Do Physicians Know How to Prompt? The Need for Automatic Prompt Optimization Help in Clinical Note Generation

0
🛠️
Sign in to get full access
Overview
- This study examines how prompt engineering affects the performance of Large Language Models (LLMs) in generating clinical notes.
- The researchers introduce an Automatic Prompt Optimization (APO) framework to refine initial prompts.
- They compare the outputs of medical experts, non-medical experts, and APO-enhanced GPT3.5 and GPT4.
Plain English Explanation
The researchers wanted to see how prompt engineering could improve the quality of clinical notes generated by large language models (LLMs) like GPT-3.5 and GPT-4. They developed a system called Automatic Prompt Optimization (APO) to automatically refine the initial prompts given to the LLMs.
The study compared notes generated by medical experts, non-medical experts, and the APO-enhanced LLMs. The results showed that the GPT-4 model with APO performed the best at creating consistent, high-quality clinical notes across different sections.
The researchers also had a "human-in-the-loop" approach, where experts were able to review and modify the notes generated by the APO-enhanced LLMs. The experts preferred their own customized versions, suggesting that a combination of automated prompting and expert input is valuable for getting the best results.
The researchers recommend a two-step process: first using the APO-GPT4 system to ensure consistency, then having experts review and personalize the notes.
Technical Explanation
The researchers introduced an Automatic Prompt Optimization (APO) framework to refine initial prompts given to LLMs for generating clinical notes. They compared the outputs of medical experts, non-medical experts, and the APO-enhanced versions of GPT-3.5 and GPT-4.
The results showed that the GPT-4 model with APO had superior performance in standardizing the quality of prompts across different sections of the clinical notes. A "human-in-the-loop" approach revealed that experts were able to maintain content quality after APO optimization, and preferred their own customized versions, suggesting the value of expert personalization.
The researchers recommend a two-phase optimization process: first using the APO-GPT4 system to ensure consistency, then incorporating expert input to further personalize the notes.
Critical Analysis
The study highlights the potential benefits of combining automated prompt optimization with expert human feedback. The researchers acknowledge that their approach relies on having access to medical experts, which may not always be feasible in real-world clinical settings.
Additionally, the study focused on a relatively narrow task of generating clinical notes. Further research would be needed to evaluate the generalizability of the APO framework to other types of content generation or downstream applications.
The paper could have provided more details on the specific metrics used to evaluate note quality, as well as the extent of the performance improvement observed between the different approaches. This additional context would help readers better assess the significance of the findings.
Conclusion
This study demonstrates the value of prompt engineering in enhancing the performance of LLMs for clinical note generation. The researchers' Automatic Prompt Optimization (APO) framework, combined with expert human feedback, shows promise in producing high-quality, consistent notes. This approach could potentially be applied to other content generation tasks, though further research is needed to fully understand its broader applicability and limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Do Physicians Know How to Prompt? The Need for Automatic Prompt Optimization Help in Clinical Note Generation
Zonghai Yao, Ahmed Jaafar, Beining Wang, Zhichao Yang, Hong Yu
This study examines the effect of prompt engineering on the performance of Large Language Models (LLMs) in clinical note generation. We introduce an Automatic Prompt Optimization (APO) framework to refine initial prompts and compare the outputs of medical experts, non-medical experts, and APO-enhanced GPT3.5 and GPT4. Results highlight GPT4 APO's superior performance in standardizing prompt quality across clinical note sections. A human-in-the-loop approach shows that experts maintain content quality post-APO, with a preference for their own modifications, suggesting the value of expert customization. We recommend a two-phase optimization process, leveraging APO-GPT4 for consistency and expert input for personalization.
Read more7/8/2024
💬
0
Autonomous Prompt Engineering in Large Language Models
Daan Kepel, Konstantina Valogianni
Prompt engineering is a crucial yet challenging task for optimizing the performance of large language models (LLMs) on customized tasks. This pioneering research introduces the Automatic Prompt Engineering Toolbox (APET), which enables GPT-4 to autonomously apply prompt engineering techniques. By leveraging sophisticated strategies such as Expert Prompting, Chain of Thought, and Tree of Thoughts, APET empowers GPT-4 to dynamically optimize prompts, resulting in substantial improvements in tasks like Word Sorting (4.4% increase) and Geometric Shapes (6.8% increase). Despite encountering challenges in complex tasks such as Checkmate in One (-14.8%), these findings demonstrate the transformative potential of APET in automating complex prompt optimization processes without the use of external data. Overall, this research represents a significant leap in AI development, presenting a robust framework for future innovations in autonomous AI systems and highlighting the ability of GPT-4 to bring prompt engineering theory to practice. It establishes a foundation for enhancing performance in complex task performance and broadening the practical applications of these techniques in real-world scenarios.
Read more7/17/2024
0
Prompt Optimization with Human Feedback
Xiaoqiang Lin, Zhongxiang Dai, Arun Verma, See-Kiong Ng, Patrick Jaillet, Bryan Kian Hsiang Low
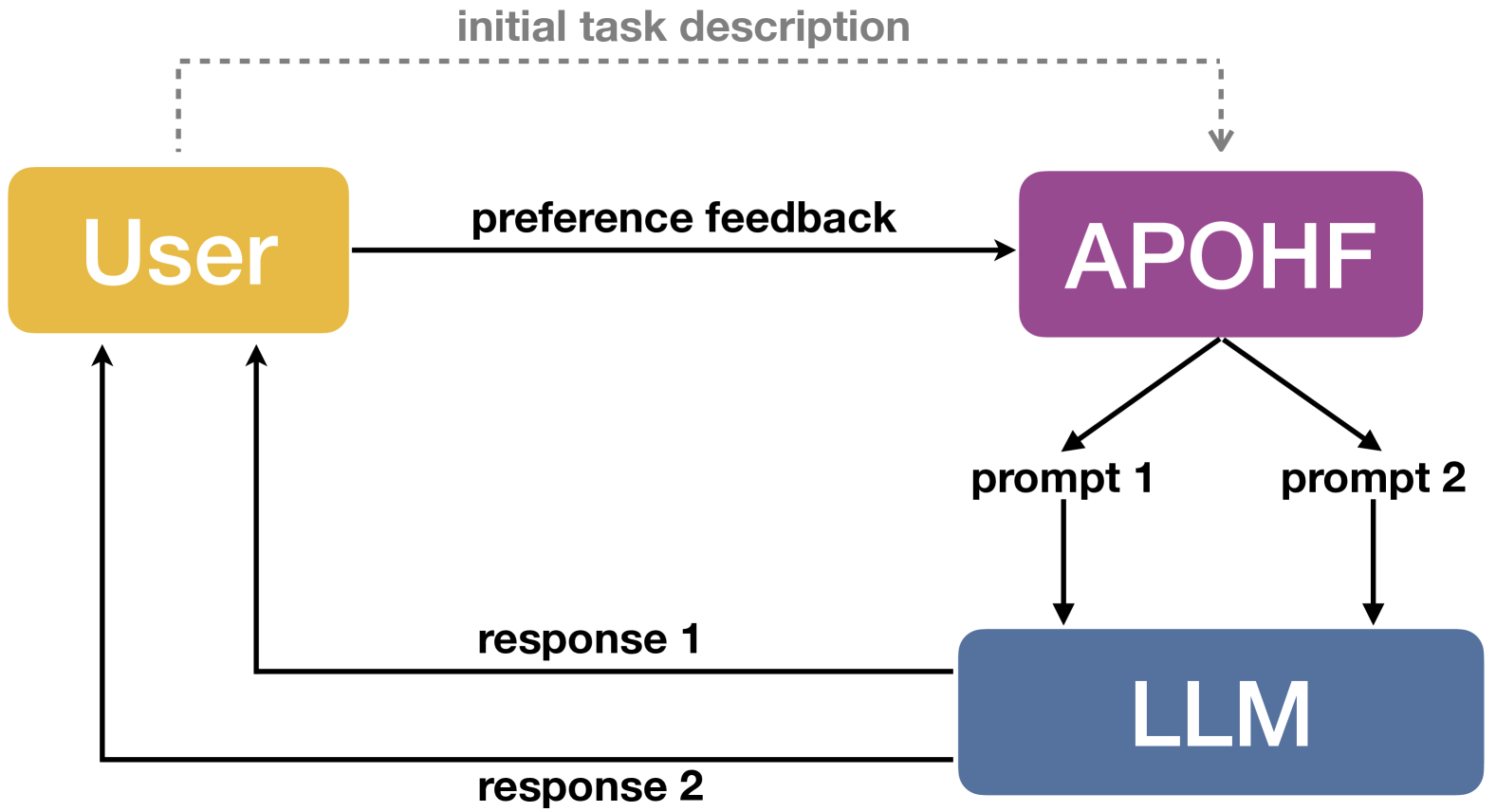
Large language models (LLMs) have demonstrated remarkable performances in various tasks. However, the performance of LLMs heavily depends on the input prompt, which has given rise to a number of recent works on prompt optimization. However, previous works often require the availability of a numeric score to assess the quality of every prompt. Unfortunately, when a human user interacts with a black-box LLM, attaining such a score is often infeasible and unreliable. Instead, it is usually significantly easier and more reliable to obtain preference feedback from a human user, i.e., showing the user the responses generated from a pair of prompts and asking the user which one is preferred. Therefore, in this paper, we study the problem of prompt optimization with human feedback (POHF), in which we aim to optimize the prompt for a black-box LLM using only human preference feedback. Drawing inspiration from dueling bandits, we design a theoretically principled strategy to select a pair of prompts to query for preference feedback in every iteration, and hence introduce our algorithm named automated POHF (APOHF). We apply our APOHF algorithm to various tasks, including optimizing user instructions, prompt optimization for text-to-image generative models, and response optimization with human feedback (i.e., further refining the response using a variant of our APOHF). The results demonstrate that our APOHF can efficiently find a good prompt using a small number of preference feedback instances. Our code can be found at url{https://github.com/xqlin98/APOHF}.
Read more5/28/2024
0
Automatic Prompt Selection for Large Language Models
Viet-Tung Do, Van-Khanh Hoang, Duy-Hung Nguyen, Shahab Sabahi, Jeff Yang, Hajime Hotta, Minh-Tien Nguyen, Hung Le
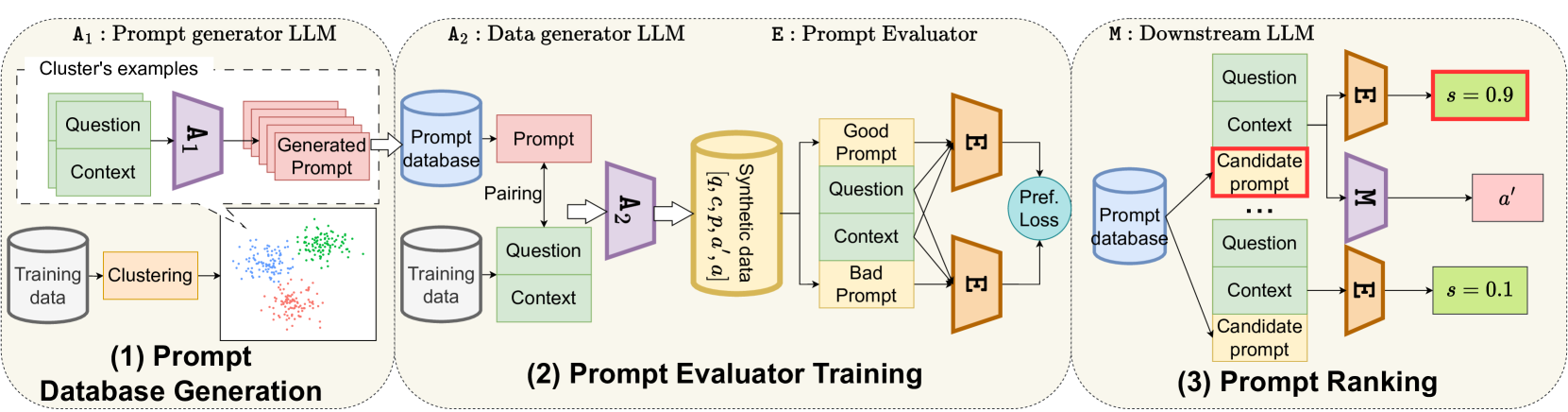
Large Language Models (LLMs) can perform various natural language processing tasks with suitable instruction prompts. However, designing effective prompts manually is challenging and time-consuming. Existing methods for automatic prompt optimization either lack flexibility or efficiency. In this paper, we propose an effective approach to automatically select the optimal prompt for a given input from a finite set of synthetic candidate prompts. Our approach consists of three steps: (1) clustering the training data and generating candidate prompts for each cluster using an LLM-based prompt generator; (2) synthesizing a dataset of input-prompt-output tuples for training a prompt evaluator to rank the prompts based on their relevance to the input; (3) using the prompt evaluator to select the best prompt for a new input at test time. Our approach balances prompt generality-specificity and eliminates the need for resource-intensive training and inference. It demonstrates competitive performance on zero-shot question-answering datasets: GSM8K, MultiArith, and AQuA.
Read more4/4/2024