In-context Time Series Predictor
2405.14982
0
0

Abstract
Recent Transformer-based large language models (LLMs) demonstrate in-context learning ability to perform various functions based solely on the provided context, without updating model parameters. To fully utilize the in-context capabilities in time series forecasting (TSF) problems, unlike previous Transformer-based or LLM-based time series forecasting methods, we reformulate time series forecasting tasks as input tokens by constructing a series of (lookback, future) pairs within the tokens. This method aligns more closely with the inherent in-context mechanisms, and is more parameter-efficient without the need of using pre-trained LLM parameters. Furthermore, it addresses issues such as overfitting in existing Transformer-based TSF models, consistently achieving better performance across full-data, few-shot, and zero-shot settings compared to previous architectures.
Create account to get full access
Overview
- The paper presents an "In-context Time Series Predictor" model for forecasting future values in time series data.
- The model leverages large language models and their ability to learn from context to improve time series prediction performance.
- The authors demonstrate the model's effectiveness on several benchmark time series forecasting tasks.
Plain English Explanation
The paper describes a new machine learning model called the "In-context Time Series Predictor" that can be used to forecast future values in time series data. Time series data refers to a sequence of data points collected over time, such as stock prices, weather measurements, or website traffic.
The key insight behind the model is that large language models, like those used for tasks like text generation, have a remarkable ability to learn from contextual information. The authors hypothesized that this context-learning capability could also be harnessed to improve time series forecasting.
Rather than relying solely on the historical values in the time series, the In-context Time Series Predictor model takes into account additional contextual information that may be relevant to the forecasting task. This could include related data streams, external events, or even text-based descriptions of the time series.
By incorporating this broader context, the model is able to make more accurate predictions of future values compared to traditional time series forecasting approaches. The authors demonstrate the effectiveness of their model on several standard benchmarks for time series forecasting, showing improvements over existing methods.
The significance of this work is that it showcases how the powerful context-learning capabilities of large language models can be leveraged to tackle challenging prediction problems beyond just language tasks. This opens up exciting possibilities for applying these models to a wide range of real-world forecasting and decision-making challenges.
Technical Explanation
The core of the "In-context Time Series Predictor" model is a transformer-based architecture that is able to learn from both the historical values in the time series as well as relevant contextual information.
The model takes as input the current and past values of the time series, along with any auxiliary data streams or textual descriptions that may provide additional context. It then uses a series of transformer layers to encode this information and generate a prediction for the next time step.
The authors draw inspiration from recent work on autoregressive time series forecasting models and context learning abilities of large language models, adapting these techniques to the time series domain.
Experiments on a variety of standard time series forecasting benchmarks demonstrate the effectiveness of the In-context Time Series Predictor model, with significant improvements over traditional time series forecasting approaches and other recent neural network-based methods.
Critical Analysis
The paper provides a compelling demonstration of how the context-learning capabilities of large language models can be leveraged to enhance time series forecasting. However, the authors acknowledge several important limitations and avenues for future research.
One key limitation is the computational cost and resource requirements of the transformer-based architecture, which may limit its practical deployment, especially for resource-constrained applications. The authors suggest exploring more efficient model architectures or alternative training strategies to address this issue.
Additionally, the paper focuses primarily on evaluating the model's performance on standard benchmark datasets. While this is a common practice in machine learning research, it raises questions about the model's generalization to real-world time series data, which may exhibit different characteristics and challenges.
Further research is needed to understand the model's robustness to noisy, incomplete, or irregularly sampled time series data, as well as its ability to handle temporal dependencies and structural breaks that are often present in real-world time series.
Finally, the paper does not provide a detailed analysis of the types of contextual information that are most beneficial for time series forecasting. Investigating the relative importance of different contextual features and how they interact with the time series data could lead to important insights and guide the development of more effective forecasting models.
Conclusion
The "In-context Time Series Predictor" model presented in this paper represents a promising step forward in leveraging the context-learning capabilities of large language models to tackle time series forecasting challenges. By incorporating relevant contextual information beyond just the historical values in the time series, the model demonstrates significant performance improvements on benchmark tasks.
This work highlights the potential for cross-pollination between advancements in language modeling and other domains, such as time series analysis, and opens up exciting avenues for future research. As the field of large language models continues to evolve, the opportunities to apply these powerful techniques to a wide range of real-world forecasting and decision-making problems are likely to grow.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Transformers Learn Temporal Difference Methods for In-Context Reinforcement Learning
Jiuqi Wang, Ethan Blaser, Hadi Daneshmand, Shangtong Zhang
0
0
In-context learning refers to the learning ability of a model during inference time without adapting its parameters. The input (i.e., prompt) to the model (e.g., transformers) consists of both a context (i.e., instance-label pairs) and a query instance. The model is then able to output a label for the query instance according to the context during inference. A possible explanation for in-context learning is that the forward pass of (linear) transformers implements iterations of gradient descent on the instance-label pairs in the context. In this paper, we prove by construction that transformers can also implement temporal difference (TD) learning in the forward pass, a phenomenon we refer to as in-context TD. We demonstrate the emergence of in-context TD after training the transformer with a multi-task TD algorithm, accompanied by theoretical analysis. Furthermore, we prove that transformers are expressive enough to implement many other policy evaluation algorithms in the forward pass, including residual gradient, TD with eligibility trace, and average-reward TD.
5/28/2024
🏋️
Breaking through the learning plateaus of in-context learning in Transformer
Jingwen Fu, Tao Yang, Yuwang Wang, Yan Lu, Nanning Zheng
0
0
In-context learning, i.e., learning from context examples, is an impressive ability of Transformer. Training Transformers to possess this in-context learning skill is computationally intensive due to the occurrence of learning plateaus, which are periods within the training process where there is minimal or no enhancement in the model's in-context learning capability. To study the mechanism behind the learning plateaus, we conceptually seperate a component within the model's internal representation that is exclusively affected by the model's weights. We call this the weights component, and the remainder is identified as the context component. By conducting meticulous and controlled experiments on synthetic tasks, we note that the persistence of learning plateaus correlates with compromised functionality of the weights component. Recognizing the impaired performance of the weights component as a fundamental behavior drives learning plateaus, we have developed three strategies to expedite the learning of Transformers. The effectiveness of these strategies is further confirmed in natural language processing tasks. In conclusion, our research demonstrates the feasibility of cultivating a powerful in-context learning ability within AI systems in an eco-friendly manner.
6/7/2024
💬
AutoTimes: Autoregressive Time Series Forecasters via Large Language Models
Yong Liu, Guo Qin, Xiangdong Huang, Jianmin Wang, Mingsheng Long
0
0
Foundation models of time series have not been fully developed due to the limited availability of time series corpora and the underexploration of scalable pre-training. Based on the similar sequential formulation of time series and natural language, increasing research demonstrates the feasibility of leveraging large language models (LLM) for time series. Nevertheless, the inherent autoregressive property and decoder-only architecture of LLMs have not been fully considered, resulting in insufficient utilization of LLM abilities. To further exploit the general-purpose token transition and multi-step generation ability of large language models, we propose AutoTimes to repurpose LLMs as autoregressive time series forecasters, which independently projects time series segments into the embedding space and autoregressively generates future predictions with arbitrary lengths. Compatible with any decoder-only LLMs, the consequent forecaster exhibits the flexibility of the lookback length and scalability of the LLM size. Further, we formulate time series as prompts, extending the context for prediction beyond the lookback window, termed in-context forecasting. By adopting textual timestamps as position embeddings, AutoTimes integrates multimodality for multivariate scenarios. Empirically, AutoTimes achieves state-of-the-art with 0.1% trainable parameters and over 5 times training/inference speedup compared to advanced LLM-based forecasters.
5/24/2024
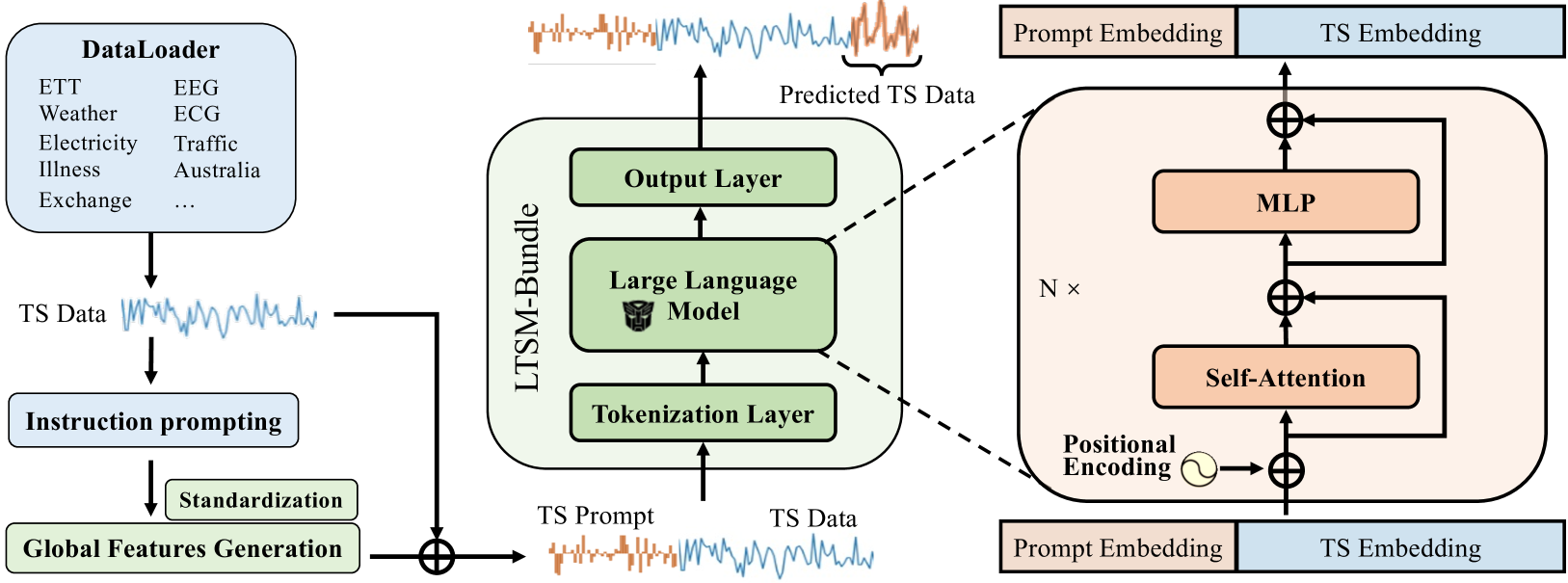
Understanding Different Design Choices in Training Large Time Series Models
Yu-Neng Chuang, Songchen Li, Jiayi Yuan, Guanchu Wang, Kwei-Herng Lai, Leisheng Yu, Sirui Ding, Chia-Yuan Chang, Qiaoyu Tan, Daochen Zha, Xia Hu
0
0
Inspired by Large Language Models (LLMs), Time Series Forecasting (TSF), a long-standing task in time series analysis, is undergoing a transition towards Large Time Series Models (LTSMs), aiming to train universal transformer-based models for TSF. However, training LTSMs on heterogeneous time series data poses unique challenges, including diverse frequencies, dimensions, and patterns across datasets. Recent endeavors have studied and evaluated various design choices aimed at enhancing LTSM training and generalization capabilities, spanning pre-processing techniques, model configurations, and dataset configurations. In this work, we comprehensively analyze these design choices and aim to identify the best practices for training LTSM. Moreover, we propose emph{time series prompt}, a novel statistical prompting strategy tailored to time series data. Furthermore, based on the observations in our analysis, we introduce texttt{LTSM-bundle}, which bundles the best design choices we have identified. Empirical results demonstrate that texttt{LTSM-bundle} achieves superior zero-shot and few-shot performances compared to state-of-the-art LSTMs and traditional TSF methods on benchmark datasets.
6/21/2024