DLLens: Testing Deep Learning Libraries via LLM-aided Synthesis

0
🧪
Sign in to get full access
Overview
- This paper introduces a technique called "\thetable Tensor Property Model" for extracting path constraints from the control flow graphs of Deep Learning (DL) library APIs and their synthesized counterparts.
- Path constraints specify the input conditions for the execution of different paths in the control flow graph, which can be used to improve testing and analysis of DL libraries.
- The paper is related to several other works in the field of DL library testing and analysis, including survey-deep-learning-library-testing-methods, api-blend-comprehensive-corpora-training-benchmarking-api, dila-enhancing-llm-tool-learning-differential-logic, synthesizrr-generating-diverse-datasets-retrieval-augmentation, and llm-powered-test-case-generation-detecting-tricky.
Plain English Explanation
The paper introduces a technique to better understand how Deep Learning (DL) libraries work under the hood. DL libraries are software packages that provide a set of functions and tools for building and training machine learning models. When developers use these libraries, they often don't know exactly how the underlying code is executed.
The researchers developed a method to extract "path constraints" from the control flow graphs of DL library APIs and their synthesized counterparts. A control flow graph is a representation of all the possible paths that the execution of a program can take. A path constraint is the set of conditions that must be met for a particular execution path to be taken.
By extracting these path constraints, the researchers can gain a deeper understanding of how the DL library code behaves for different inputs. This information can be used to improve testing and analysis of DL libraries, making them more reliable and robust.
The technique is related to other work in the field of DL library testing and analysis, which aims to develop better tools and methods for ensuring the quality and safety of these important software components.
Technical Explanation
The paper introduces a technique called the "\thetable Tensor Property Model" for extracting path constraints from the control flow graphs of DL library APIs and their synthesized counterparts.
For a given DL library API and its counterpart synthesized in api-blend-comprehensive-corpora-training-benchmarking-api, the researchers use the "\toolname" tool to extract path constraints from the control flow graphs of their implementations. Specifically, "\toolname" extracts a path constraint for each execution path in the control flow graph, where each path constraint specifies the input conditions for the execution of the concerned path, as described in survey-deep-learning-library-testing-methods.
The extracted path constraints can be used to improve testing and analysis of DL libraries, as they provide a detailed understanding of how the library code behaves for different inputs. This information can be leveraged by tools like dila-enhancing-llm-tool-learning-differential-logic, synthesizrr-generating-diverse-datasets-retrieval-augmentation, and llm-powered-test-case-generation-detecting-tricky to improve the testing and analysis of DL libraries.
Critical Analysis
The paper provides a novel technique for extracting path constraints from DL library implementations, which can be a valuable tool for improving the testing and analysis of these important software components. However, the paper does not provide a comprehensive evaluation of the effectiveness of the proposed technique, nor does it address potential limitations or areas for further research.
One potential limitation of the approach is that it relies on the availability of synthesized counterparts for the DL library APIs, which may not always be the case in practice. Additionally, the extraction of path constraints from control flow graphs may be challenging for complex or obfuscated DL library implementations, which could limit the applicability of the technique.
Further research could explore the integration of the path constraint extraction technique with other DL library testing and analysis methods, such as those mentioned in the related works, to develop a more comprehensive framework for ensuring the quality and reliability of DL libraries. Additionally, empirical studies evaluating the practical impact of the proposed technique on DL library testing and analysis would be valuable.
Conclusion
The "\thetable Tensor Property Model" introduced in this paper provides a novel technique for extracting path constraints from the control flow graphs of DL library APIs and their synthesized counterparts. This information can be used to improve the testing and analysis of DL libraries, which are critical components in many modern machine learning and AI systems.
While the paper presents a promising approach, further research is needed to address potential limitations and explore the integration of the path constraint extraction technique with other DL library testing and analysis methods. Nonetheless, this work represents an important step forward in the field of DL library quality assurance and reliability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
0
DLLens: Testing Deep Learning Libraries via LLM-aided Synthesis
Meiziniu Li, Dongze Li, Jianmeng Liu, Jialun Cao, Yongqiang Tian, Shing-Chi Cheung
Testing is a major approach to ensuring the quality of deep learning (DL) libraries. Existing testing techniques commonly adopt differential testing to relieve the need for test oracle construction. However, these techniques are limited in finding implementations that offer the same functionality and generating diverse test inputs for differential testing. This paper introduces DLLens, a novel differential testing technique for DL library testing. Our insight is that APIs in different DL libraries are commonly designed to accomplish various computations for the same set of published DL algorithms. Although the mapping of these APIs is not often one-to-one, we observe that their computations can be mutually simulated after proper composition and adaptation. The use of these simulation counterparts facilitates differential testing for the detection of functional DL library bugs. Leveraging the insight, we propose DLLens as a novel mechanism that utilizes a large language model (LLM) to synthesize valid counterparts of DL library APIs. To generate diverse test inputs, DLLens incorporates a static analysis method aided by LLM to extract path constraints from all execution paths in each API and its counterpart's implementations. These path constraints are then used to guide the generation of diverse test inputs. We evaluate DLLens on two popular DL libraries, TensorFlow and PyTorch. Our evaluation shows that DLLens can synthesize counterparts for more than twice as many APIs found by state-of-the-art techniques on these libraries. Moreover, DLLens can extract 26.7% more constraints and detect 2.5 times as many bugs as state-of-the-art techniques. DLLens has successfully found 56 bugs in recent TensorFlow and PyTorch libraries. Among them, 41 are previously unknown, 39 of which have been confirmed by developers after reporting, and 19 of those confirmed bugs have been fixed by developers.
Read more6/13/2024
0
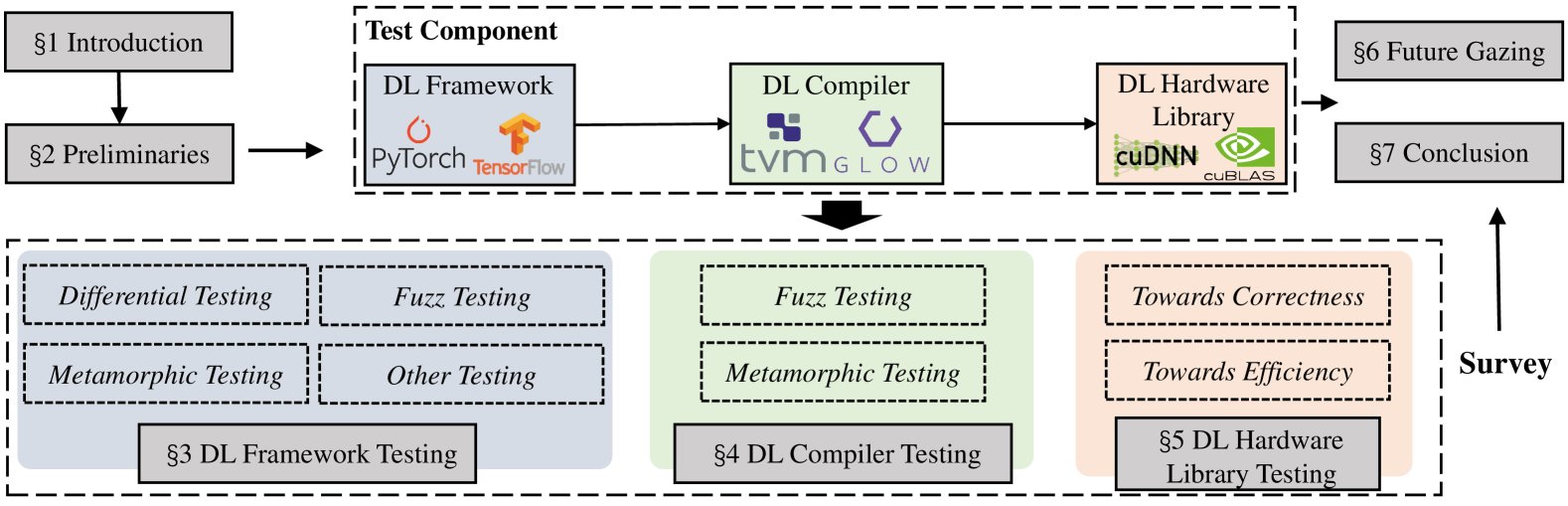
A Survey of Deep Learning Library Testing Methods
Xiaoyu Zhang, Weipeng Jiang, Chao Shen, Qi Li, Qian Wang, Chenhao Lin, Xiaohong Guan
In recent years, software systems powered by deep learning (DL) techniques have significantly facilitated people's lives in many aspects. As the backbone of these DL systems, various DL libraries undertake the underlying optimization and computation. However, like traditional software, DL libraries are not immune to bugs, which can pose serious threats to users' personal property and safety. Studying the characteristics of DL libraries, their associated bugs, and the corresponding testing methods is crucial for enhancing the security of DL systems and advancing the widespread application of DL technology. This paper provides an overview of the testing research related to various DL libraries, discusses the strengths and weaknesses of existing methods, and provides guidance and reference for the application of the DL library. This paper first introduces the workflow of DL underlying libraries and the characteristics of three kinds of DL libraries involved, namely DL framework, DL compiler, and DL hardware library. It then provides definitions for DL underlying library bugs and testing. Additionally, this paper summarizes the existing testing methods and tools tailored to these DL libraries separately and analyzes their effectiveness and limitations. It also discusses the existing challenges of DL library testing and outlines potential directions for future research.
Read more4/30/2024

0
SynDL: A Large-Scale Synthetic Test Collection
Hossein A. Rahmani, Xi Wang, Emine Yilmaz, Nick Craswell, Bhaskar Mitra, Paul Thomas
Large-scale test collections play a crucial role in Information Retrieval (IR) research. However, according to the Cranfield paradigm and the research into publicly available datasets, the existing information retrieval research studies are commonly developed on small-scale datasets that rely on human assessors for relevance judgments - a time-intensive and expensive process. Recent studies have shown the strong capability of Large Language Models (LLMs) in producing reliable relevance judgments with human accuracy but at a greatly reduced cost. In this paper, to address the missing large-scale ad-hoc document retrieval dataset, we extend the TREC Deep Learning Track (DL) test collection via additional language model synthetic labels to enable researchers to test and evaluate their search systems at a large scale. Specifically, such a test collection includes more than 1,900 test queries from the previous years of tracks. We compare system evaluation with past human labels from past years and find that our synthetically created large-scale test collection can lead to highly correlated system rankings.
Read more9/2/2024
🏋️
0
API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs
Kinjal Basu, Ibrahim Abdelaziz, Subhajit Chaudhury, Soham Dan, Maxwell Crouse, Asim Munawar, Sadhana Kumaravel, Vinod Muthusamy, Pavan Kapanipathi, Luis A. Lastras
There is a growing need for Large Language Models (LLMs) to effectively use tools and external Application Programming Interfaces (APIs) to plan and complete tasks. As such, there is tremendous interest in methods that can acquire sufficient quantities of train and test data that involve calls to tools / APIs. Two lines of research have emerged as the predominant strategies for addressing this challenge. The first has focused on synthetic data generation techniques, while the second has involved curating task-adjacent datasets which can be transformed into API / Tool-based tasks. In this paper, we focus on the task of identifying, curating, and transforming existing datasets and, in turn, introduce API-BLEND, a large corpora for training and systematic testing of tool-augmented LLMs. The datasets mimic real-world scenarios involving API-tasks such as API / tool detection, slot filling, and sequencing of the detected APIs. We demonstrate the utility of the API-BLEND dataset for both training and benchmarking purposes.
Read more5/21/2024