MakeSinger: A Semi-Supervised Training Method for Data-Efficient Singing Voice Synthesis via Classifier-free Diffusion Guidance

0

Sign in to get full access
Overview
- This paper introduces MakeSinger, a new semi-supervised training method for data-efficient singing voice synthesis using classifier-free diffusion guidance.
- The method aims to generate high-quality singing voices with limited training data by leveraging unlabeled audio data and pre-trained audio models.
- MakeSinger incorporates techniques like self-supervised singing voice pre-training, latent diffusion modeling, and self-supervised pitch augmentation to improve data efficiency and synthesis quality.
Plain English Explanation
The paper presents a new technique called MakeSinger for generating realistic singing voices without needing a large dataset of professional recordings. This is an important problem because collecting high-quality singing data is time-consuming and expensive.
MakeSinger works by taking advantage of two key ideas. First, it uses "pre-trained" audio models that have already been trained on a massive amount of general audio data. These pre-trained models can provide useful information to help generate new singing voices, even with limited training data.
Second, MakeSinger uses a technique called "diffusion modeling" to generate the singing voices. Diffusion models work by starting with random noise and gradually transforming it into something more structured, like a singing voice. This approach can produce very high-quality audio outputs, even when the training data is limited.
By combining pre-trained audio models and diffusion modeling, MakeSinger is able to generate realistic singing voices using just a small dataset of singing recordings. This could be valuable for applications like virtual assistants, video game characters, and other scenarios where generating personalized singing voices is useful but collecting large datasets is challenging.
Technical Explanation
The core of MakeSinger is a semi-supervised training approach that leverages self-supervised singing voice pre-training, latent diffusion modeling, and self-supervised pitch augmentation to improve data efficiency and synthesis quality.
First, the method employs self-supervised pre-training on a large corpus of unlabeled audio data to learn general audio representations. These pre-trained audio models, like those described in Leveraging Diverse Semantic-based Audio Pretrained Models, can then be fine-tuned on the limited singing voice dataset.
Next, the paper uses a latent diffusion model to generate the singing voices. Diffusion models work by progressively adding noise to the input data and then learning to reverse this process to generate new samples. By operating in a learned latent space instead of the raw audio waveform, the latent diffusion approach can produce higher-quality outputs with fewer training samples.
Finally, the authors incorporate self-supervised pitch augmentation, which learns to manipulate the pitch of the singing voices during training. This helps the model generalize to a wider range of pitches and singing styles, further improving data efficiency.
Critical Analysis
The authors acknowledge that MakeSinger still has some limitations. For example, the method may struggle to capture the nuanced expressiveness of professional singers, as it is trained on a limited dataset. Additionally, the paper does not explore the model's ability to handle multiple speakers or languages, which could be important for real-world applications.
Furthermore, while the authors demonstrate impressive results on objective metrics, subjective evaluations of the generated singing voices by human listeners would provide a more complete assessment of the method's capabilities. It would also be valuable to compare MakeSinger's performance to other recent advancements in singing voice synthesis, such as SingIt, to better understand its relative strengths and weaknesses.
Overall, MakeSinger represents an interesting and promising step towards more data-efficient singing voice synthesis. However, further research and real-world evaluations are needed to fully understand the method's potential and limitations.
Conclusion
The MakeSinger paper presents a novel semi-supervised training approach for generating high-quality singing voices from limited data. By leveraging pre-trained audio models, latent diffusion modeling, and self-supervised pitch augmentation, the method can produce realistic singing voices using only a small dataset of professional recordings.
This advance in data-efficient singing voice synthesis could have significant implications for applications like virtual assistants, video games, and other scenarios where personalized singing voices are desirable but collecting large training datasets is challenging. While the method still has room for improvement, the core ideas and techniques introduced in this paper represent an important step forward in the field of singing voice generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MakeSinger: A Semi-Supervised Training Method for Data-Efficient Singing Voice Synthesis via Classifier-free Diffusion Guidance
Semin Kim, Myeonghun Jeong, Hyeonseung Lee, Minchan Kim, Byoung Jin Choi, Nam Soo Kim
In this paper, we propose MakeSinger, a semi-supervised training method for singing voice synthesis (SVS) via classifier-free diffusion guidance. The challenge in SVS lies in the costly process of gathering aligned sets of text, pitch, and audio data. MakeSinger enables the training of the diffusion-based SVS model from any speech and singing voice data regardless of its labeling, thereby enhancing the quality of generated voices with large amount of unlabeled data. At inference, our novel dual guiding mechanism gives text and pitch guidance on the reverse diffusion step by estimating the score of masked input. Experimental results show that the model trained in a semi-supervised manner outperforms other baselines trained only on the labeled data in terms of pronunciation, pitch accuracy and overall quality. Furthermore, we demonstrate that by adding Text-to-Speech (TTS) data in training, the model can synthesize the singing voices of TTS speakers even without their singing voices.
Read more6/11/2024
0
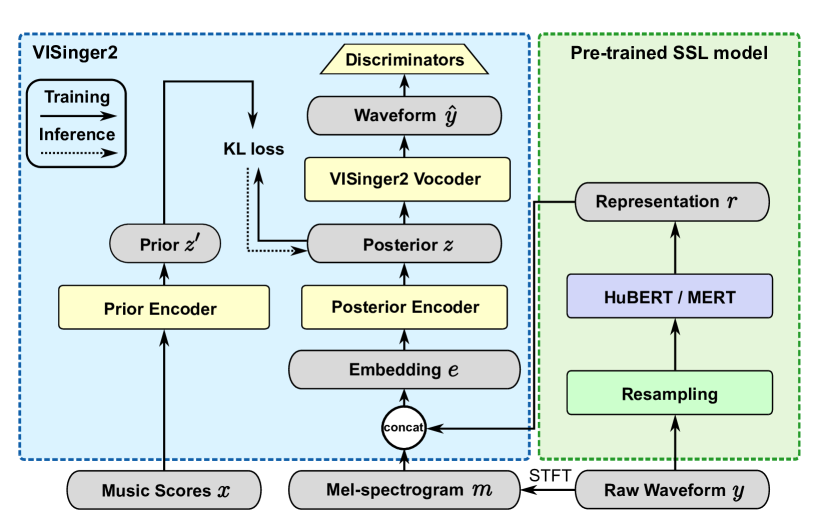
VISinger2+: End-to-End Singing Voice Synthesis Augmented by Self-Supervised Learning Representation
Yifeng Yu, Jiatong Shi, Yuning Wu, Shinji Watanabe
Singing Voice Synthesis (SVS) has witnessed significant advancements with the advent of deep learning techniques. However, a significant challenge in SVS is the scarcity of labeled singing voice data, which limits the effectiveness of supervised learning methods. In response to this challenge, this paper introduces a novel approach to enhance the quality of SVS by leveraging unlabeled data from pre-trained self-supervised learning models. Building upon the existing VISinger2 framework, this study integrates additional spectral feature information into the system to enhance its performance. The integration aims to harness the rich acoustic features from the pre-trained models, thereby enriching the synthesis and yielding a more natural and expressive singing voice. Experimental results in various corpora demonstrate the efficacy of this approach in improving the overall quality of synthesized singing voices in both objective and subjective metrics.
Read more6/14/2024

0
New!DNN-based ensemble singing voice synthesis with interactions between singers
Hiroaki Hyodo, Shinnosuke Takamichi, Tomohiko Nakamura, Junya Koguchi, Hiroshi Saruwatari
We propose a singing voice synthesis (SVS) method for a more unified ensemble singing voice by modeling interactions between singers. Most existing SVS methods aim to synthesize a solo voice, and do not consider interactions between singers, i.e., adjusting one's own voice to the others' voices. Since the production of ensemble voices from solo singing voices ignores the interactions, it can degrade the unity of the vocal ensemble. Therefore, we propose a SVS that reproduces the interactions. It is based on an architecture that uses musical scores of multiple voice parts, and loss functions that simulate the interactions' effect to acoustic features. Experimental results show that our methods improve the unity of the vocal ensemble.
Read more9/17/2024
0
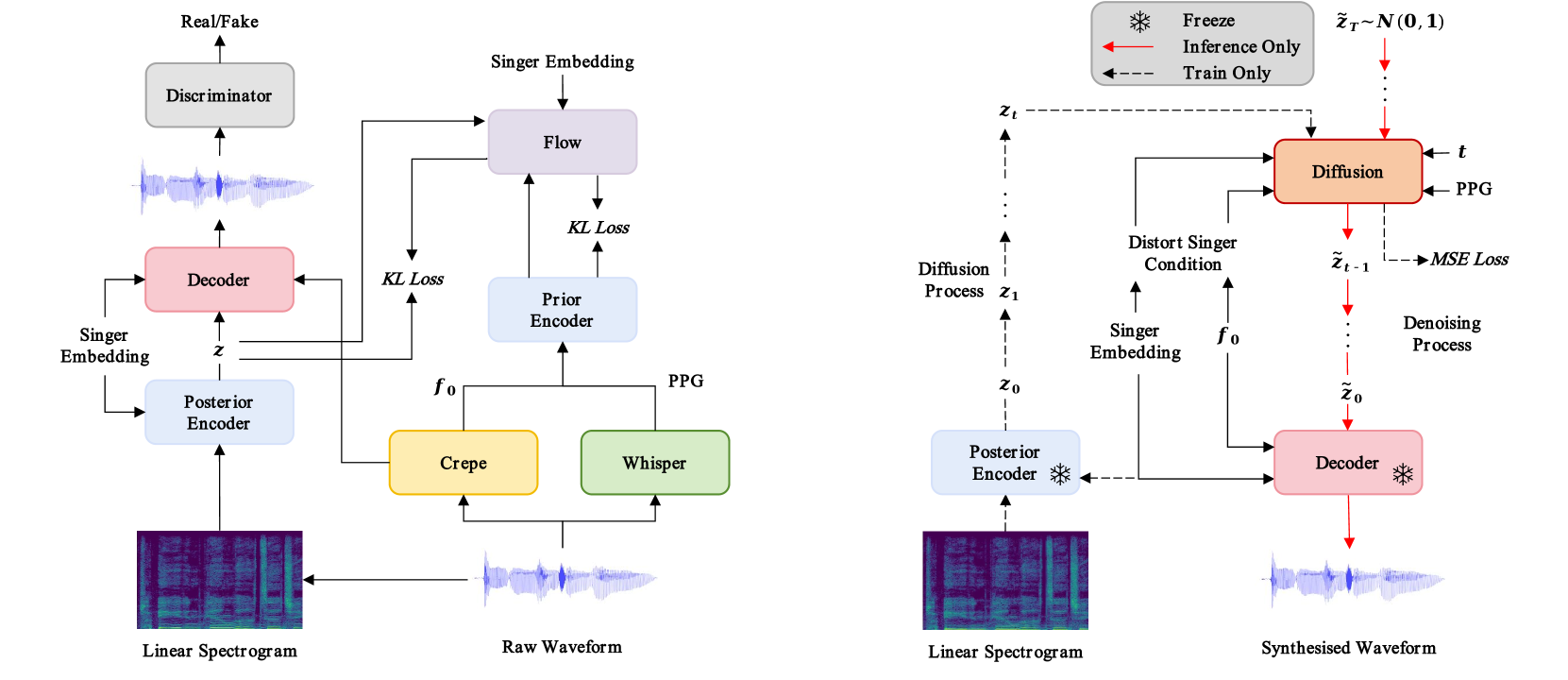
LDM-SVC: Latent Diffusion Model Based Zero-Shot Any-to-Any Singing Voice Conversion with Singer Guidance
Shihao Chen, Yu Gu, Jie Zhang, Na Li, Rilin Chen, Liping Chen, Lirong Dai
Any-to-any singing voice conversion (SVC) is an interesting audio editing technique, aiming to convert the singing voice of one singer into that of another, given only a few seconds of singing data. However, during the conversion process, the issue of timbre leakage is inevitable: the converted singing voice still sounds like the original singer's voice. To tackle this, we propose a latent diffusion model for SVC (LDM-SVC) in this work, which attempts to perform SVC in the latent space using an LDM. We pretrain a variational autoencoder structure using the noted open-source So-VITS-SVC project based on the VITS framework, which is then used for the LDM training. Besides, we propose a singer guidance training method based on classifier-free guidance to further suppress the timbre of the original singer. Experimental results show the superiority of the proposed method over previous works in both subjective and objective evaluations of timbre similarity.
Read more6/11/2024