Do No Harm: A Counterfactual Approach to Safe Reinforcement Learning

0
🏅
Sign in to get full access
Overview
- This paper presents a novel approach to safe reinforcement learning, addressing the challenge of learning policies that satisfy complex safety constraints in real-world environments.
- The authors introduce a framework for safe reinforcement learning with learned non-Markovian safety constraints, which allows for the representation and optimization of safety objectives that depend on the entire history of an agent's interactions.
- The proposed constraint manifold theory and applications provide a principled way to incorporate complex safety constraints into the reinforcement learning process, ensuring that learned policies are feasible and satisfy the desired safety requirements.
Plain English Explanation
Reinforcement learning is a powerful approach for training AI systems to make decisions and take actions in complex environments. However, in many real-world applications, it's crucial that the AI system's behavior satisfies certain safety constraints, such as avoiding collisions, maintaining stable operation, or respecting ethical principles.
This paper introduces a new framework that allows reinforcement learning agents to learn policies that not only maximize their performance objectives but also adhere to complex safety constraints. The key insight is that these safety constraints may depend on the entire history of the agent's interactions, rather than just the current state (the Markov property).
The authors propose a way to represent and optimize these non-Markovian safety constraints, which can capture a wide range of safety requirements. They develop a constraint manifold theory that provides a principled approach to incorporating these constraints into the reinforcement learning process, ensuring that the learned policies are both high-performing and feasible.
By addressing the challenge of safe reinforcement learning, this work has the potential to enable the deployment of more capable and trustworthy AI systems in high-stakes domains, such as autonomous vehicles, healthcare, and industrial robotics, where safety is of paramount importance.
Technical Explanation
The key technical contributions of the paper are:
-
Non-Markovian Safety Constraints: The authors introduce a framework for representing and learning safety constraints that depend on the entire history of an agent's interactions, rather than just the current state. This allows for the encoding of more complex safety objectives that cannot be captured by standard Markovian constraints.
-
Constraint Manifold Theory and Applications: The authors develop a constraint manifold theory that provides a principled way to incorporate these non-Markovian safety constraints into the reinforcement learning process. This involves constructing a constraint manifold that represents the feasible set of policies that satisfy the safety requirements, and then optimizing within this manifold to find high-performing, safe policies.
-
Feasibility-Consistent Representation Learning: The authors propose a novel representation learning approach that ensures the learned features are aligned with the safety constraints, facilitating the optimization of safe policies within the constraint manifold.
-
Saliency-Aware Counterfactual Explainer: To improve the interpretability of the learned safe policies, the authors develop a saliency-aware counterfactual explainer that can identify the key factors contributing to a policy's safety.
The paper evaluates the proposed framework on several benchmark reinforcement learning tasks, demonstrating its ability to learn safe policies that satisfy complex constraints while maintaining high performance.
Critical Analysis
The paper presents a comprehensive and principled approach to the problem of safe reinforcement learning, addressing important limitations of existing methods. The authors' constraint manifold theory provides a strong theoretical foundation for incorporating non-Markovian safety constraints into the learning process, which is a significant advancement in the field.
One potential limitation of the approach is the computational complexity associated with constructing and optimizing within the constraint manifold, especially as the complexity of the safety constraints increases. The authors acknowledge this challenge and suggest potential directions for improving the scalability of the method.
Additionally, the paper focuses on safety constraints that can be represented as constraints on the policy (i.e., the mapping from states to actions). There may be other types of safety requirements, such as constraints on the state dynamics or the reward function, that are not explicitly addressed in this work and could be an area for future research.
Finally, while the paper includes a saliency-aware counterfactual explainer to improve the interpretability of the learned policies, further work may be needed to ensure that these explanations are intuitive and meaningful to human users, especially in high-stakes applications where trust and transparency are crucial.
Overall, this paper represents an important contribution to the field of safe reinforcement learning, providing a strong theoretical foundation and practical techniques for learning policies that satisfy complex safety constraints. The insights and methods presented here have the potential to enable the development of more robust and trustworthy AI systems in a wide range of real-world applications.
Conclusion
This paper introduces a novel framework for safe reinforcement learning that addresses the challenge of learning policies that satisfy complex, non-Markovian safety constraints. The authors' constraint manifold theory and feasibility-consistent representation learning techniques provide a principled approach to incorporating these safety requirements into the reinforcement learning process, ensuring that the learned policies are both high-performing and safe.
By addressing this critical challenge, the methods presented in this paper have the potential to enable the deployment of more capable and trustworthy AI systems in a wide range of high-stakes domains, such as autonomous vehicles, healthcare, and industrial robotics, where safety is of paramount importance. The inclusion of a saliency-aware counterfactual explainer also enhances the interpretability of the learned safe policies, which is essential for building user trust and acceptance.
Overall, this work represents a significant advancement in the field of safe reinforcement learning and lays the groundwork for further research and development in this important area of AI safety.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Do No Harm: A Counterfactual Approach to Safe Reinforcement Learning
Sean Vaskov, Wilko Schwarting, Chris L. Baker
Reinforcement Learning (RL) for control has become increasingly popular due to its ability to learn rich feedback policies that take into account uncertainty and complex representations of the environment. When considering safety constraints, constrained optimization approaches, where agents are penalized for constraint violations, are commonly used. In such methods, if agents are initialized in, or must visit, states where constraint violation might be inevitable, it is unclear how much they should be penalized. We address this challenge by formulating a constraint on the counterfactual harm of the learned policy compared to a default, safe policy. In a philosophical sense this formulation only penalizes the learner for constraint violations that it caused; in a practical sense it maintains feasibility of the optimal control problem. We present simulation studies on a rover with uncertain road friction and a tractor-trailer parking environment that demonstrate our constraint formulation enables agents to learn safer policies than contemporary constrained RL methods.
Read more5/21/2024
🤖
0
Enhancing RL Safety with Counterfactual LLM Reasoning
Dennis Gross, Helge Spieker
Reinforcement learning (RL) policies may exhibit unsafe behavior and are hard to explain. We use counterfactual large language model reasoning to enhance RL policy safety post-training. We show that our approach improves and helps to explain the RL policy safety.
Read more9/17/2024
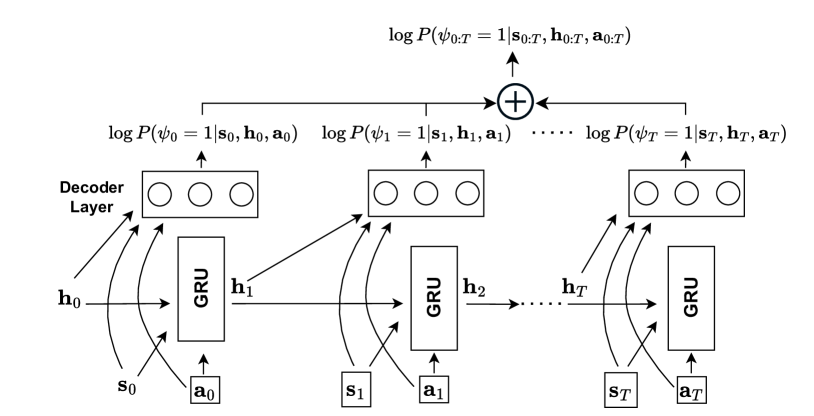
0
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
Read more5/7/2024
🏅
0
A Survey of Constraint Formulations in Safe Reinforcement Learning
Akifumi Wachi, Xun Shen, Yanan Sui
Safety is critical when applying reinforcement learning (RL) to real-world problems. As a result, safe RL has emerged as a fundamental and powerful paradigm for optimizing an agent's policy while incorporating notions of safety. A prevalent safe RL approach is based on a constrained criterion, which seeks to maximize the expected cumulative reward subject to specific safety constraints. Despite recent effort to enhance safety in RL, a systematic understanding of the field remains difficult. This challenge stems from the diversity of constraint representations and little exploration of their interrelations. To bridge this knowledge gap, we present a comprehensive review of representative constraint formulations, along with a curated selection of algorithms designed specifically for each formulation. In addition, we elucidate the theoretical underpinnings that reveal the mathematical mutual relations among common problem formulations. We conclude with a discussion of the current state and future directions of safe reinforcement learning research.
Read more5/9/2024