Do language models plan ahead for future tokens?

3

Sign in to get full access
Overview
- The research paper investigates whether language models plan for future tokens when generating text.
- It proposes a method to measure a language model's ability to plan for future tokens and evaluates several models using this approach.
- The findings suggest that current language models do not exhibit strong planning capabilities and often generate text myopically, focusing only on the immediate next token.
Plain English Explanation
The research paper explores whether language models, which are AI systems that generate human-like text, are able to plan ahead when producing their output. When a language model writes a sentence, it doesn't just look at the current word - it tries to predict what the next word should be based on the context. The researchers wanted to know if these models are actually thinking several steps ahead or if they're mainly focused on the immediate next word.
To test this, the researchers developed a method to measure a language model's planning capabilities. They looked at how well the models could anticipate future tokens (words) in the text they were generating. The idea is that models with stronger planning abilities would be better able to predict not just the next word, but words further down the line.
The researchers evaluated several popular language models using this planning metric. Their findings suggest that current language models do not exhibit strong planning capabilities - the models tend to focus mainly on predicting the immediate next token, without considering the longer-term context. In other words, the models are somewhat myopic in their text generation, not fully taking the future into account.
This research provides important insights into the limitations of modern language models. While these systems can generate fluent and coherent text, they may lack the foresight and strategic thinking that humans often display when communicating. Understanding these shortcomings can help guide future efforts to develop more sophisticated, thoughtful language AI.
Technical Explanation
The paper proposes a method to quantify a language model's ability to plan for future tokens during text generation. The key idea is to measure how well a model can predict not just the next token, but tokens several steps ahead in the sequence.
Specifically, the authors introduce a "future token meta-prediction" task. Given a partially generated sequence, the model must predict the distribution over the next
This meta-prediction capability is used as a proxy for the model's planning ability - models that can accurately forecast future tokens are likely considering the long-term context when generating text, rather than just focusing on the immediate next step.
The authors experiment with several popular language models, including GPT-2, GPT-3, and T5. They find that while these models perform well on standard language modeling benchmarks, they exhibit limited planning abilities as measured by the future token meta-prediction task. The models tend to make myopic predictions, concentrating mainly on the next token rather than considering the longer-term sequence.
These results suggest that current language models, despite their impressive text generation capabilities, may lack the foresight and strategic reasoning displayed by humans during communication. Developing models with stronger planning abilities is an important direction for future research in language AI.
Critical Analysis
The paper provides a novel and thoughtful approach to evaluating the planning capabilities of language models. The future token meta-prediction task offers a concrete way to quantify a model's ability to consider long-term context, which is an important aspect of human-like communication that has received relatively little attention.
However, the authors acknowledge several limitations to their work. The task they propose is somewhat artificial and may not fully capture the nuances of how humans plan their language use. Additionally, the study is focused on a particular set of language models, and it's unclear how generalizable the findings are to other architectures or training approaches.
An important question that the paper does not address is the extent to which planning capabilities are even necessary for language models to succeed on real-world tasks. While the ability to consider long-term context may be desirable for certain applications, it's possible that myopic, token-level prediction is sufficient for many practical use cases.
Further research is needed to better understand the relationship between planning, reasoning, and language generation in AI systems. Exploring alternative evaluation frameworks, as well as the connections between planning abilities and downstream performance, could yield valuable insights for the development of more sophisticated, human-like language models.
Conclusion
This research paper makes an important contribution by introducing a novel way to assess the planning capabilities of language models. The findings suggest that current state-of-the-art models, while impressive in their text generation abilities, often lack the foresight and strategic thinking displayed by humans during communication.
Understanding the limitations of language models in this regard is a crucial step towards developing AI systems that can engage in more thoughtful, context-aware language use. The insights from this work can help guide future research efforts aimed at creating language models with stronger planning abilities, potentially leading to more natural and effective human-AI interactions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
3
Do language models plan ahead for future tokens?
Wilson Wu, John X. Morris, Lionel Levine
Do transformers think ahead during inference at a given position? It is known transformers prepare information in the hidden states of the forward pass at time step $t$ that is then used in future forward passes $t+tau$. We posit two explanations for this phenomenon: pre-caching, in which off-diagonal gradient terms present during training result in the model computing features at $t$ irrelevant to the present inference task but useful for the future, and breadcrumbs, in which features most relevant to time step $t$ are already the same as those that would most benefit inference at time $t+tau$. We test these hypotheses by training language models without propagating gradients to past timesteps, a scheme we formalize as myopic training. In a constructed synthetic data setting, we find clear evidence for pre-caching. In the autoregressive language modeling setting, our experiments are more suggestive of the breadcrumbs hypothesis, though pre-caching increases with model scale.
Read more8/6/2024
0
Learning to Plan Long-Term for Language Modeling
Florian Mai, Nathan Cornille, Marie-Francine Moens
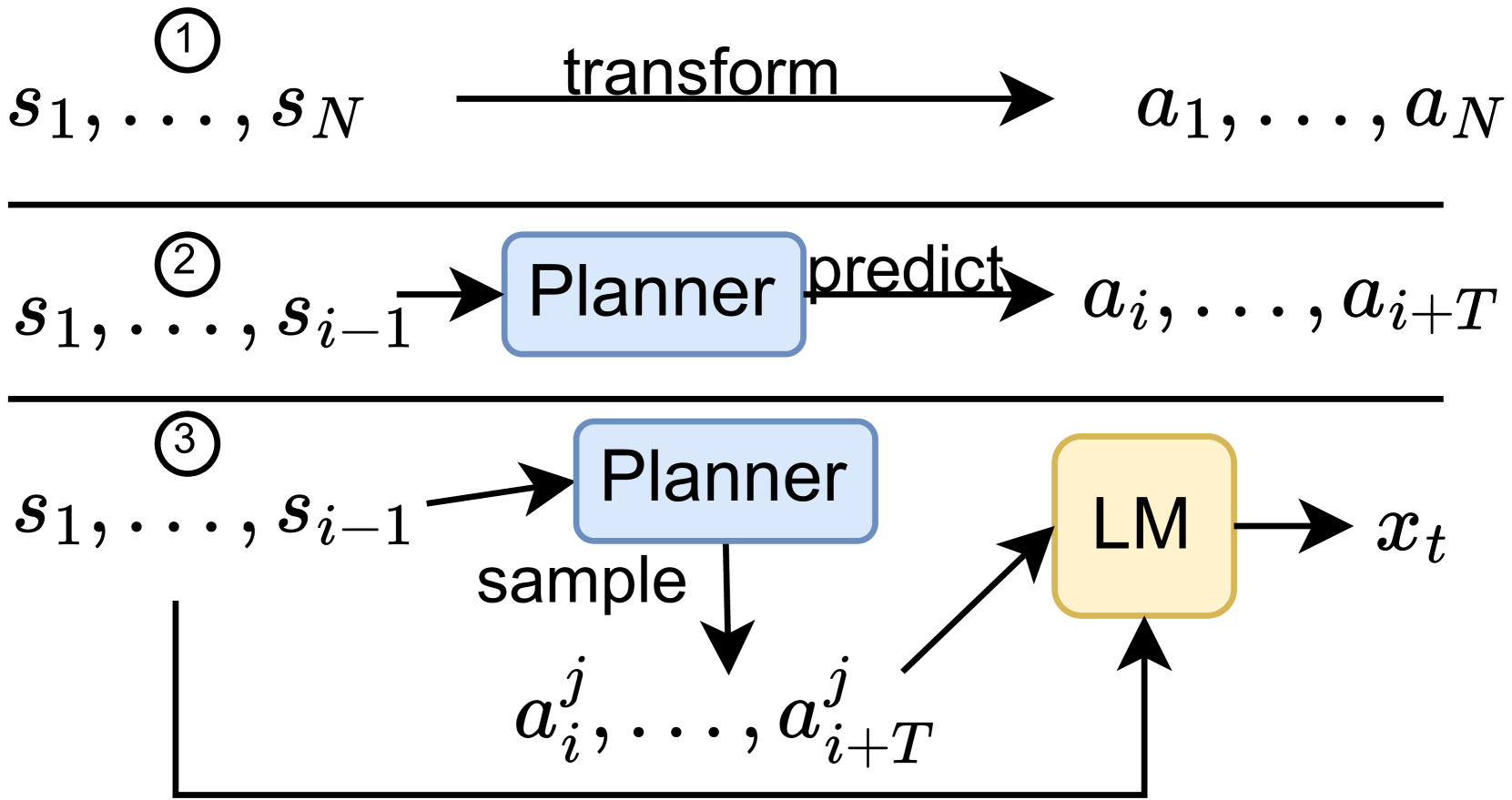
Modern language models predict the next token in the sequence by considering the past text through a powerful function such as attention. However, language models have no explicit mechanism that allows them to spend computation time for planning long-distance future text, leading to a suboptimal token prediction. In this paper, we propose a planner that predicts a latent plan for many sentences into the future. By sampling multiple plans at once, we condition the language model on an accurate approximation of the distribution of text continuations, which leads to better next token prediction accuracy. In effect, this allows trading computation time for prediction accuracy.
Read more9/4/2024
107
Think before you speak: Training Language Models With Pause Tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, Vaishnavh Nagarajan
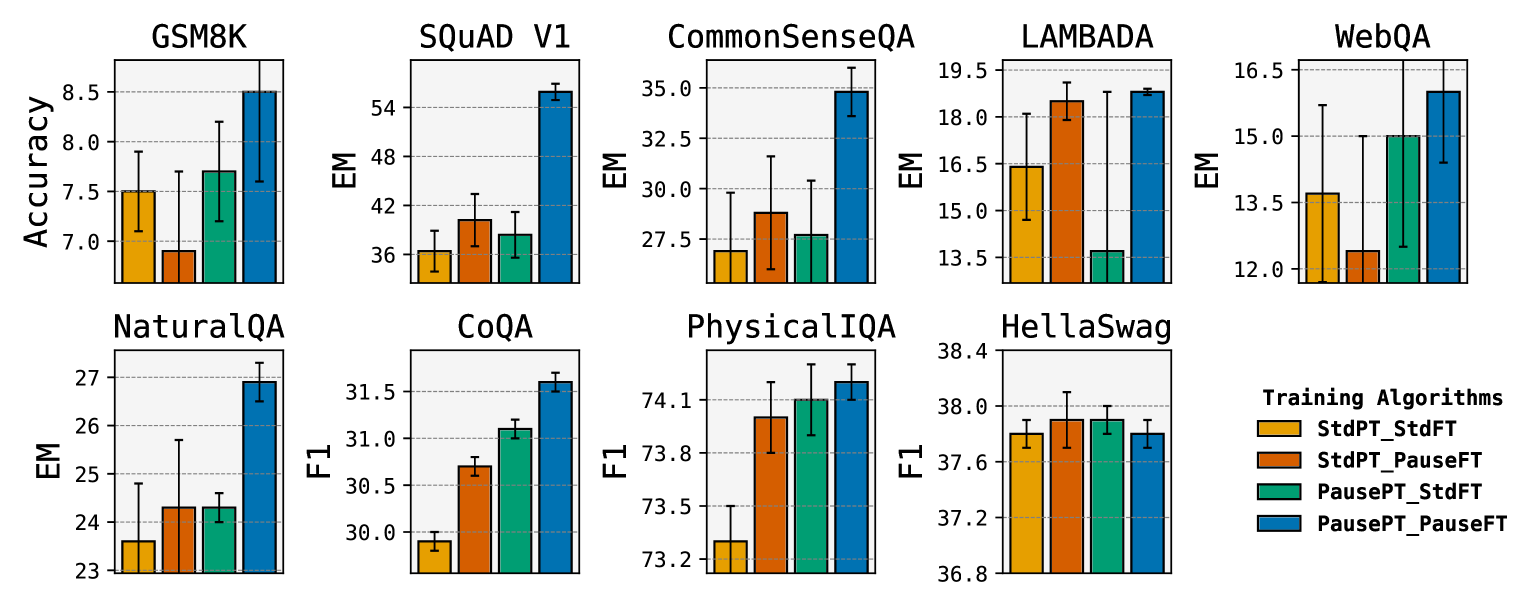
Language models generate responses by producing a series of tokens in immediate succession: the $(K+1)^{th}$ token is an outcome of manipulating $K$ hidden vectors per layer, one vector per preceding token. What if instead we were to let the model manipulate say, $K+10$ hidden vectors, before it outputs the $(K+1)^{th}$ token? We operationalize this idea by performing training and inference on language models with a (learnable) $textit{pause}$ token, a sequence of which is appended to the input prefix. We then delay extracting the model's outputs until the last pause token is seen, thereby allowing the model to process extra computation before committing to an answer. We empirically evaluate $textit{pause-training}$ on decoder-only models of 1B and 130M parameters with causal pretraining on C4, and on downstream tasks covering reasoning, question-answering, general understanding and fact recall. Our main finding is that inference-time delays show gains when the model is both pre-trained and finetuned with delays. For the 1B model, we witness gains on 8 of 9 tasks, most prominently, a gain of $18%$ EM score on the QA task of SQuAD, $8%$ on CommonSenseQA and $1%$ accuracy on the reasoning task of GSM8k. Our work raises a range of conceptual and practical future research questions on making delayed next-token prediction a widely applicable new paradigm.
Read more4/23/2024

0
In-context Time Series Predictor
Jiecheng Lu, Yan Sun, Shihao Yang
Recent Transformer-based large language models (LLMs) demonstrate in-context learning ability to perform various functions based solely on the provided context, without updating model parameters. To fully utilize the in-context capabilities in time series forecasting (TSF) problems, unlike previous Transformer-based or LLM-based time series forecasting methods, we reformulate time series forecasting tasks as input tokens by constructing a series of (lookback, future) pairs within the tokens. This method aligns more closely with the inherent in-context mechanisms, and is more parameter-efficient without the need of using pre-trained LLM parameters. Furthermore, it addresses issues such as overfitting in existing Transformer-based TSF models, consistently achieving better performance across full-data, few-shot, and zero-shot settings compared to previous architectures.
Read more5/27/2024