Do not think pink elephant!
2404.15154
2
0
🧪
Abstract
Large Models (LMs) have heightened expectations for the potential of general AI as they are akin to human intelligence. This paper shows that recent large models such as Stable Diffusion and DALL-E3 also share the vulnerability of human intelligence, namely the white bear phenomenon. We investigate the causes of the white bear phenomenon by analyzing their representation space. Based on this analysis, we propose a simple prompt-based attack method, which generates figures prohibited by the LM provider's policy. To counter these attacks, we introduce prompt-based defense strategies inspired by cognitive therapy techniques, successfully mitigating attacks by up to 48.22%.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) like Stable Diffusion and DALL-E3 have raised expectations for the potential of general AI, as they seem to exhibit capabilities akin to human intelligence.
- However, this paper shows that these recent LLMs also share a vulnerability of human intelligence - the "white bear phenomenon."
- The researchers investigate the causes of this phenomenon by analyzing the representation space of these LLMs.
- Based on their analysis, they propose a simple prompt-based attack method that can generate figures prohibited by the LM provider's policy.
- To counter these attacks, the researchers introduce prompt-based defense strategies inspired by cognitive therapy techniques, successfully mitigating the attacks by up to 48.22%.
Plain English Explanation
Large language models (LLMs) like Stable Diffusion and DALL-E3 have made impressive strides, leading many to believe that they are getting closer to achieving general artificial intelligence (AI) on par with human intelligence. However, this new research paper shows that these advanced LLMs share a common vulnerability with human intelligence - the "white bear phenomenon."
The white bear phenomenon refers to the tendency of people to have difficulty not thinking about something once it has been mentioned to them. For example, if someone tells you not to think about a white bear, you'll likely find it hard to get the image of a white bear out of your mind.
The researchers investigated this phenomenon in the context of these large language models, analyzing their internal representations to understand what might be causing it. Based on their analysis, they developed a simple technique that can trick the models into generating content that the model's creators had explicitly prohibited.
To counter these attacks, the researchers came up with some defense strategies, drawing inspiration from cognitive therapy techniques used to help people overcome unwanted thought patterns. These defenses were able to significantly reduce the impact of the attacks, mitigating them by up to 48.22%.
The key takeaway is that even as language models become more advanced, they can still exhibit some of the same vulnerabilities and limitations as the human mind. This research highlights the need to carefully study and address these issues as we work towards developing more robust and reliable AI systems.
Technical Explanation
The researchers in this paper investigate the "white bear phenomenon" - a well-known quirk of human cognition where people struggle to avoid thinking about something once it has been mentioned to them - in the context of recent large language models (LLMs) like Stable Diffusion and DALL-E3.
Through an analysis of the representation space of these LLMs, the researchers found that they too exhibit this vulnerability, despite their impressive capabilities that seem to approach human-level intelligence. Building on this insight, the researchers propose a simple prompt-based attack method that can generate content prohibited by the LM provider's policy.
To counter these attacks, the researchers introduce prompt-based defense strategies inspired by cognitive therapy techniques used to help people overcome unwanted thought patterns, such as learning to disguise and avoid refusal responses and understanding the aspects of human memory that are reflected in LLMs. These defensive measures were able to successfully mitigate the attacks by up to 48.22%.
The findings of this paper highlight the need to carefully study the biases and limitations of language models as they become more advanced, even as they approach human-level capabilities. The white bear phenomenon suggests that these models may still share some fundamental vulnerabilities with the human mind, which will need to be addressed as we work towards developing more robust and reliable AI systems.
Critical Analysis
The researchers in this paper provide a compelling analysis of the "white bear phenomenon" in the context of large language models (LLMs), which is a valuable contribution to our understanding of the limitations and vulnerabilities of these increasingly capable systems.
One key strength of the paper is the researchers' thorough investigation of the underlying causes of this phenomenon by analyzing the representation space of the LLMs. This level of technical insight is crucial for developing effective countermeasures.
However, the paper could have benefited from a more in-depth discussion of the potential implications and real-world applications of these findings. While the prompt-based defense strategies are an interesting first step, the paper does not explore how these techniques could be scaled or incorporated into the development of more robust LLMs.
Additionally, the paper does not address the broader ethical considerations around the use of such prompt-based attacks, particularly in regards to the potential for misuse or unintended consequences. As language models become more powerful and widely adopted, these are important issues that warrant further exploration.
Overall, this paper makes a valuable contribution to the ongoing research on the limitations and vulnerabilities of large language models. By highlighting the white bear phenomenon, it underscores the need for continued vigilance and a critical, multifaceted approach to the development of AI systems that aspire to human-level intelligence.
Conclusion
This research paper sheds light on a surprising vulnerability shared by recent large language models (LLMs) and human intelligence - the "white bear phenomenon." By analyzing the internal representations of models like Stable Diffusion and DALL-E3, the researchers were able to uncover this quirk and develop a simple prompt-based attack method to exploit it.
To counter these attacks, the researchers introduced defense strategies inspired by cognitive therapy techniques, successfully mitigating the attacks by up to 48.22%. These findings highlight the importance of carefully studying the limitations and biases of language models, even as they continue to advance towards human-level capabilities.
As we work towards developing more robust and reliable AI systems, it will be crucial to address these fundamental vulnerabilities, while also considering the broader ethical implications of these technologies. This paper provides a valuable stepping stone in that direction, underscoring the need for a nuanced and multidisciplinary approach to the future of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
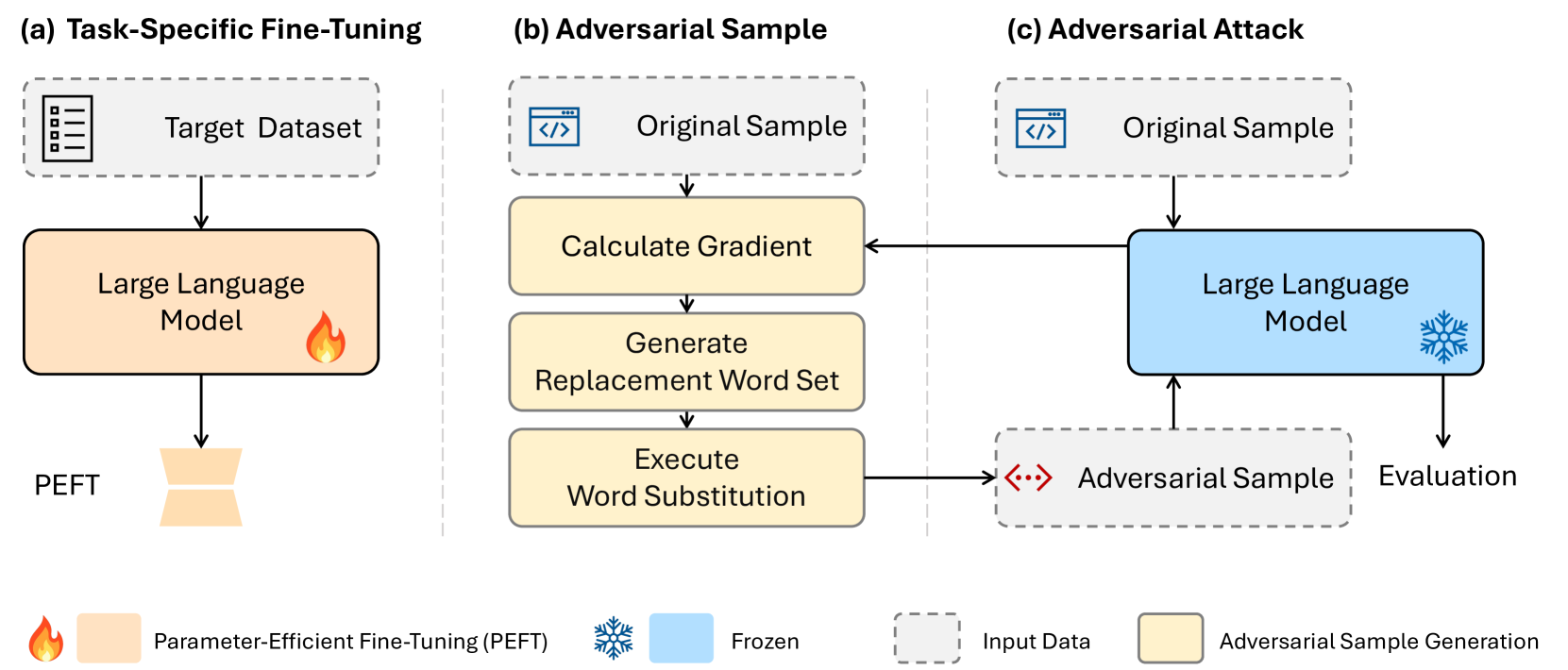
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
Zeyu Yang, Zhao Meng, Xiaochen Zheng, Roger Wattenhofer
0
0
Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
5/7/2024
💬
Modeling Emotions and Ethics with Large Language Models
Edward Y. Chang
0
0
This paper explores the integration of human-like emotions and ethical considerations into Large Language Models (LLMs). We first model eight fundamental human emotions, presented as opposing pairs, and employ collaborative LLMs to reinterpret and express these emotions across a spectrum of intensity. Our focus extends to embedding a latent ethical dimension within LLMs, guided by a novel self-supervised learning algorithm with human feedback (SSHF). This approach enables LLMs to perform self-evaluations and adjustments concerning ethical guidelines, enhancing their capability to generate content that is not only emotionally resonant but also ethically aligned. The methodologies and case studies presented herein illustrate the potential of LLMs to transcend mere text and image generation, venturing into the realms of empathetic interaction and principled decision-making, thereby setting a new precedent in the development of emotionally aware and ethically conscious AI systems.
4/23/2024
💬
New!Integrating Emotional and Linguistic Models for Ethical Compliance in Large Language Models
Edward Y. Chang
0
0
This research develops advanced methodologies for Large Language Models (LLMs) to better manage linguistic behaviors related to emotions and ethics. We introduce DIKE, an adversarial framework that enhances the LLMs' ability to internalize and reflect global human values, adapting to varied cultural contexts to promote transparency and trust among users. The methodology involves detailed modeling of emotions, classification of linguistic behaviors, and implementation of ethical guardrails. Our innovative approaches include mapping emotions and behaviors using self-supervised learning techniques, refining these guardrails through adversarial reviews, and systematically adjusting outputs to ensure ethical alignment. This framework establishes a robust foundation for AI systems to operate with ethical integrity and cultural sensitivity, paving the way for more responsible and context-aware AI interactions.
5/15/2024
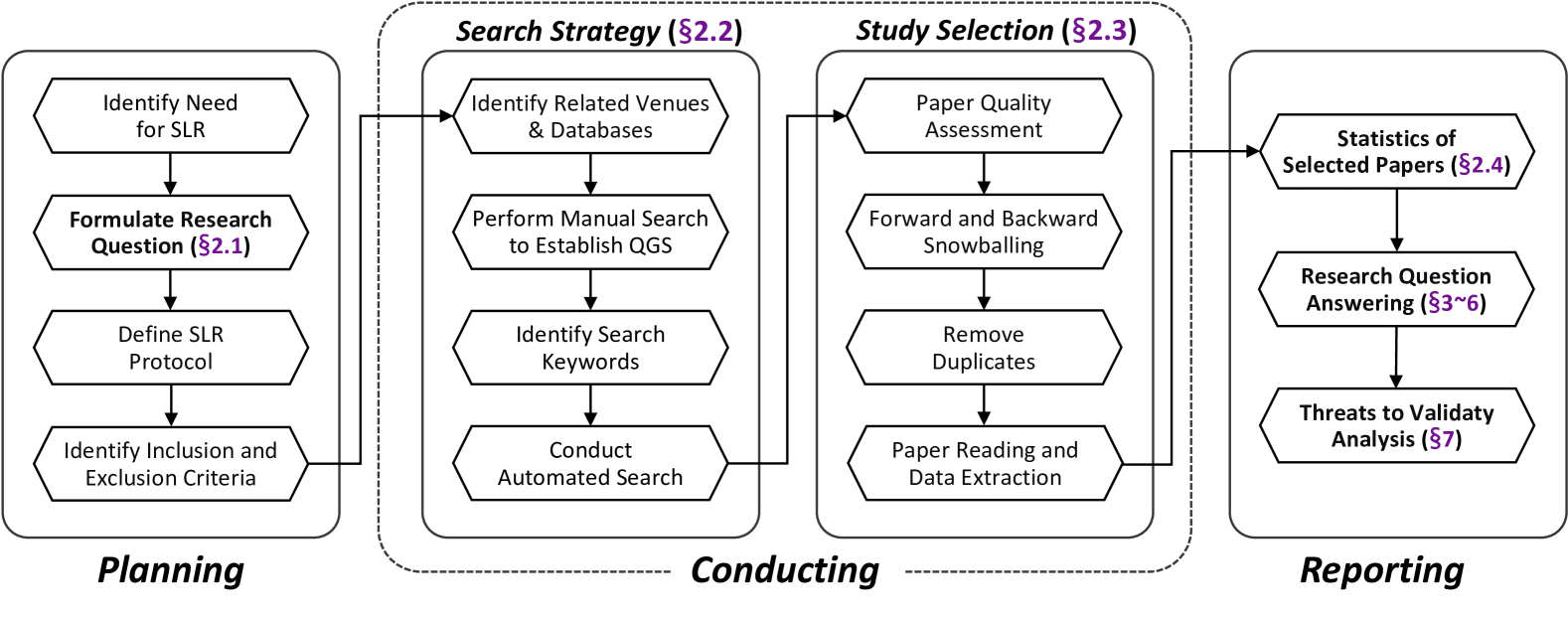
Large Language Models for Cyber Security: A Systematic Literature Review
HanXiang Xu, ShenAo Wang, NingKe Li, KaiLong Wang, YanJie Zhao, Kai Chen, Ting Yu, Yang Liu, HaoYu Wang
0
0
The rapid advancement of Large Language Models (LLMs) has opened up new opportunities for leveraging artificial intelligence in various domains, including cybersecurity. As the volume and sophistication of cyber threats continue to grow, there is an increasing need for intelligent systems that can automatically detect vulnerabilities, analyze malware, and respond to attacks. In this survey, we conduct a comprehensive review of the literature on the application of LLMs in cybersecurity (LLM4Security). By comprehensively collecting over 30K relevant papers and systematically analyzing 127 papers from top security and software engineering venues, we aim to provide a holistic view of how LLMs are being used to solve diverse problems across the cybersecurity domain. Through our analysis, we identify several key findings. First, we observe that LLMs are being applied to a wide range of cybersecurity tasks, including vulnerability detection, malware analysis, network intrusion detection, and phishing detection. Second, we find that the datasets used for training and evaluating LLMs in these tasks are often limited in size and diversity, highlighting the need for more comprehensive and representative datasets. Third, we identify several promising techniques for adapting LLMs to specific cybersecurity domains, such as fine-tuning, transfer learning, and domain-specific pre-training. Finally, we discuss the main challenges and opportunities for future research in LLM4Security, including the need for more interpretable and explainable models, the importance of addressing data privacy and security concerns, and the potential for leveraging LLMs for proactive defense and threat hunting. Overall, our survey provides a comprehensive overview of the current state-of-the-art in LLM4Security and identifies several promising directions for future research.
5/10/2024