DNN-based ensemble singing voice synthesis with interactions between singers

0

Sign in to get full access
Overview
- Presents a deep neural network (DNN)-based approach for ensemble singing voice synthesis that captures interactions between singers
- Aims to generate more natural and expressive ensemble singing by modeling the complex relationships and dynamics between individual singers
- Includes an end-to-end model architecture and training strategy to enable efficient and data-effective ensemble singing voice synthesis
Plain English Explanation
This research paper describes a new method for generating ensemble singing voices using deep learning. Ensemble singing, where multiple voices sing together, is more complex than solo singing because the voices need to interact and blend in a natural way.
The researchers developed a deep neural network model that can capture these interactions between singers. This allows the model to produce more realistic and expressive ensemble singing, where the voices sound like they are truly performing together, rather than being simply combined.
The key innovation is the end-to-end model architecture and training approach, which enables efficient and data-effective synthesis of ensemble singing. This means the model can generate high-quality ensemble singing without requiring a large amount of training data.
Technical Explanation
The proposed approach uses a deep neural network to model the complex interactions between individual singers in an ensemble. The model takes individual singing voice features as input and generates the corresponding ensemble singing voice.
The architecture consists of several components:
- Encoder networks to extract features from each individual singer's voice
- An interaction module that models the relationships between the singers
- A decoder network that generates the final ensemble singing voice based on the encoded features and interaction modeling
The training process leverages both individual and ensemble singing data to efficiently learn the model parameters. This allows the model to generate ensemble singing even when only limited ensemble data is available.
The experiments demonstrate that the proposed approach can produce more natural and expressive ensemble singing compared to simpler methods that do not model the interactions between singers.
Critical Analysis
The paper presents a novel and promising approach for ensemble singing voice synthesis. The key strengths are the end-to-end model design that captures inter-singer interactions, and the efficient training strategy that enables data-effective learning.
However, the authors acknowledge some limitations. The model currently assumes a fixed number of singers in the ensemble, and may struggle with handling variable-sized ensembles. Additionally, the evaluation is limited to relatively simple ensemble singing examples, and further research is needed to assess the model's performance on more complex, real-world ensemble singing scenarios.
Future work could explore ways to make the model more flexible and scalable, such as by incorporating variable-size input handling or hierarchical modeling of ensemble dynamics. Conducting more thorough evaluations, including subjective human listening tests, would also help further validate the model's capabilities and identify areas for improvement.
Conclusion
This research presents a DNN-based approach for ensemble singing voice synthesis that models the interactions between individual singers. The end-to-end architecture and efficient training strategy enable the generation of more natural and expressive ensemble singing, even with limited training data.
While the current model has some limitations, the key ideas and innovations demonstrate the potential of this approach to advance the field of singing voice synthesis, particularly for ensemble singing which is an important yet understudied area. Further refinements and evaluations could lead to practical applications in music production, virtual performances, and other domains that require realistic and controllable ensemble singing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!DNN-based ensemble singing voice synthesis with interactions between singers
Hiroaki Hyodo, Shinnosuke Takamichi, Tomohiko Nakamura, Junya Koguchi, Hiroshi Saruwatari
We propose a singing voice synthesis (SVS) method for a more unified ensemble singing voice by modeling interactions between singers. Most existing SVS methods aim to synthesize a solo voice, and do not consider interactions between singers, i.e., adjusting one's own voice to the others' voices. Since the production of ensemble voices from solo singing voices ignores the interactions, it can degrade the unity of the vocal ensemble. Therefore, we propose a SVS that reproduces the interactions. It is based on an architecture that uses musical scores of multiple voice parts, and loss functions that simulate the interactions' effect to acoustic features. Experimental results show that our methods improve the unity of the vocal ensemble.
Read more9/17/2024
0
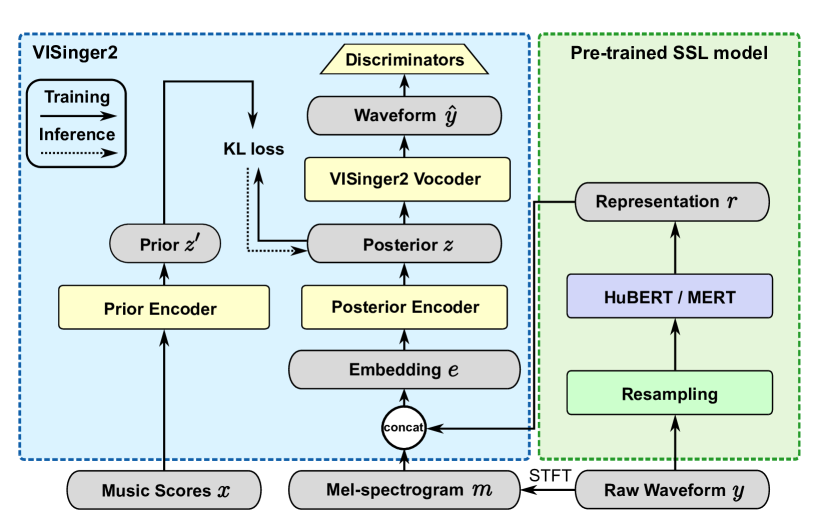
VISinger2+: End-to-End Singing Voice Synthesis Augmented by Self-Supervised Learning Representation
Yifeng Yu, Jiatong Shi, Yuning Wu, Shinji Watanabe
Singing Voice Synthesis (SVS) has witnessed significant advancements with the advent of deep learning techniques. However, a significant challenge in SVS is the scarcity of labeled singing voice data, which limits the effectiveness of supervised learning methods. In response to this challenge, this paper introduces a novel approach to enhance the quality of SVS by leveraging unlabeled data from pre-trained self-supervised learning models. Building upon the existing VISinger2 framework, this study integrates additional spectral feature information into the system to enhance its performance. The integration aims to harness the rich acoustic features from the pre-trained models, thereby enriching the synthesis and yielding a more natural and expressive singing voice. Experimental results in various corpora demonstrate the efficacy of this approach in improving the overall quality of synthesized singing voices in both objective and subjective metrics.
Read more6/14/2024

0
Speech Foundation Model Ensembles for the Controlled Singing Voice Deepfake Detection (CtrSVDD) Challenge 2024
Anmol Guragain, Tianchi Liu, Zihan Pan, Hardik B. Sailor, Qiongqiong Wang
This work details our approach to achieving a leading system with a 1.79% pooled equal error rate (EER) on the evaluation set of the Controlled Singing Voice Deepfake Detection (CtrSVDD). The rapid advancement of generative AI models presents significant challenges for detecting AI-generated deepfake singing voices, attracting increased research attention. The Singing Voice Deepfake Detection (SVDD) Challenge 2024 aims to address this complex task. In this work, we explore the ensemble methods, utilizing speech foundation models to develop robust singing voice anti-spoofing systems. We also introduce a novel Squeeze-and-Excitation Aggregation (SEA) method, which efficiently and effectively integrates representation features from the speech foundation models, surpassing the performance of our other individual systems. Evaluation results confirm the efficacy of our approach in detecting deepfake singing voices. The codes can be accessed at https://github.com/Anmol2059/SVDD2024.
Read more9/5/2024

0
A Preliminary Investigation on Flexible Singing Voice Synthesis Through Decomposed Framework with Inferrable Features
Lester Phillip Violeta, Taketo Akama
We investigate the feasibility of a singing voice synthesis (SVS) system by using a decomposed framework to improve flexibility in generating singing voices. Due to data-driven approaches, SVS performs a music score-to-waveform mapping; however, the direct mapping limits control, such as being able to only synthesize in the language or the singers present in the labeled singing datasets. As collecting large singing datasets labeled with music scores is an expensive task, we investigate an alternative approach by decomposing the SVS system and inferring different singing voice features. We decompose the SVS system into three-stage modules of linguistic, pitch contour, and synthesis, in which singing voice features such as linguistic content, F0, voiced/unvoiced, singer embeddings, and loudness are directly inferred from audio. Through this decomposed framework, we show that we can alleviate the labeled dataset requirements, adapt to different languages or singers, and inpaint the lyrical content of singing voices. Our investigations show that the framework has the potential to reach state-of-the-art in SVS, even though the model has additional functionality and improved flexibility. The comprehensive analysis of our investigated framework's current capabilities sheds light on the ways the research community can achieve a flexible and multifunctional SVS system.
Read more7/15/2024