Enhancing Recommendation Diversity by Re-ranking with Large Language Models
2401.11506
0
0

Abstract
It has long been recognized that it is not enough for a Recommender System (RS) to provide recommendations based only on their relevance to users. Among many other criteria, the set of recommendations may need to be diverse. Diversity is one way of handling recommendation uncertainty and ensuring that recommendations offer users a meaningful choice. The literature reports many ways of measuring diversity and improving the diversity of a set of recommendations, most notably by re-ranking and selecting from a larger set of candidate recommendations. Driven by promising insights from the literature on how to incorporate versatile Large Language Models (LLMs) into the RS pipeline, in this paper we show how LLMs can be used for diversity re-ranking. We begin with an informal study that verifies that LLMs can be used for re-ranking tasks and do have some understanding of the concept of item diversity. Then, we design a more rigorous methodology where LLMs are prompted to generate a diverse ranking from a candidate ranking using various prompt templates with different re-ranking instructions in a zero-shot fashion. We conduct comprehensive experiments testing state-of-the-art LLMs from the GPT and Llama families. We compare their re-ranking capabilities with random re-ranking and various traditional re-ranking methods from the literature. We open-source the code of our experiments for reproducibility. Our findings suggest that the trade-offs (in terms of performance and costs, among others) of LLM-based re-rankers are superior to those of random re-rankers but, as yet, inferior to the ones of traditional re-rankers. However, the LLM approach is promising. LLMs exhibit improved performance on many natural language processing and recommendation tasks and lower inference costs. Given these trends, we can expect LLM-based re-ranking to become more competitive soon.
Create account to get full access
Overview
- This paper explores how large language models (LLMs) can be used to enhance the diversity of recommendations in recommender systems.
- The researchers propose a re-ranking approach that leverages the semantic understanding and generation capabilities of LLMs to diversify the recommended items.
- The method is evaluated on several benchmark datasets and shows improvements in recommendation diversity over traditional approaches.
Plain English Explanation
Recommender systems are algorithms that suggest products, content, or information to users based on their past preferences and behaviors. However, these systems often struggle to provide a diverse set of recommendations, tending to suggest items that are similar to what the user has already engaged with.
This paper explores a way to address this problem by using powerful language models, known as large language models (LLMs), to re-rank the recommended items. LLMs are AI systems that can understand and generate human-like text, and the researchers hypothesized that these models could provide a more nuanced understanding of the semantic relationships between the items, allowing them to identify and promote more diverse recommendations.
The key idea is to use an LLM to evaluate the recommended items and re-order them in a way that increases the overall diversity, while still ensuring that the recommendations are relevant to the user's interests. This is done by having the LLM assess the semantic similarity between the recommended items and then adjusting the ranking to include a greater variety of content.
By incorporating this LLM-based re-ranking approach, the researchers were able to demonstrate improvements in recommendation diversity across several different datasets and benchmarks. This suggests that leveraging the capabilities of large language models could be a promising way to make recommender systems better at surfacing a wider range of relevant and interesting content for users.
Technical Explanation
The paper proposes a re-ranking approach that uses large language models (LLMs) to enhance the diversity of recommendations in recommender systems. The researchers start by generating an initial set of recommendations using a traditional recommender system algorithm, such as collaborative filtering or content-based filtering.
They then use an LLM, specifically the GPT-2 model, to compute the semantic similarity between each pair of recommended items. This is done by passing the item descriptions through the LLM and extracting the hidden representations, which capture the semantic content of the items. The similarity between items is then calculated as the cosine similarity between their respective representations.
Based on these similarity scores, the researchers re-rank the recommended items to increase the overall diversity. The re-ranking is performed by iteratively selecting the least similar item to the current recommendation set, until the desired number of recommendations is obtained. This ensures that the final set of recommendations covers a wider range of content and reduces redundancy.
The proposed LLM-based re-ranking approach is evaluated on several benchmark datasets, including MovieLens, Amazon, and Netflix. The results show that it outperforms traditional re-ranking methods, such as MMR and DPP, in terms of various diversity metrics, while maintaining comparable levels of recommendation relevance.
Critical Analysis
The paper presents a compelling approach for enhancing recommendation diversity using large language models. The key strength of the method is its ability to leverage the semantic understanding of LLMs to identify and promote more diverse recommendations, going beyond simple measures of item similarity or popularity.
However, the paper does not address several important considerations. For example, the researchers only evaluate the method on static datasets, and it's not clear how well the approach would scale or adapt to real-world, dynamic recommender systems with continuously evolving user preferences and item catalogs.
Additionally, the paper does not explore the computational and memory requirements of the LLM-based re-ranking, which could be a significant drawback for deployment in production systems. Efficient and responsible adaptation of LLMs for specific tasks and environments is an active area of research that could be relevant here.
Finally, the paper does not discuss potential biases or fairness implications of the proposed method. As recommender systems enter the era of large language models (LLMs), it will be crucial to carefully consider the ethical and societal impact of these techniques.
Conclusion
This paper presents a novel approach for enhancing the diversity of recommendations in recommender systems by leveraging the capabilities of large language models. The core idea of using LLMs to assess the semantic relationships between recommended items and re-rank them accordingly is a promising direction for improving the breadth and novelty of recommendations.
While the paper demonstrates the effectiveness of this approach on several benchmark datasets, further research is needed to address practical deployment considerations, such as computational efficiency and fairness. As the use of LLMs in recommender systems becomes more prevalent, it will be important to closely examine the societal implications and ensure that these powerful AI systems are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LLM-enhanced Reranking in Recommender Systems
Jingtong Gao, Bo Chen, Xiangyu Zhao, Weiwen Liu, Xiangyang Li, Yichao Wang, Zijian Zhang, Wanyu Wang, Yuyang Ye, Shanru Lin, Huifeng Guo, Ruiming Tang
0
0
Reranking is a critical component in recommender systems, playing an essential role in refining the output of recommendation algorithms. Traditional reranking models have focused predominantly on accuracy, but modern applications demand consideration of additional criteria such as diversity and fairness. Existing reranking approaches often fail to harmonize these diverse criteria effectively at the model level. Moreover, these models frequently encounter challenges with scalability and personalization due to their complexity and the varying significance of different reranking criteria in diverse scenarios. In response, we introduce a comprehensive reranking framework enhanced by LLM, designed to seamlessly integrate various reranking criteria while maintaining scalability and facilitating personalized recommendations. This framework employs a fully connected graph structure, allowing the LLM to simultaneously consider multiple aspects such as accuracy, diversity, and fairness through a coherent Chain-of-Thought (CoT) process. A customizable input mechanism is also integrated, enabling the tuning of the language model's focus to meet specific reranking needs. We validate our approach using three popular public datasets, where our framework demonstrates superior performance over existing state-of-the-art reranking models in balancing multiple criteria. The code for this implementation is publicly available.
6/21/2024
💬
A Survey on Large Language Models for Recommendation
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, Enhong Chen
0
0
Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, https://github.com/WLiK/LLM4Rec.
6/19/2024
💬
Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, Ji-Rong Wen
0
0
Recently, large language models (LLMs) have shown great potential in recommender systems, either improving existing recommendation models or serving as the backbone. However, there exists a large semantic gap between LLMs and recommender systems, since items to be recommended are often indexed by discrete identifiers (item ID) out of the LLM's vocabulary. In essence, LLMs capture language semantics while recommender systems imply collaborative semantics, making it difficult to sufficiently leverage the model capacity of LLMs for recommendation. To address this challenge, in this paper, we propose a new LLM-based recommendation model called LC-Rec, which can better integrate language and collaborative semantics for recommender systems. Our approach can directly generate items from the entire item set for recommendation, without relying on candidate items. Specifically, we make two major contributions in our approach. For item indexing, we design a learning-based vector quantization method with uniform semantic mapping, which can assign meaningful and non-conflicting IDs (called item indices) for items. For alignment tuning, we propose a series of specially designed tuning tasks to enhance the integration of collaborative semantics in LLMs. Our fine-tuning tasks enforce LLMs to deeply integrate language and collaborative semantics (characterized by the learned item indices), so as to achieve an effective adaptation to recommender systems. Extensive experiments demonstrate the effectiveness of our method, showing that our approach can outperform a number of competitive baselines including traditional recommenders and existing LLM-based recommenders. Our code is available at https://github.com/RUCAIBox/LC-Rec/.
4/22/2024
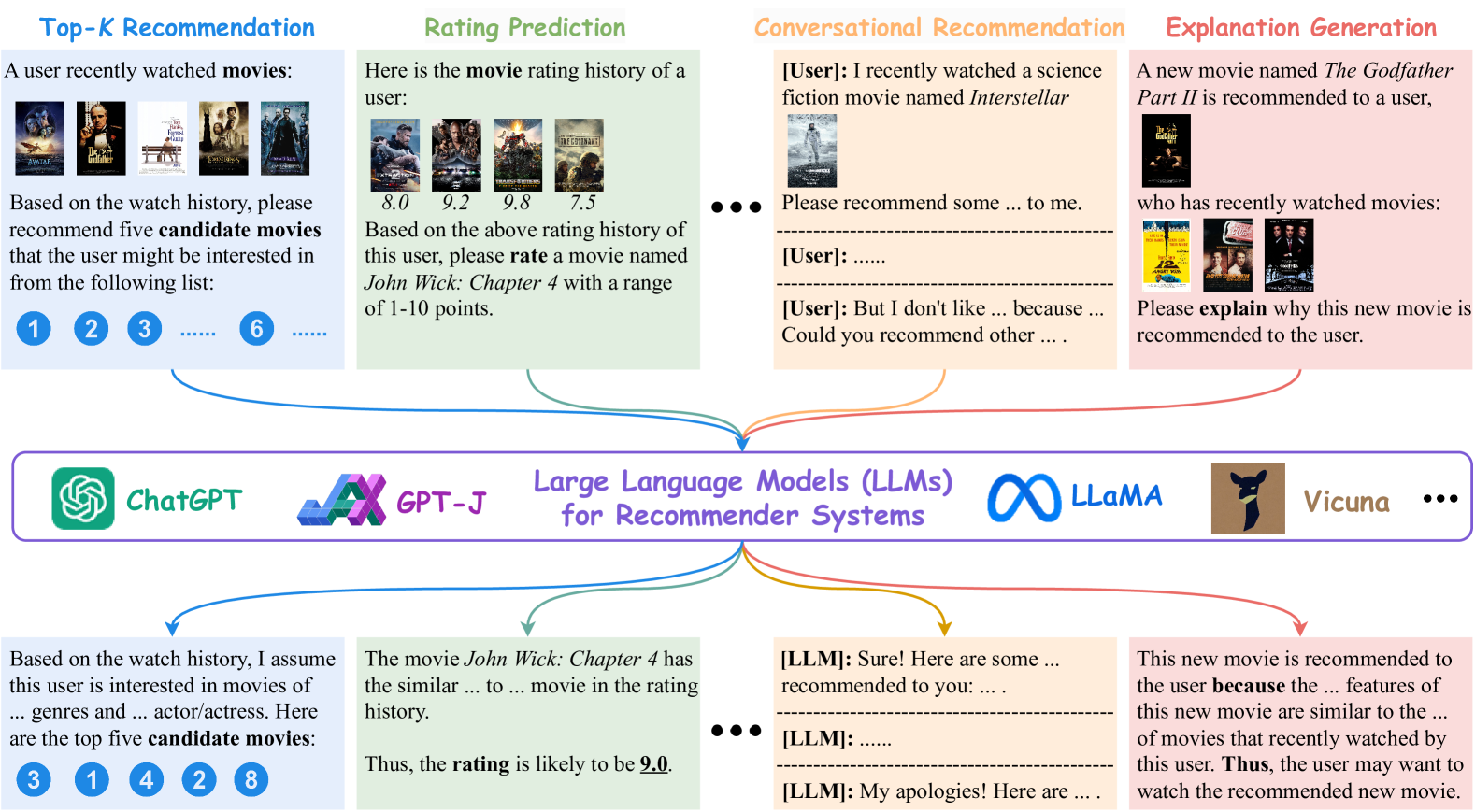
Recommender Systems in the Era of Large Language Models (LLMs)
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, Qing Li
0
0
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
4/23/2024