VISinger2+: End-to-End Singing Voice Synthesis Augmented by Self-Supervised Learning Representation

0
Sign in to get full access
Overview
- This paper introduces VISinger2+, an end-to-end singing voice synthesis system that leverages self-supervised learning representations to improve performance.
- It builds upon the previous VISinger2 model, incorporating self-supervised representations from MakeSinger, Self-Supervised Singing Voice Pre-training, and Diverse Semantic-based Audio Pretrained Models.
- The authors also introduce a new singing voice dataset, Singing Voice Data Scaling Up, and a self-supervised pitch augmentation technique called SPA-SVC.
Plain English Explanation
The paper presents an improved singing voice synthesis system called VISinger2+. This system can generate realistic-sounding singing voices by taking in text and musical notes as input.
The key innovation is that VISinger2+ uses self-supervised learning to improve its performance. Self-supervised learning is a technique where the model learns useful representations from the data itself, without needing manual labeling.
The authors incorporate self-supervised representations from several previous models, including MakeSinger, Self-Supervised Singing Voice Pre-training, and Diverse Semantic-based Audio Pretrained Models. This allows the model to learn more powerful and generalizable features from the data.
Additionally, the authors introduce a new singing voice dataset called Singing Voice Data Scaling Up to train their model on. They also propose a self-supervised pitch augmentation technique called SPA-SVC to further improve the model's ability to synthesize expressive singing voices.
Technical Explanation
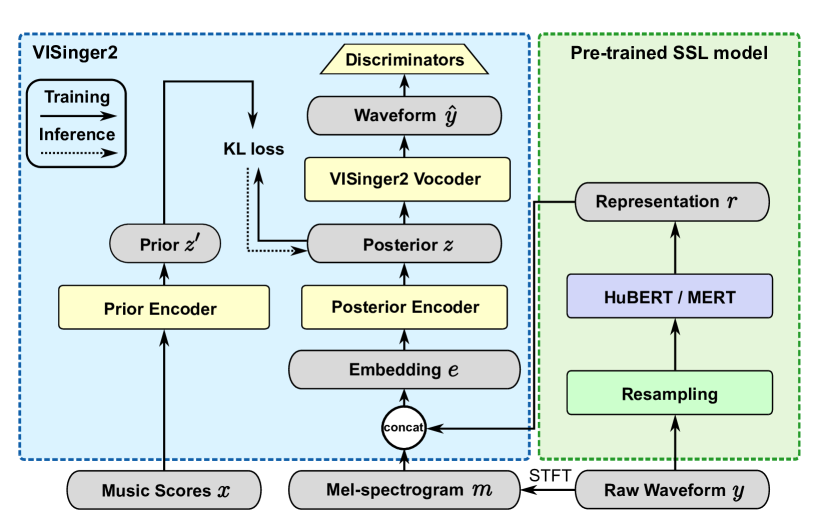
The core of VISinger2+ is an end-to-end neural network that takes text and musical notes as input and generates a corresponding singing voice audio waveform as output.
The authors leverage several state-of-the-art self-supervised learning representations to augment the core VISinger2 model. Specifically, they incorporate features from MakeSinger, which learns representations from limited singing data, Self-Supervised Singing Voice Pre-training, which learns general singing voice representations, and Diverse Semantic-based Audio Pretrained Models, which learns representations from a broad range of audio data.
In addition, the authors introduce a new singing voice dataset called Singing Voice Data Scaling Up to train their model on. This dataset contains a larger and more diverse set of singing samples compared to previous datasets.
Furthermore, the authors propose a self-supervised pitch augmentation technique called SPA-SVC to improve the model's ability to synthesize expressive singing voices. This technique learns to manipulate the pitch of the input audio in a self-supervised manner, allowing the model to generate more varied and natural-sounding singing.
Critical Analysis
The authors present a comprehensive approach to improving singing voice synthesis by leveraging self-supervised learning representations and introducing new datasets and techniques. This is a significant advancement over previous work, as it allows the model to learn more powerful and generalizable features from the data, leading to more realistic and expressive singing voice generation.
However, the authors do acknowledge several limitations of their work. For example, they note that the current model still struggles to capture certain nuances of human singing, such as vibrato and expressive phrasing. Additionally, the proposed SPA-SVC technique, while effective, may not fully capture the complex dynamics of human pitch control.
Further research could explore ways to address these limitations, such as incorporating more advanced self-supervised techniques or exploring alternative data augmentation methods. The authors could also investigate the model's ability to generalize to different singing styles and languages, as well as its performance on larger and more diverse datasets.
Overall, the VISinger2+ system represents an important step forward in the field of singing voice synthesis, and the authors' innovative use of self-supervised learning is a promising direction for future research in this area.
Conclusion
This paper presents VISinger2+, an end-to-end singing voice synthesis system that leverages self-supervised learning representations to improve performance. By incorporating features from state-of-the-art self-supervised models, introducing a new singing voice dataset, and proposing a self-supervised pitch augmentation technique, the authors have developed a more robust and expressive singing voice synthesis system.
The key contributions of this work include the integration of self-supervised learning representations, the introduction of the Singing Voice Data Scaling Up dataset, and the development of the SPA-SVC pitch augmentation technique. These advancements represent significant progress in the field of singing voice synthesis and could have important implications for applications such as music production, virtual assistants, and interactive entertainment.
While the authors acknowledge some limitations of the current system, the VISinger2+ model demonstrates the power of self-supervised learning for enhancing the synthesis of natural-sounding and expressive singing voices. This research paves the way for further advancements in this field and highlights the potential of self-supervised techniques to improve the quality and realism of synthetic speech and audio.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VISinger2+: End-to-End Singing Voice Synthesis Augmented by Self-Supervised Learning Representation
Yifeng Yu, Jiatong Shi, Yuning Wu, Shinji Watanabe
Singing Voice Synthesis (SVS) has witnessed significant advancements with the advent of deep learning techniques. However, a significant challenge in SVS is the scarcity of labeled singing voice data, which limits the effectiveness of supervised learning methods. In response to this challenge, this paper introduces a novel approach to enhance the quality of SVS by leveraging unlabeled data from pre-trained self-supervised learning models. Building upon the existing VISinger2 framework, this study integrates additional spectral feature information into the system to enhance its performance. The integration aims to harness the rich acoustic features from the pre-trained models, thereby enriching the synthesis and yielding a more natural and expressive singing voice. Experimental results in various corpora demonstrate the efficacy of this approach in improving the overall quality of synthesized singing voices in both objective and subjective metrics.
Read more6/14/2024

0
MakeSinger: A Semi-Supervised Training Method for Data-Efficient Singing Voice Synthesis via Classifier-free Diffusion Guidance
Semin Kim, Myeonghun Jeong, Hyeonseung Lee, Minchan Kim, Byoung Jin Choi, Nam Soo Kim
In this paper, we propose MakeSinger, a semi-supervised training method for singing voice synthesis (SVS) via classifier-free diffusion guidance. The challenge in SVS lies in the costly process of gathering aligned sets of text, pitch, and audio data. MakeSinger enables the training of the diffusion-based SVS model from any speech and singing voice data regardless of its labeling, thereby enhancing the quality of generated voices with large amount of unlabeled data. At inference, our novel dual guiding mechanism gives text and pitch guidance on the reverse diffusion step by estimating the score of masked input. Experimental results show that the model trained in a semi-supervised manner outperforms other baselines trained only on the labeled data in terms of pronunciation, pitch accuracy and overall quality. Furthermore, we demonstrate that by adding Text-to-Speech (TTS) data in training, the model can synthesize the singing voices of TTS speakers even without their singing voices.
Read more6/11/2024

0
Self-Supervised Singing Voice Pre-Training towards Speech-to-Singing Conversion
Ruiqi Li, Rongjie Huang, Yongqi Wang, Zhiqing Hong, Zhou Zhao
Speech-to-singing voice conversion (STS) task always suffers from data scarcity, because it requires paired speech and singing data. Compounding this issue are the challenges of content-pitch alignment and the suboptimal quality of generated outputs, presenting significant hurdles in STS research. This paper presents SVPT, an STS approach boosted by a self-supervised singing voice pre-training model. We leverage spoken language model techniques to tackle the rhythm alignment problem and the in-context learning capability to achieve zero-shot conversion. We adopt discrete-unit random resampling and pitch corruption strategies, enabling training with unpaired singing data and thus mitigating the issue of data scarcity. SVPT also serves as an effective backbone for singing voice synthesis (SVS), offering insights into scaling up SVS models. Experimental results indicate that SVPT delivers notable improvements in both STS and SVS endeavors. Audio samples are available at https://speech2sing.github.io.
Read more6/5/2024

0
A Preliminary Investigation on Flexible Singing Voice Synthesis Through Decomposed Framework with Inferrable Features
Lester Phillip Violeta, Taketo Akama
We investigate the feasibility of a singing voice synthesis (SVS) system by using a decomposed framework to improve flexibility in generating singing voices. Due to data-driven approaches, SVS performs a music score-to-waveform mapping; however, the direct mapping limits control, such as being able to only synthesize in the language or the singers present in the labeled singing datasets. As collecting large singing datasets labeled with music scores is an expensive task, we investigate an alternative approach by decomposing the SVS system and inferring different singing voice features. We decompose the SVS system into three-stage modules of linguistic, pitch contour, and synthesis, in which singing voice features such as linguistic content, F0, voiced/unvoiced, singer embeddings, and loudness are directly inferred from audio. Through this decomposed framework, we show that we can alleviate the labeled dataset requirements, adapt to different languages or singers, and inpaint the lyrical content of singing voices. Our investigations show that the framework has the potential to reach state-of-the-art in SVS, even though the model has additional functionality and improved flexibility. The comprehensive analysis of our investigated framework's current capabilities sheds light on the ways the research community can achieve a flexible and multifunctional SVS system.
Read more7/15/2024