On the Shape of Brainscores for Large Language Models (LLMs)
2405.06725
0
0

Abstract
With the rise of Large Language Models (LLMs), the novel metric Brainscore emerged as a means to evaluate the functional similarity between LLMs and human brain/neural systems. Our efforts were dedicated to mining the meaning of the novel score by constructing topological features derived from both human fMRI data involving 190 subjects, and 39 LLMs plus their untrained counterparts. Subsequently, we trained 36 Linear Regression Models and conducted thorough statistical analyses to discern reliable and valid features from our constructed ones. Our findings reveal distinctive feature combinations conducive to interpreting existing brainscores across various brain regions of interest (ROIs) and hemispheres, thereby significantly contributing to advancing interpretable machine learning (iML) studies. The study is enriched by our further discussions and analyses concerning existing brainscores. To our knowledge, this study represents the first attempt to comprehend the novel metric brainscore within this interdisciplinary domain.
Create account to get full access
Overview
- This paper investigates the relationship between large language models (LLMs) and brain scores, which measure how well a model's representations align with human brain activity.
- The authors analyze the shape of the brainscore distribution for different LLMs, finding some models have a heavy-tailed distribution with many low-scoring examples.
- They also explore how model size, pretraining data, and fine-tuning affect brainscore distributions.
Plain English Explanation
The paper looks at how well the internal representations (the "thoughts") of large language models, which are AI systems trained on huge amounts of text data, match up with the patterns of brain activity in humans when they process language.
The researchers found that some of these language models have a "heavy-tailed" distribution of brain scores - meaning there are many examples where the model's internal representation is quite different from how a human brain would process that same language. In other words, the model is not always thinking about language in the same way a person would.
The paper also examines how factors like the size of the language model, the data it was trained on, and any additional training it received, can influence this brain score distribution. Certain model configurations seem to produce more human-like internal representations than others.
Technical Explanation
The paper investigates the distribution of "brainscores" for different large language models (LLMs). Brainscores measure how well a model's internal representations align with human brain activity patterns when processing the same language input.
The authors analyze the brainscore distributions for several popular LLMs, including METRIC-AWARE LLM INFERENCE, Aspects of Human Memory, and Probing Large Language Models from Human Behavior. They find that some models exhibit heavy-tailed brainscore distributions, with many examples scoring poorly compared to human brain activity.
The paper explores how model scale, pretraining data, and fine-tuning affect these brainscore distributions. Larger models trained on more diverse data tend to have higher overall brainscores, but the heavy-tailed shape persists, suggesting fundamental misalignments between LLM representations and human cognition.
Critical Analysis
The paper provides valuable insights into the relationship between LLM representations and human brain activity. However, it does not explore the underlying reasons for the observed heavy-tailed brainscore distributions. More research is needed to understand the cognitive and neural processes that give rise to these divergences between LLM "thought" and human "thought".
Additionally, the paper only examines a limited set of LLMs. Multilingual Brain Surgeon and other models not included in this study may have different brainscore distributions that could provide additional insights.
Further analysis of how specific architectural choices, training regimes, or model fine-tuning affect brainscore alignment with human cognition would also be beneficial for understanding and improving the cognitive plausibility of LLMs.
Conclusion
This paper sheds light on an important aspect of large language models - the degree to which their internal representations match human brain activity when processing language. The finding of heavy-tailed brainscore distributions suggests fundamental misalignments between LLM "thinking" and human "thinking" that merit further investigation.
Understanding these gaps between machine and human cognition could lead to more human-centric language models that better capture the nuances of human language understanding. This, in turn, could improve the performance and trustworthiness of LLMs in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
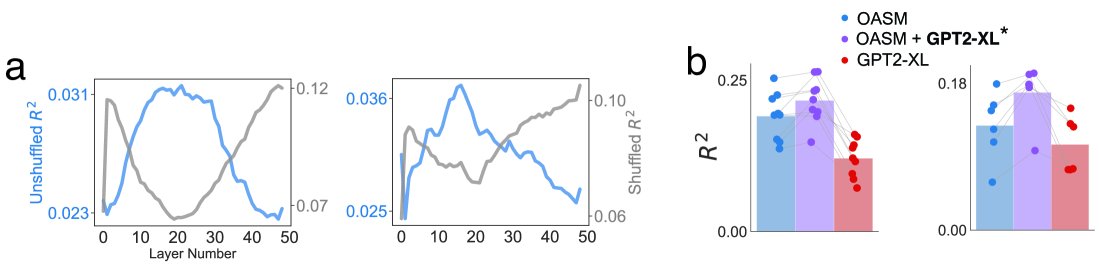
What Are Large Language Models Mapping to in the Brain? A Case Against Over-Reliance on Brain Scores
Ebrahim Feghhi, Nima Hadidi, Bryan Song, Idan A. Blank, Jonathan C. Kao
0
0
Given the remarkable capabilities of large language models (LLMs), there has been a growing interest in evaluating their similarity to the human brain. One approach towards quantifying this similarity is by measuring how well a model predicts neural signals, also called brain score. Internal representations from LLMs achieve state-of-the-art brain scores, leading to speculation that they share computational principles with human language processing. This inference is only valid if the subset of neural activity predicted by LLMs reflects core elements of language processing. Here, we question this assumption by analyzing three neural datasets used in an impactful study on LLM-to-brain mappings, with a particular focus on an fMRI dataset where participants read short passages. We first find that when using shuffled train-test splits, as done in previous studies with these datasets, a trivial feature that encodes temporal autocorrelation not only outperforms LLMs but also accounts for the majority of neural variance that LLMs explain. We therefore use contiguous splits moving forward. Second, we explain the surprisingly high brain scores of untrained LLMs by showing they do not account for additional neural variance beyond two simple features: sentence length and sentence position. This undermines evidence used to claim that the transformer architecture biases computations to be more brain-like. Third, we find that brain scores of trained LLMs on this dataset can largely be explained by sentence length, position, and pronoun-dereferenced static word embeddings; a small, additional amount is explained by sense-specific embeddings and contextual representations of sentence structure. We conclude that over-reliance on brain scores can lead to over-interpretations of similarity between LLMs and brains, and emphasize the importance of deconstructing what LLMs are mapping to in neural signals.
6/24/2024
Do Large Language Models Mirror Cognitive Language Processing?
Yuqi Ren, Renren Jin, Tongxuan Zhang, Deyi Xiong
0
0
Large Language Models (LLMs) have demonstrated remarkable abilities in text comprehension and logical reasoning, indicating that the text representations learned by LLMs can facilitate their language processing capabilities. In cognitive science, brain cognitive processing signals are typically utilized to study human language processing. Therefore, it is natural to ask how well the text embeddings from LLMs align with the brain cognitive processing signals, and how training strategies affect the LLM-brain alignment? In this paper, we employ Representational Similarity Analysis (RSA) to measure the alignment between 23 mainstream LLMs and fMRI signals of the brain to evaluate how effectively LLMs simulate cognitive language processing. We empirically investigate the impact of various factors (e.g., pre-training data size, model scaling, alignment training, and prompts) on such LLM-brain alignment. Experimental results indicate that pre-training data size and model scaling are positively correlated with LLM-brain similarity, and alignment training can significantly improve LLM-brain similarity. Explicit prompts contribute to the consistency of LLMs with brain cognitive language processing, while nonsensical noisy prompts may attenuate such alignment. Additionally, the performance of a wide range of LLM evaluations (e.g., MMLU, Chatbot Arena) is highly correlated with the LLM-brain similarity.
5/29/2024
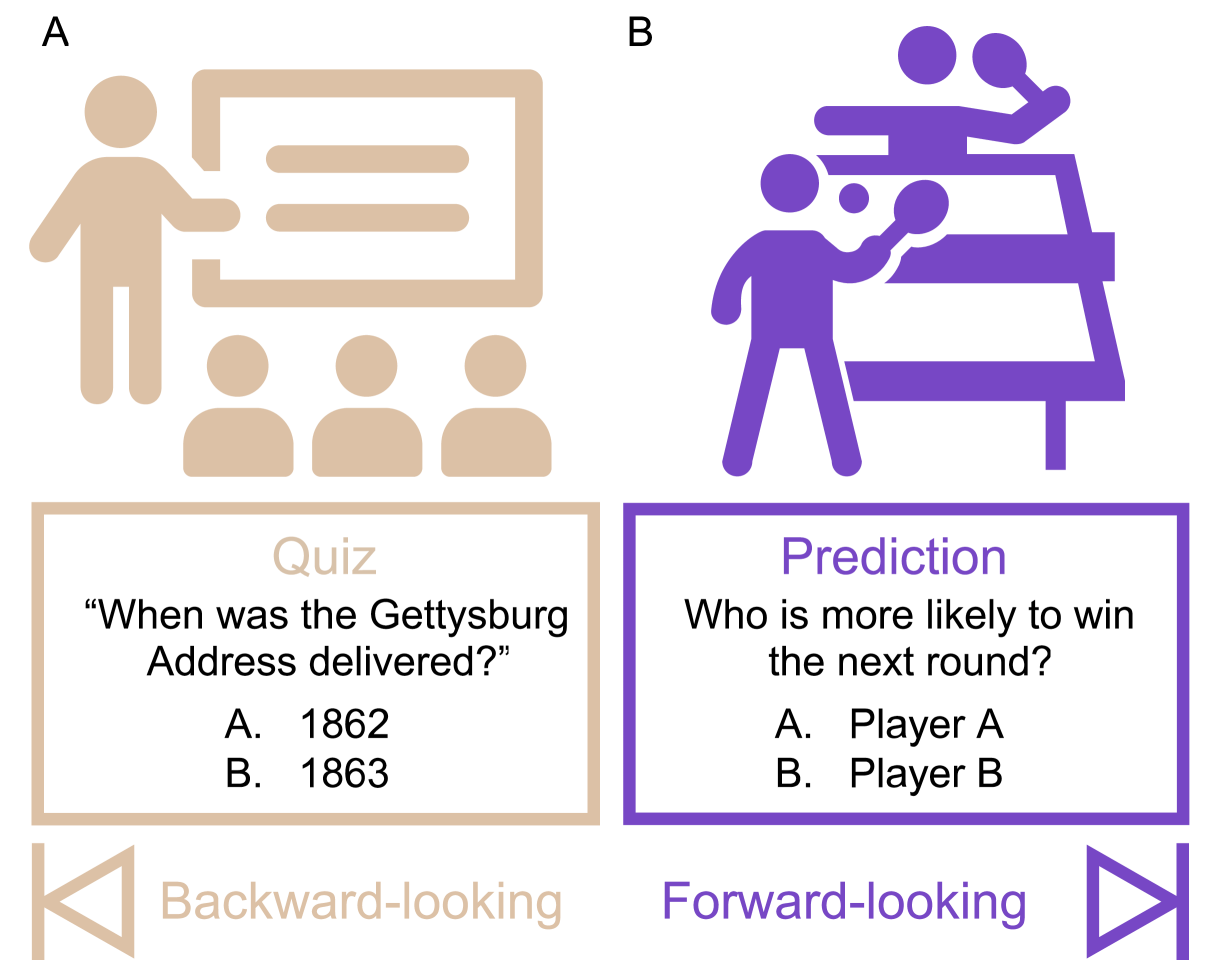
Large language models surpass human experts in predicting neuroscience results
Xiaoliang Luo, Akilles Rechardt, Guangzhi Sun, Kevin K. Nejad, Felipe Y'a~nez, Bati Yilmaz, Kangjoo Lee, Alexandra O. Cohen, Valentina Borghesani, Anton Pashkov, Daniele Marinazzo, Jonathan Nicholas, Alessandro Salatiello, Ilia Sucholutsky, Pasquale Minervini, Sepehr Razavi, Roberta Rocca, Elkhan Yusifov, Tereza Okalova, Nianlong Gu, Martin Ferianc, Mikail Khona, Kaustubh R. Patil, Pui-Shee Lee, Rui Mata, Nicholas E. Myers, Jennifer K Bizley, Sebastian Musslick, Isil Poyraz Bilgin, Guiomar Niso, Justin M. Ales, Michael Gaebler, N Apurva Ratan Murty, Leyla Loued-Khenissi, Anna Behler, Chloe M. Hall, Jessica Dafflon, Sherry Dongqi Bao, Bradley C. Love
0
0
Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
6/24/2024
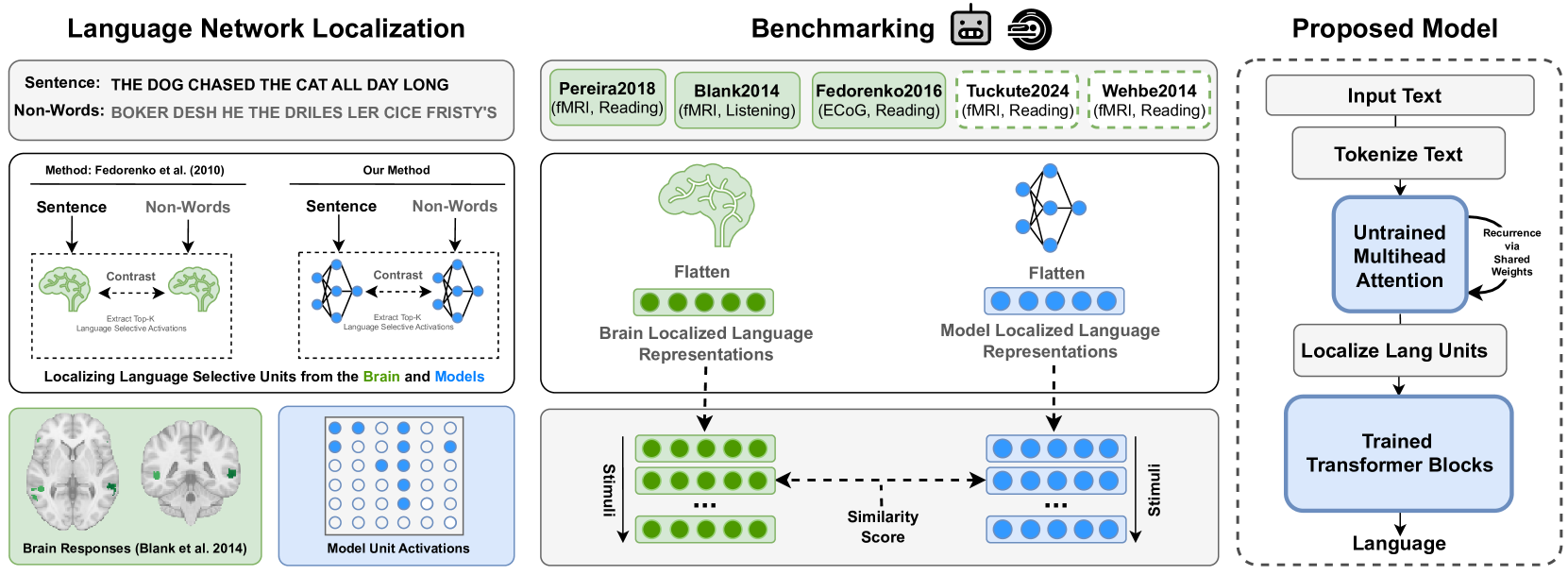
Brain-Like Language Processing via a Shallow Untrained Multihead Attention Network
Badr AlKhamissi, Greta Tuckute, Antoine Bosselut, Martin Schrimpf
0
0
Large Language Models (LLMs) have been shown to be effective models of the human language system, with some models predicting most explainable variance of brain activity in current datasets. Even in untrained models, the representations induced by architectural priors can exhibit reasonable alignment to brain data. In this work, we investigate the key architectural components driving the surprising alignment of untrained models. To estimate LLM-to-brain similarity, we first select language-selective units within an LLM, similar to how neuroscientists identify the language network in the human brain. We then benchmark the brain alignment of these LLM units across five different brain recording datasets. By isolating critical components of the Transformer architecture, we identify tokenization strategy and multihead attention as the two major components driving brain alignment. A simple form of recurrence further improves alignment. We further demonstrate this quantitative brain alignment of our model by reproducing landmark studies in the language neuroscience field, showing that localized model units -- just like language voxels measured empirically in the human brain -- discriminate more reliably between lexical than syntactic differences, and exhibit similar response profiles under the same experimental conditions. Finally, we demonstrate the utility of our model's representations for language modeling, achieving improved sample and parameter efficiency over comparable architectures. Our model's estimates of surprisal sets a new state-of-the-art in the behavioral alignment to human reading times. Taken together, we propose a highly brain- and behaviorally-aligned model that conceptualizes the human language system as an untrained shallow feature encoder, with structural priors, combined with a trained decoder to achieve efficient and performant language processing.
6/24/2024