DLCRec: A Novel Approach for Managing Diversity in LLM-Based Recommender Systems

0

Sign in to get full access
Overview
- Presents a novel approach called DLCRec for managing diversity in LLM-based recommender systems
- Aims to address the lack of diversity in recommendations generated by LLM-based models
- Proposes a framework that combines diverse latent clusters and cross-attention mechanisms to enhance diversity
Plain English Explanation
DLCRec is a new method for improving the diversity of recommendations generated by large language model (LLM)-based recommender systems. Recommender systems powered by LLMs can sometimes provide very similar or repetitive suggestions, which may not be ideal for users.
The key idea behind DLCRec is to create "diverse latent clusters" within the LLM. This means dividing the model's internal representations into distinct groups, each with its own unique characteristics. When generating recommendations, DLCRec then uses a "cross-attention" mechanism to blend together recommendations from these diverse clusters, resulting in a more varied set of suggestions.
By incorporating this diversity-enhancing approach, DLCRec aims to provide users with a broader range of relevant and interesting recommendations, rather than just the most "popular" or "obvious" options. This could be particularly useful in domains like entertainment recommendations or news curation, where users often benefit from discovering new, unexpected content.
Technical Explanation
The core of the DLCRec framework is the creation of diverse latent clusters within the LLM. The researchers first train the LLM on a large corpus of recommendation-related data. They then apply a clustering algorithm to the model's internal representations, dividing them into K distinct clusters.
During the recommendation process, DLCRec uses a cross-attention mechanism to blend together the outputs from these diverse clusters. Specifically, for each user query, the model computes attention weights across the cluster representations, allowing it to dynamically combine diverse recommendations.
The researchers evaluate DLCRec on several benchmark recommendation datasets, comparing its performance to state-of-the-art LLM-based recommender systems. They find that DLCRec is able to significantly improve recommendation diversity, as measured by metrics like intra-list diversity, without sacrificing overall recommendation quality.
Critical Analysis
One potential limitation of the DLCRec approach is the reliance on clustering the LLM's internal representations. While this allows for the creation of diverse latent clusters, the clustering process could be sensitive to hyperparameter choices and the underlying data distribution. The researchers acknowledge this and suggest further research into more robust clustering techniques.
Additionally, the paper does not provide a deep analysis of the types of diversity captured by DLCRec. It would be interesting to understand whether the method is able to surface recommendations that are truly novel and unexpected for the user, or if it simply generates a broader range of "safe" options.
Overall, the DLCRec framework represents a promising step towards enhancing diversity in LLM-based recommender systems. By incorporating this type of diversity-focused approach, recommender systems could provide users with a richer, more engaging experience.
Conclusion
The DLCRec paper presents a novel method for improving the diversity of recommendations generated by large language model-based recommender systems. By creating diverse latent clusters within the LLM and using a cross-attention mechanism, DLCRec is able to produce a wider range of relevant and interesting suggestions for users.
This diversity-enhancing approach could have significant implications for recommender systems in various domains, such as entertainment, news, and e-commerce, where users often benefit from discovering new, unexpected content. While the method has some limitations, the core ideas behind DLCRec represent an important step forward in the ongoing quest to build more engaging and personalized recommender systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DLCRec: A Novel Approach for Managing Diversity in LLM-Based Recommender Systems
Jiaju Chen, Chongming Gao, Shuai Yuan, Shuchang Liu, Qingpeng Cai, Peng Jiang
The integration of Large Language Models (LLMs) into recommender systems has led to substantial performance improvements. However, this often comes at the cost of diminished recommendation diversity, which can negatively impact user satisfaction. To address this issue, controllable recommendation has emerged as a promising approach, allowing users to specify their preferences and receive recommendations that meet their diverse needs. Despite its potential, existing controllable recommender systems frequently rely on simplistic mechanisms, such as a single prompt, to regulate diversity-an approach that falls short of capturing the full complexity of user preferences. In response to these limitations, we propose DLCRec, a novel framework designed to enable fine-grained control over diversity in LLM-based recommendations. Unlike traditional methods, DLCRec adopts a fine-grained task decomposition strategy, breaking down the recommendation process into three sequential sub-tasks: genre prediction, genre filling, and item prediction. These sub-tasks are trained independently and inferred sequentially according to user-defined control numbers, ensuring more precise control over diversity. Furthermore, the scarcity and uneven distribution of diversity-related user behavior data pose significant challenges for fine-tuning. To overcome these obstacles, we introduce two data augmentation techniques that enhance the model's robustness to noisy and out-of-distribution data. These techniques expose the model to a broader range of patterns, improving its adaptability in generating recommendations with varying levels of diversity. Our extensive empirical evaluation demonstrates that DLCRec not only provides precise control over diversity but also outperforms state-of-the-art baselines across multiple recommendation scenarios.
Read more8/23/2024

0
Enhancing Recommendation Diversity by Re-ranking with Large Language Models
Diego Carraro, Derek Bridge
It has long been recognized that it is not enough for a Recommender System (RS) to provide recommendations based only on their relevance to users. Among many other criteria, the set of recommendations may need to be diverse. Diversity is one way of handling recommendation uncertainty and ensuring that recommendations offer users a meaningful choice. The literature reports many ways of measuring diversity and improving the diversity of a set of recommendations, most notably by re-ranking and selecting from a larger set of candidate recommendations. Driven by promising insights from the literature on how to incorporate versatile Large Language Models (LLMs) into the RS pipeline, in this paper we show how LLMs can be used for diversity re-ranking. We begin with an informal study that verifies that LLMs can be used for re-ranking tasks and do have some understanding of the concept of item diversity. Then, we design a more rigorous methodology where LLMs are prompted to generate a diverse ranking from a candidate ranking using various prompt templates with different re-ranking instructions in a zero-shot fashion. We conduct comprehensive experiments testing state-of-the-art LLMs from the GPT and Llama families. We compare their re-ranking capabilities with random re-ranking and various traditional re-ranking methods from the literature. We open-source the code of our experiments for reproducibility. Our findings suggest that the trade-offs (in terms of performance and costs, among others) of LLM-based re-rankers are superior to those of random re-rankers but, as yet, inferior to the ones of traditional re-rankers. However, the LLM approach is promising. LLMs exhibit improved performance on many natural language processing and recommendation tasks and lower inference costs. Given these trends, we can expect LLM-based re-ranking to become more competitive soon.
Read more6/19/2024
💬
0
Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, Ji-Rong Wen
Recently, large language models (LLMs) have shown great potential in recommender systems, either improving existing recommendation models or serving as the backbone. However, there exists a large semantic gap between LLMs and recommender systems, since items to be recommended are often indexed by discrete identifiers (item ID) out of the LLM's vocabulary. In essence, LLMs capture language semantics while recommender systems imply collaborative semantics, making it difficult to sufficiently leverage the model capacity of LLMs for recommendation. To address this challenge, in this paper, we propose a new LLM-based recommendation model called LC-Rec, which can better integrate language and collaborative semantics for recommender systems. Our approach can directly generate items from the entire item set for recommendation, without relying on candidate items. Specifically, we make two major contributions in our approach. For item indexing, we design a learning-based vector quantization method with uniform semantic mapping, which can assign meaningful and non-conflicting IDs (called item indices) for items. For alignment tuning, we propose a series of specially designed tuning tasks to enhance the integration of collaborative semantics in LLMs. Our fine-tuning tasks enforce LLMs to deeply integrate language and collaborative semantics (characterized by the learned item indices), so as to achieve an effective adaptation to recommender systems. Extensive experiments demonstrate the effectiveness of our method, showing that our approach can outperform a number of competitive baselines including traditional recommenders and existing LLM-based recommenders. Our code is available at https://github.com/RUCAIBox/LC-Rec/.
Read more4/22/2024
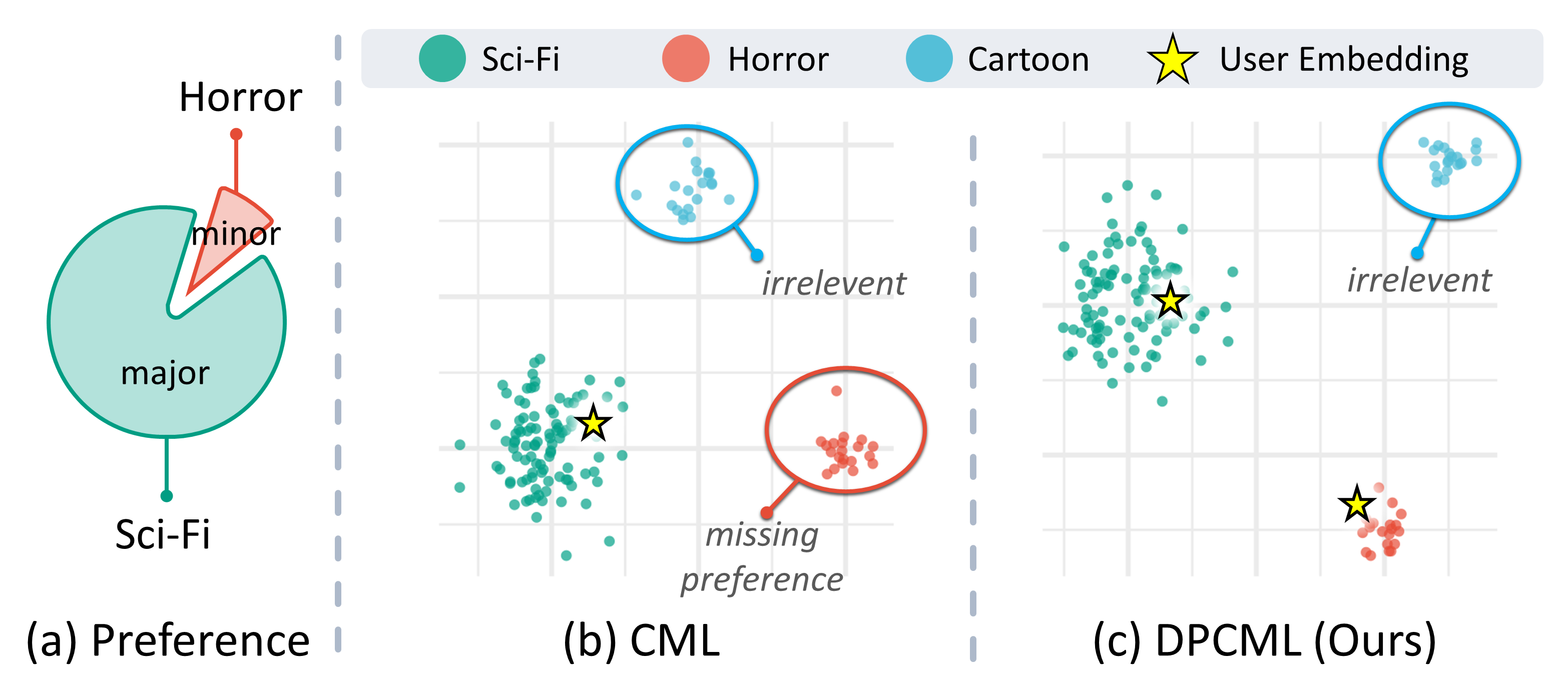
0
Improved Diversity-Promoting Collaborative Metric Learning for Recommendation
Shilong Bao, Qianqian Xu, Zhiyong Yang, Yuan He, Xiaochun Cao, Qingming Huang
Collaborative Metric Learning (CML) has recently emerged as a popular method in recommendation systems (RS), closing the gap between metric learning and collaborative filtering. Following the convention of RS, existing practices exploit unique user representation in their model design. This paper focuses on a challenging scenario where a user has multiple categories of interests. Under this setting, the unique user representation might induce preference bias, especially when the item category distribution is imbalanced. To address this issue, we propose a novel method called textit{Diversity-Promoting Collaborative Metric Learning} (DPCML), with the hope of considering the commonly ignored minority interest of the user. The key idea behind DPCML is to introduce a set of multiple representations for each user in the system where users' preference toward an item is aggregated by taking the minimum item-user distance among their embedding set. Specifically, we instantiate two effective assignment strategies to explore a proper quantity of vectors for each user. Meanwhile, a textit{Diversity Control Regularization Scheme} (DCRS) is developed to accommodate the multi-vector representation strategy better. Theoretically, we show that DPCML could induce a smaller generalization error than traditional CML. Furthermore, we notice that CML-based approaches usually require textit{negative sampling} to reduce the heavy computational burden caused by the pairwise objective therein. In this paper, we reveal the fundamental limitation of the widely adopted hard-aware sampling from the One-Way Partial AUC (OPAUC) perspective and then develop an effective sampling alternative for the CML-based paradigm. Finally, comprehensive experiments over a range of benchmark datasets speak to the efficacy of DPCML. Code are available at url{https://github.com/statusrank/LibCML}.
Read more9/4/2024