture, achieved significant performance gains on the NLI4CT 2024 benchmark compared to the original language models. Ablation studies validate the contribution of each augmentation method in improving robustness. Our best-performing model ranked 12th in terms of faithfulness and 8th in terms of consistency, respectively, out of the 32 participants.
4/16/2024
👁️
LLMs in Biomedicine: A study on clinical Named Entity Recognition
Masoud Monajatipoor, Jiaxin Yang, Joel Stremmel, Melika Emami, Fazlolah Mohaghegh, Mozhdeh Rouhsedaghat, Kai-Wei Chang
0
0
Large Language Models (LLMs) demonstrate remarkable versatility in various NLP tasks but encounter distinct challenges in biomedicine due to medical language complexities and data scarcity. This paper investigates the application of LLMs in the medical domain by exploring strategies to enhance their performance for the Named-Entity Recognition (NER) task. Specifically, our study reveals the importance of meticulously designed prompts in biomedicine. Strategic selection of in-context examples yields a notable improvement, showcasing ~15-20% increase in F1 score across all benchmark datasets for few-shot clinical NER. Additionally, our findings suggest that integrating external resources through prompting strategies can bridge the gap between general-purpose LLM proficiency and the specialized demands of medical NER. Leveraging a medical knowledge base, our proposed method inspired by Retrieval-Augmented Generation (RAG) can boost the F1 score of LLMs for zero-shot clinical NER. We will release the code upon publication.
4/12/2024
💬
Leveraging Large Language Models for Knowledge-free Weak Supervision in Clinical Natural Language Processing
Enshuo Hsu, Kirk Roberts
0
0
The performance of deep learning-based natural language processing systems is based on large amounts of labeled training data which, in the clinical domain, are not easily available or affordable. Weak supervision and in-context learning offer partial solutions to this issue, particularly using large language models (LLMs), but their performance still trails traditional supervised methods with moderate amounts of gold-standard data. In particular, inferencing with LLMs is computationally heavy. We propose an approach leveraging fine-tuning LLMs and weak supervision with virtually no domain knowledge that still achieves consistently dominant performance. Using a prompt-based approach, the LLM is used to generate weakly-labeled data for training a downstream BERT model. The weakly supervised model is then further fine-tuned on small amounts of gold standard data. We evaluate this approach using Llama2 on three different n2c2 datasets. With no more than 10 gold standard notes, our final BERT models weakly supervised by fine-tuned Llama2-13B consistently outperformed out-of-the-box PubMedBERT by 4.7% to 47.9% in F1 scores. With only 50 gold standard notes, our models achieved close performance to fully fine-tuned systems.
6/12/2024

Generalizable and Scalable Multistage Biomedical Concept Normalization Leveraging Large Language Models
Nicholas J Dobbins
0
0
Background: Biomedical entity normalization is critical to biomedical research because the richness of free-text clinical data, such as progress notes, can often be fully leveraged only after translating words and phrases into structured and coded representations suitable for analysis. Large Language Models (LLMs), in turn, have shown great potential and high performance in a variety of natural language processing (NLP) tasks, but their application for normalization remains understudied. Methods: We applied both proprietary and open-source LLMs in combination with several rule-based normalization systems commonly used in biomedical research. We used a two-step LLM integration approach, (1) using an LLM to generate alternative phrasings of a source utterance, and (2) to prune candidate UMLS concepts, using a variety of prompting methods. We measure results by $F_{beta}$, where we favor recall over precision, and F1. Results: We evaluated a total of 5,523 concept terms and text contexts from a publicly available dataset of human-annotated biomedical abstracts. Incorporating GPT-3.5-turbo increased overall $F_{beta}$ and F1 in normalization systems +9.5 and +7.3 (MetaMapLite), +13.9 and +10.9 (QuickUMLS), and +10.5 and +10.3 (BM25), while the open-source Vicuna model achieved +10.8 and +12.2 (MetaMapLite), +14.7 and +15 (QuickUMLS), and +15.6 and +18.7 (BM25). Conclusions: Existing general-purpose LLMs, both propriety and open-source, can be leveraged at scale to greatly improve normalization performance using existing tools, with no fine-tuning.
5/27/2024