SynDL: A Large-Scale Synthetic Test Collection

0

Sign in to get full access
Overview
- Introduces SynDL, a large-scale synthetic test collection for document retrieval and language modeling tasks
- Outlines the key benefits of using synthetic data for model evaluation and development
- Discusses the methodology used to generate the SynDL dataset and its key characteristics
Plain English Explanation
The research paper introduces SynDL, a new dataset that was created entirely through artificial means, rather than being based on real-world data. The key idea behind SynDL is to provide a large-scale, diverse test collection that can be used to more thoroughly evaluate and develop document retrieval and language modeling systems.
The researchers argue that synthetic data offers several advantages over traditional, real-world datasets. For one, it allows for much greater control and customization of the test collection, enabling the inclusion of a wider range of content, queries, and relevance judgments. This can help uncover the strengths and weaknesses of AI systems in ways that might not be evident from evaluations on more limited real-world datasets.
Additionally, synthetic data can be generated at scale and customized to specific use cases, making it a valuable tool for iterative model development and testing. The researchers used large language models to synthesize the textual content, queries, and relevance labels that make up the SynDL dataset, resulting in a highly diverse and flexible test collection.
Technical Explanation
The SynDL dataset was created using a multi-stage process that leveraged large language models (LLMs) to generate the necessary components. First, the researchers used an LLM to produce a corpus of synthetic documents, covering a wide range of topics and styles. They then employed another LLM to generate query statements and relevance judgments, pairing each query with the most relevant documents from the corpus.
The resulting dataset contains over 1 million documents, 100,000 queries, and 1 million relevance assessments, making it one of the largest synthetic test collections for information retrieval and language understanding tasks. The researchers carefully designed the dataset to exhibit realistic characteristics, such as lexical diversity, topic distributions, and query-document relevance patterns, while also introducing controlled variations and challenges to stress-test AI systems.
Critical Analysis
The SynDL dataset represents a promising approach to the challenge of evaluating retrieval and language models in a more comprehensive and systematic way. By leveraging synthetic data, the researchers were able to create a test collection that is orders of magnitude larger and more diverse than typical real-world datasets, allowing for more rigorous and nuanced model evaluation.
However, it's important to acknowledge that synthetic data, by its nature, may not fully capture the complexities and idiosyncrasies of real-world language and information-seeking behavior. There is a risk that models optimized for performance on SynDL may not generalize as well to real-world applications. Additional research is needed to understand the extent to which synthetic and real-world data can be effectively combined to support model development and evaluation.
Furthermore, the use of LLMs to generate the SynDL dataset raises questions about potential biases and limitations inherent in these models. The researchers acknowledge that the synthetic data may reflect the biases and knowledge gaps present in the LLMs used for generation, and more work is needed to mitigate these issues.
Conclusion
The SynDL dataset represents a significant advancement in the field of synthetic data generation for AI model development and evaluation. By providing a large-scale, highly customizable test collection, the researchers have opened up new possibilities for more comprehensive and systematic assessment of document retrieval and language understanding systems.
While synthetic data presents both opportunities and challenges, the SynDL project demonstrates the potential for leveraging large language models to create powerful test environments that can complement and enhance traditional real-world datasets. As the field of AI continues to evolve, innovative approaches like SynDL will likely play an increasingly important role in driving progress and ensuring the robustness and reliability of these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SynDL: A Large-Scale Synthetic Test Collection
Hossein A. Rahmani, Xi Wang, Emine Yilmaz, Nick Craswell, Bhaskar Mitra, Paul Thomas
Large-scale test collections play a crucial role in Information Retrieval (IR) research. However, according to the Cranfield paradigm and the research into publicly available datasets, the existing information retrieval research studies are commonly developed on small-scale datasets that rely on human assessors for relevance judgments - a time-intensive and expensive process. Recent studies have shown the strong capability of Large Language Models (LLMs) in producing reliable relevance judgments with human accuracy but at a greatly reduced cost. In this paper, to address the missing large-scale ad-hoc document retrieval dataset, we extend the TREC Deep Learning Track (DL) test collection via additional language model synthetic labels to enable researchers to test and evaluate their search systems at a large scale. Specifically, such a test collection includes more than 1,900 test queries from the previous years of tracks. We compare system evaluation with past human labels from past years and find that our synthetically created large-scale test collection can lead to highly correlated system rankings.
Read more9/2/2024
🐍
0
Synthetic Test Collections for Retrieval Evaluation
Hossein A. Rahmani, Nick Craswell, Emine Yilmaz, Bhaskar Mitra, Daniel Campos
Test collections play a vital role in evaluation of information retrieval (IR) systems. Obtaining a diverse set of user queries for test collection construction can be challenging, and acquiring relevance judgments, which indicate the appropriateness of retrieved documents to a query, is often costly and resource-intensive. Generating synthetic datasets using Large Language Models (LLMs) has recently gained significant attention in various applications. In IR, while previous work exploited the capabilities of LLMs to generate synthetic queries or documents to augment training data and improve the performance of ranking models, using LLMs for constructing synthetic test collections is relatively unexplored. Previous studies demonstrate that LLMs have the potential to generate synthetic relevance judgments for use in the evaluation of IR systems. In this paper, we comprehensively investigate whether it is possible to use LLMs to construct fully synthetic test collections by generating not only synthetic judgments but also synthetic queries. In particular, we analyse whether it is possible to construct reliable synthetic test collections and the potential risks of bias such test collections may exhibit towards LLM-based models. Our experiments indicate that using LLMs it is possible to construct synthetic test collections that can reliably be used for retrieval evaluation.
Read more5/14/2024
0
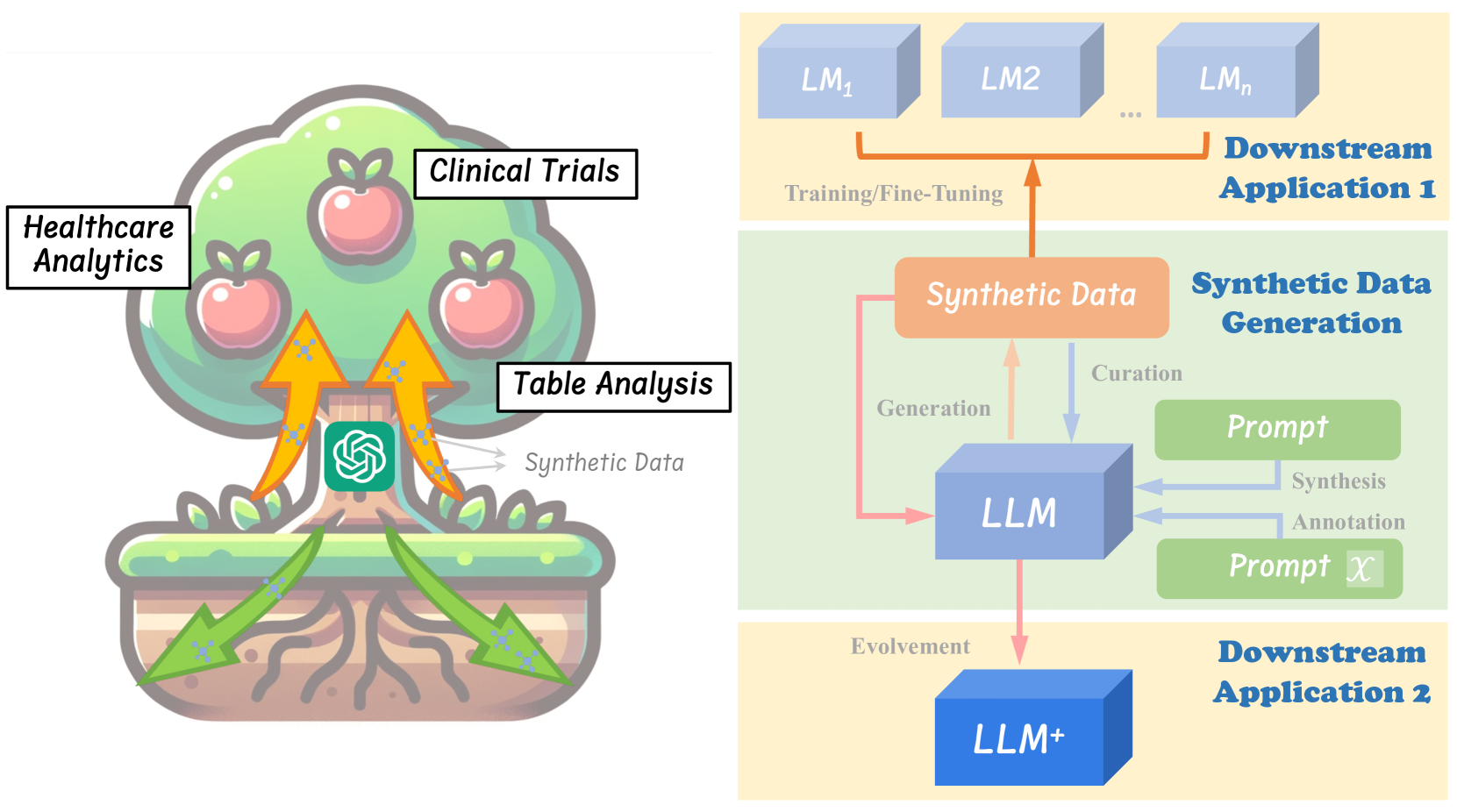
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, Haobo Wang
Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.
Read more6/24/2024
🏋️
0
Leveraging LLMs for Synthesizing Training Data Across Many Languages in Multilingual Dense Retrieval
Nandan Thakur, Jianmo Ni, Gustavo Hern'andez 'Abrego, John Wieting, Jimmy Lin, Daniel Cer
There has been limited success for dense retrieval models in multilingual retrieval, due to uneven and scarce training data available across multiple languages. Synthetic training data generation is promising (e.g., InPars or Promptagator), but has been investigated only for English. Therefore, to study model capabilities across both cross-lingual and monolingual retrieval tasks, we develop SWIM-IR, a synthetic retrieval training dataset containing 33 (high to very-low resource) languages for fine-tuning multilingual dense retrievers without requiring any human supervision. To construct SWIM-IR, we propose SAP (summarize-then-ask prompting), where the large language model (LLM) generates a textual summary prior to the query generation step. SAP assists the LLM in generating informative queries in the target language. Using SWIM-IR, we explore synthetic fine-tuning of multilingual dense retrieval models and evaluate them robustly on three retrieval benchmarks: XOR-Retrieve (cross-lingual), MIRACL (monolingual) and XTREME-UP (cross-lingual). Our models, called SWIM-X, are competitive with human-supervised dense retrieval models, e.g., mContriever-X, finding that SWIM-IR can cheaply substitute for expensive human-labeled retrieval training data. SWIM-IR dataset and SWIM-X models are available at https://github.com/google-research-datasets/SWIM-IR.
Read more4/17/2024