SEME at SemEval-2024 Task 2: Comparing Masked and Generative Language Models on Natural Language Inference for Clinical Trials
2404.03977
0
0
Abstract
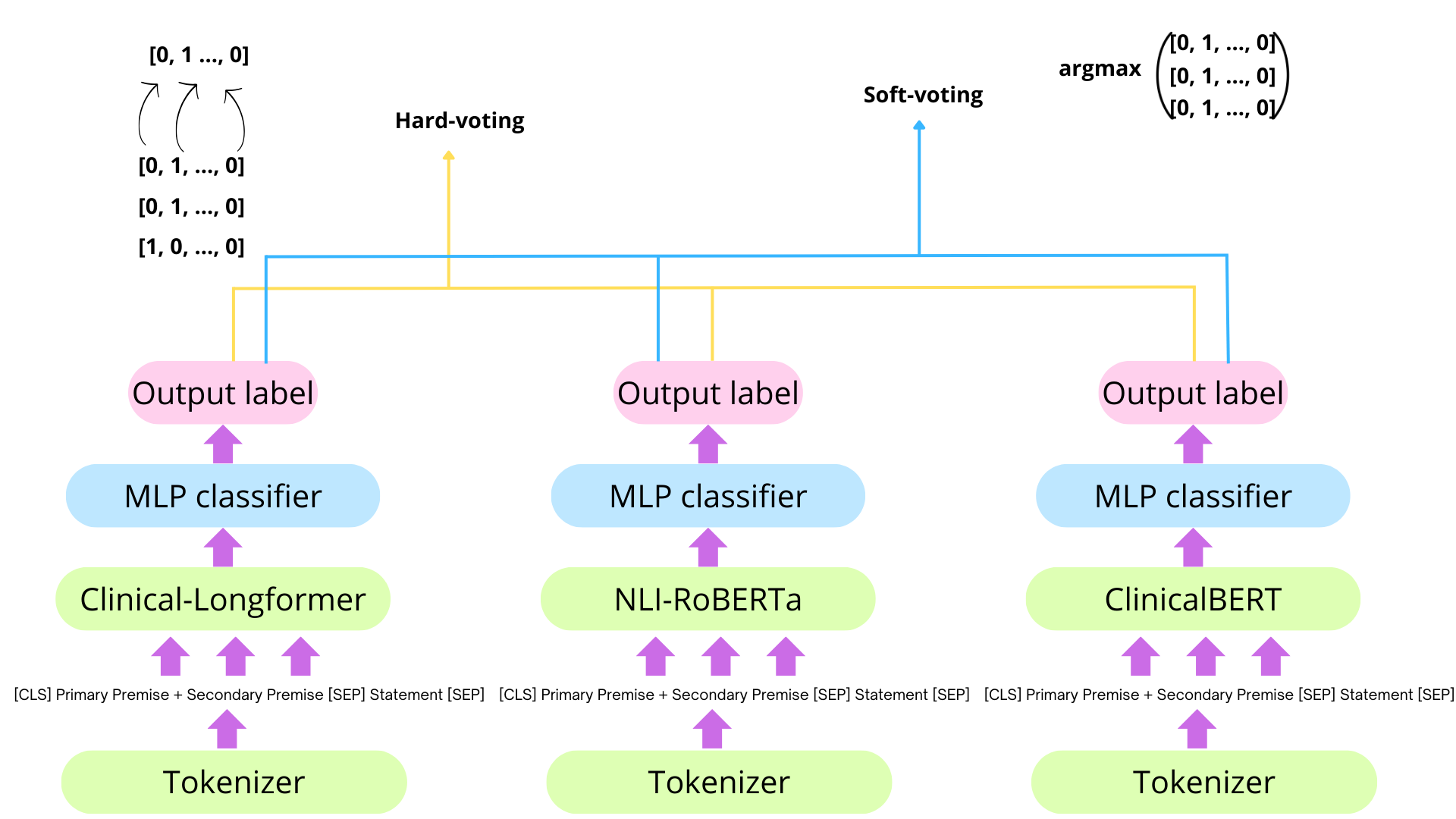
This paper describes our submission to Task 2 of SemEval-2024: Safe Biomedical Natural Language Inference for Clinical Trials. The Multi-evidence Natural Language Inference for Clinical Trial Data (NLI4CT) consists of a Textual Entailment (TE) task focused on the evaluation of the consistency and faithfulness of Natural Language Inference (NLI) models applied to Clinical Trial Reports (CTR). We test 2 distinct approaches, one based on finetuning and ensembling Masked Language Models and the other based on prompting Large Language Models using templates, in particular, using Chain-Of-Thought and Contrastive Chain-Of-Thought. Prompting Flan-T5-large in a 2-shot setting leads to our best system that achieves 0.57 F1 score, 0.64 Faithfulness, and 0.56 Consistency.
Create account to get full access
Overview
- This paper compares the performance of masked language models and generative language models on a natural language inference task for clinical trials data.
- The researchers evaluate how well these models can determine if a given hypothesis statement is true, false, or uncertain based on the context of a clinical trial description.
- This task is important for applications like clinical trial information extraction and biomedical literature understanding.
Plain English Explanation
The paper looks at how well different types of AI language models can understand the relationship between statements about clinical trials and the actual details of those trials. Language models are AI systems that can read and process human language. There are two main types - masked models that fill in missing words, and generative models that can create new text.
The researchers wanted to see how good these models are at determining if a given claim about a clinical trial is true, false, or uncertain based on the information provided about the trial. This is an important task for applications that need to automatically extract key facts and insights from large amounts of clinical data and literature.
For example, if a clinical trial description mentions that a new drug was tested on patients with a certain disease, an AI system should be able to determine that the claim "this drug was tested on patients with that disease" is true. Being able to do this accurately and reliably could help healthcare professionals and researchers more effectively synthesize and apply insights from clinical research.
Technical Explanation
The researchers conducted experiments on a dataset of clinical trial descriptions and associated hypothesis statements. They compared the performance of several state-of-the-art masked language models like BERT and RoBERTa, as well as generative models like GPT-3, on classifying each hypothesis as true, false, or uncertain given the trial context.
The models were fine-tuned on the task-specific dataset and evaluated using standard natural language inference metrics like accuracy, F1-score, and Matthews correlation coefficient. The results showed that the masked language models generally outperformed the generative models, achieving higher scores across the different evaluation metrics.
Further analysis revealed that the masked models were better able to capture nuanced logical relationships between the hypotheses and trial details, while the generative models tended to struggle more with this type of reasoning. The researchers also found that model performance varied depending on the complexity and specificity of the hypothesis statements.
Critical Analysis
The paper provides a thorough and well-designed evaluation of how leading language models perform on a clinically-relevant natural language inference task. The researchers acknowledge several limitations, such as the potential for biases in the dataset and the need for further testing on a wider range of clinical domains.
Additionally, while the masked models outperformed the generative ones in this study, it's unclear if this finding would generalize to other types of clinical language understanding tasks. The researchers also note that their analysis did not delve into the specific reasoning capabilities of the different model architectures, an area that could warrant further investigation.
An interesting avenue for future work could be to evaluate the models using contrast sets - carefully constructed test examples designed to probe the models' understanding more deeply. This could shed light on the types of inferences the models are capable of making and the limitations of their clinical language comprehension.
Conclusion
This paper presents a valuable contribution to the ongoing research on applying state-of-the-art language models to clinical domain tasks. The findings suggest that masked language models like BERT and RoBERTa may be better suited than generative models like GPT-3 for natural language inference on clinical trial data.
The results have implications for the development of healthcare-specific language models and the broader goal of leveraging large-scale language AI to improve the efficiency and accuracy of clinical research and decision-making. As the field continues to evolve, studies like this one will help guide the design and application of these powerful AI systems in the medical domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SemEval-2024 Task 2: Safe Biomedical Natural Language Inference for Clinical Trials
Mael Jullien, Marco Valentino, Andr'e Freitas
0
0
Large Language Models (LLMs) are at the forefront of NLP achievements but fall short in dealing with shortcut learning, factual inconsistency, and vulnerability to adversarial inputs.These shortcomings are especially critical in medical contexts, where they can misrepresent actual model capabilities. Addressing this, we present SemEval-2024 Task 2: Safe Biomedical Natural Language Inference for ClinicalTrials. Our contributions include the refined NLI4CT-P dataset (i.e., Natural Language Inference for Clinical Trials - Perturbed), designed to challenge LLMs with interventional and causal reasoning tasks, along with a comprehensive evaluation of methods and results for participant submissions. A total of 106 participants registered for the task contributing to over 1200 individual submissions and 25 system overview papers. This initiative aims to advance the robustness and applicability of NLI models in healthcare, ensuring safer and more dependable AI assistance in clinical decision-making. We anticipate that the dataset, models, and outcomes of this task can support future research in the field of biomedical NLI. The dataset, competition leaderboard, and website are publicly available.
4/9/2024

IITK at SemEval-2024 Task 2: Exploring the Capabilities of LLMs for Safe Biomedical Natural Language Inference for Clinical Trials
Shreyasi Mandal, Ashutosh Modi
0
0
Large Language models (LLMs) have demonstrated state-of-the-art performance in various natural language processing (NLP) tasks across multiple domains, yet they are prone to shortcut learning and factual inconsistencies. This research investigates LLMs' robustness, consistency, and faithful reasoning when performing Natural Language Inference (NLI) on breast cancer Clinical Trial Reports (CTRs) in the context of SemEval 2024 Task 2: Safe Biomedical Natural Language Inference for Clinical Trials. We examine the reasoning capabilities of LLMs and their adeptness at logical problem-solving. A comparative analysis is conducted on pre-trained language models (PLMs), GPT-3.5, and Gemini Pro under zero-shot settings using Retrieval-Augmented Generation (RAG) framework, integrating various reasoning chains. The evaluation yields an F1 score of 0.69, consistency of 0.71, and a faithfulness score of 0.90 on the test dataset.
4/9/2024
DKE-Research at SemEval-2024 Task 2: Incorporating Data Augmentation with Generative Models and Biomedical Knowledge to Enhance Inference Robustness
Yuqi Wang, Zeqiang Wang, Wei Wang, Qi Chen, Kaizhu Huang, Anh Nguyen, Suparna De
0
0
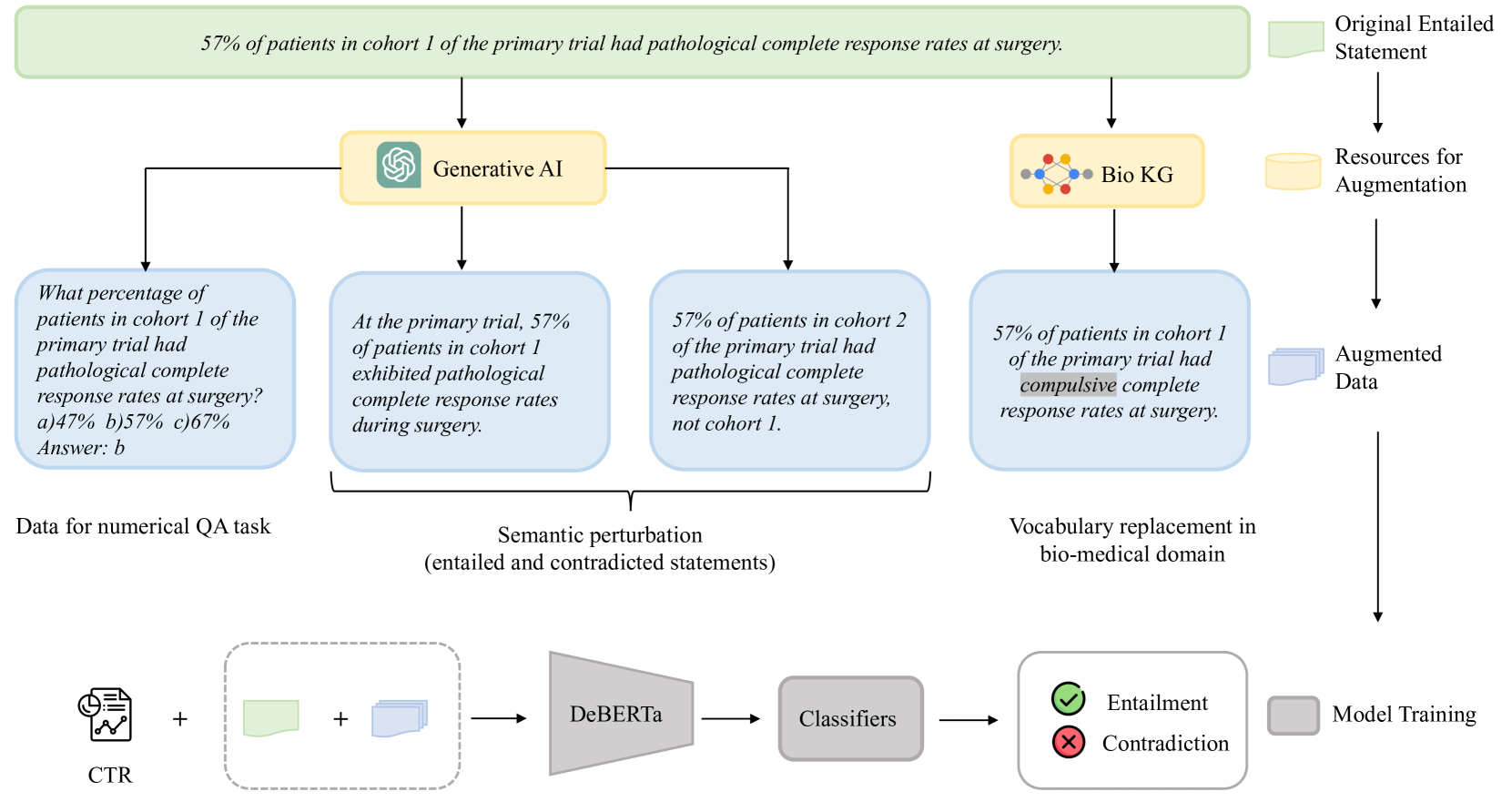
Safe and reliable natural language inference is critical for extracting insights from clinical trial reports but poses challenges due to biases in large pre-trained language models. This paper presents a novel data augmentation technique to improve model robustness for biomedical natural language inference in clinical trials. By generating synthetic examples through semantic perturbations and domain-specific vocabulary replacement and adding a new task for numerical and quantitative reasoning, we introduce greater diversity and reduce shortcut learning. Our approach, combined with multi-task learning and the DeBERTa architecture, achieved significant performance gains on the NLI4CT 2024 benchmark compared to the original language models. Ablation studies validate the contribution of each augmentation method in improving robustness. Our best-performing model ranked 12th in terms of faithfulness and 8th in terms of consistency, respectively, out of the 32 participants.
4/16/2024
🤯
D-NLP at SemEval-2024 Task 2: Evaluating Clinical Inference Capabilities of Large Language Models
Duygu Altinok
0
0
Large language models (LLMs) have garnered significant attention and widespread usage due to their impressive performance in various tasks. However, they are not without their own set of challenges, including issues such as hallucinations, factual inconsistencies, and limitations in numerical-quantitative reasoning. Evaluating LLMs in miscellaneous reasoning tasks remains an active area of research. Prior to the breakthrough of LLMs, Transformers had already proven successful in the medical domain, effectively employed for various natural language understanding (NLU) tasks. Following this trend, LLMs have also been trained and utilized in the medical domain, raising concerns regarding factual accuracy, adherence to safety protocols, and inherent limitations. In this paper, we focus on evaluating the natural language inference capabilities of popular open-source and closed-source LLMs using clinical trial reports as the dataset. We present the performance results of each LLM and further analyze their performance on a development set, particularly focusing on challenging instances that involve medical abbreviations and require numerical-quantitative reasoning. Gemini, our leading LLM, achieved a test set F1-score of 0.748, securing the ninth position on the task scoreboard. Our work is the first of its kind, offering a thorough examination of the inference capabilities of LLMs within the medical domain.
5/8/2024