FIPO: Free-form Instruction-oriented Prompt Optimization with Preference Dataset and Modular Fine-tuning Schema
2402.11811
0
0

Abstract
When the quality of naive prompts is carefully optimized by human experts, the task performance of large language models (LLMs) can be significantly improved. However, expert-based prompt optimizations are expensive. Herein, some works have proposed Automatic Prompt Optimization (APO), to optimize naive prompts according to task outputs of given in-box testing models, with the help of advanced LLMs (e.g., GPT-4) in an ad-hoc way. Although effective, existing schemes suffer from poor generalization ability and privacy risk. To this end, we collect the first large-scale Prompt Optimization Preference dataset (POP), fine-tune offline local LLM-based optimizers, then fairly test with various downstream models. Our method allows accurate optimization of the core task instruction part within the naive prompt in a model-agnostic manner, and thus is named Free-from Instruction-oriented Prompt Optimization (FIPO). In specific, FIPO uses a modular APO template that dynamically integrate the naive task instruction, optional instruction responses, and optional ground truth to produce finely optimized prompts. The POP dataset is meticulously constructed using advanced LLMs, undergoing rigorous cross-validation by human experts and analytical models. Leveraging insights from the data with Tulu2 models and diverse fine-tuning strategies, we validate the efficacy of FIPO framework across five public benchmarks and three testing models. Check codes and data here: https://github.com/LuJunru/FIPO_Project.
Create account to get full access
Overview
- The paper introduces a new approach called FIPO (Free-form Instruction-oriented Prompt Optimization) for optimizing language model prompts to improve performance on a wide range of tasks.
- FIPO uses a preference dataset to fine-tune the language model, where humans provide feedback on the quality of generated prompts.
- The paper also proposes a modular fine-tuning schema that allows for more efficient training and adaptation to different tasks.
Plain English Explanation
The researchers have developed a new way to improve the performance of large language models, like those used in chatbots and AI assistants. They call their approach FIPO, which stands for "Free-form Instruction-oriented Prompt Optimization".
The key idea is to create a "preference dataset" where humans provide feedback on the quality of the prompts (or instructions) used to guide the language model. The model can then be fine-tuned using this feedback, allowing it to generate better prompts that lead to more useful responses.
The researchers also introduce a "modular fine-tuning schema", which means they break down the fine-tuning process into smaller, more efficient steps. This allows the model to be adapted more quickly to different tasks and applications.
By combining the preference dataset and modular fine-tuning, the FIPO approach aims to create language models that can better understand and respond to open-ended instructions and queries, potentially making AI systems more versatile and user-friendly.
Technical Explanation
The paper introduces a new approach called FIPO: Free-form Instruction-oriented Prompt Optimization with Preference Dataset and Modular Fine-tuning Schema. FIPO uses a preference dataset, where humans provide feedback on the quality of generated prompts, to fine-tune large language models and improve their performance on a wide range of tasks.
The researchers also propose a modular fine-tuning schema that allows for more efficient training and adaptation to different tasks. This involves breaking down the fine-tuning process into smaller, more targeted steps, enabling the model to be updated more quickly.
The paper builds on prior work on prompt optimization and unsupervised prompt learning, as well as instruction-aware prompt tuning for large language models.
Critical Analysis
The paper presents a promising approach for improving the performance of language models on a wide range of tasks, but there are a few potential limitations and areas for further research:
- The effectiveness of the preference dataset and modular fine-tuning schema may depend on the specific tasks and the quality of the human feedback, which could be challenging to obtain at scale.
- The researchers do not provide a thorough analysis of the computational efficiency and scalability of their approach, which could be an important consideration for real-world deployment.
- It would be valuable to see more extensive testing of FIPO on diverse benchmarks and use cases to fully understand its strengths and weaknesses compared to other prompt optimization techniques.
Overall, the paper makes a valuable contribution to the field of language model optimization and highlights the potential of leveraging human feedback to improve AI systems.
Conclusion
The FIPO approach presented in this paper offers a novel way to optimize language model prompts and improve performance on a wide range of tasks. By incorporating a preference dataset and a modular fine-tuning schema, the researchers have developed a promising technique for creating more versatile and user-friendly AI systems.
While the paper raises some questions about the practical implementation and scalability of the approach, it represents an important step forward in the ongoing effort to make language models more responsive to open-ended instructions and queries. As the field of AI continues to evolve, techniques like FIPO may play a crucial role in enhancing the capabilities and user experience of AI-powered applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
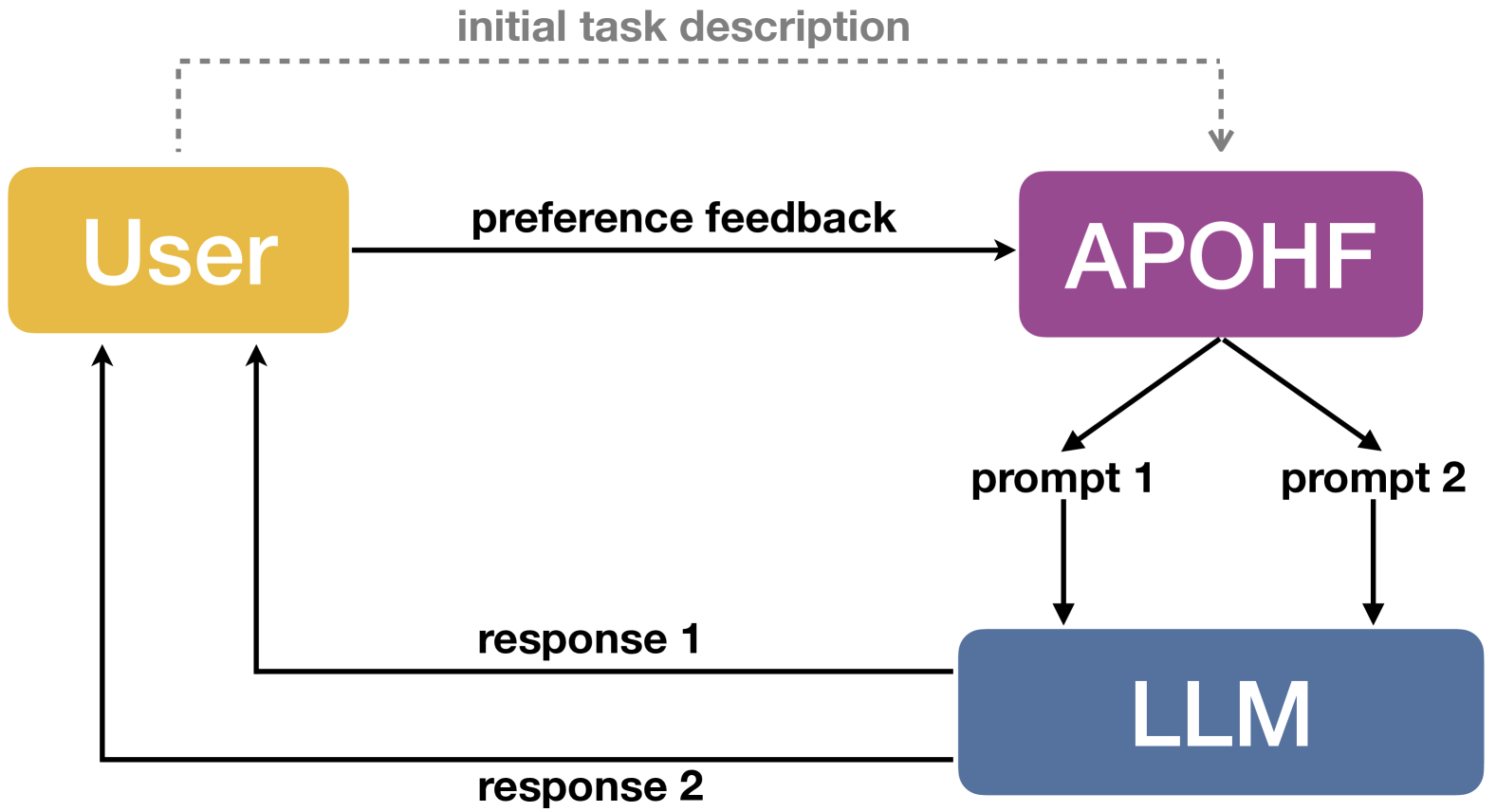
Prompt Optimization with Human Feedback
Xiaoqiang Lin, Zhongxiang Dai, Arun Verma, See-Kiong Ng, Patrick Jaillet, Bryan Kian Hsiang Low
0
0
Large language models (LLMs) have demonstrated remarkable performances in various tasks. However, the performance of LLMs heavily depends on the input prompt, which has given rise to a number of recent works on prompt optimization. However, previous works often require the availability of a numeric score to assess the quality of every prompt. Unfortunately, when a human user interacts with a black-box LLM, attaining such a score is often infeasible and unreliable. Instead, it is usually significantly easier and more reliable to obtain preference feedback from a human user, i.e., showing the user the responses generated from a pair of prompts and asking the user which one is preferred. Therefore, in this paper, we study the problem of prompt optimization with human feedback (POHF), in which we aim to optimize the prompt for a black-box LLM using only human preference feedback. Drawing inspiration from dueling bandits, we design a theoretically principled strategy to select a pair of prompts to query for preference feedback in every iteration, and hence introduce our algorithm named automated POHF (APOHF). We apply our APOHF algorithm to various tasks, including optimizing user instructions, prompt optimization for text-to-image generative models, and response optimization with human feedback (i.e., further refining the response using a variant of our APOHF). The results demonstrate that our APOHF can efficiently find a good prompt using a small number of preference feedback instances. Our code can be found at url{https://github.com/xqlin98/APOHF}.
5/28/2024
💬
Black-Box Prompt Optimization: Aligning Large Language Models without Model Training
Jiale Cheng, Xiao Liu, Kehan Zheng, Pei Ke, Hongning Wang, Yuxiao Dong, Jie Tang, Minlie Huang
0
0
Large language models (LLMs) have shown impressive success in various applications. However, these models are often not well aligned with human intents, which calls for additional treatments on them; that is, the alignment problem. To make LLMs better follow user instructions, existing alignment methods primarily focus on further training them. However, the extra training of LLMs is usually expensive in terms of GPU computing; even worse, some LLMs are not accessible for user-demanded training, such as GPTs. In this work, we take a different perspective -- Black-Box Prompt Optimization (BPO) -- to perform alignments. The idea is to optimize user prompts to suit LLMs' input understanding, so as to best realize users' intents without updating LLMs' parameters. BPO leverages human preferences to optimize prompts, thus making it superior to LLM (e.g., ChatGPT) as a prompt engineer. Moreover, BPO is model-agnostic, and the empirical results demonstrate that the BPO-aligned ChatGPT yields a 22% increase in the win rate against its original version and 10% for GPT-4. Notably, the BPO-aligned LLMs can outperform the same models aligned by PPO and DPO, and it also brings additional performance gains when combining BPO with PPO or DPO. Code and datasets are released at https://github.com/thu-coai/BPO.
6/24/2024
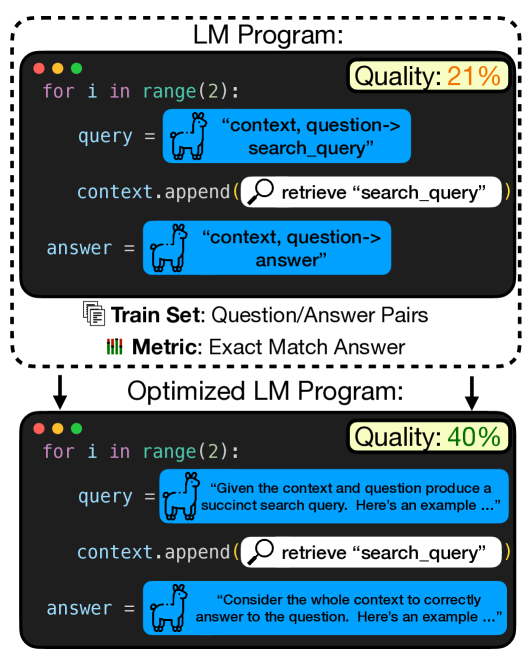
Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs
Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, Omar Khattab
0
0
Language Model Programs, i.e. sophisticated pipelines of modular language model (LM) calls, are increasingly advancing NLP tasks, but they require crafting prompts that are jointly effective for all modules. We study prompt optimization for LM programs, i.e. how to update these prompts to maximize a downstream metric without access to module-level labels or gradients. To make this tractable, we factorize our problem into optimizing the free-form instructions and few-shot demonstrations of every module and introduce several strategies to craft task-grounded instructions and navigate credit assignment across modules. Our strategies include (i) program- and data-aware techniques for proposing effective instructions, (ii) a stochastic mini-batch evaluation function for learning a surrogate model of our objective, and (iii) a meta-optimization procedure in which we refine how LMs construct proposals over time. Using these insights we develop MIPRO, a novel optimizer that outperforms baselines on five of six diverse LM programs using a best-in-class open-source model (Llama-3-8B), by as high as 12.9% accuracy. We will release our new optimizers and benchmark in DSPy at https://github.com/stanfordnlp/dspy
6/18/2024
🛠️
Teach Better or Show Smarter? On Instructions and Exemplars in Automatic Prompt Optimization
Xingchen Wan, Ruoxi Sun, Hootan Nakhost, Sercan O. Arik
0
0
Large language models have demonstrated remarkable capabilities, but their performance is heavily reliant on effective prompt engineering. Automatic prompt optimization (APO) methods are designed to automate this and can be broadly categorized into those targeting instructions (instruction optimization, IO) vs. those targeting exemplars (exemplar selection, ES). Despite their shared objective, these have evolved rather independently, with IO recently receiving more research attention. This paper seeks to bridge this gap by comprehensively comparing the performance of representative IO and ES techniques, both isolation and combination, on a diverse set of challenging tasks. Our findings reveal that intelligently reusing model-generated input-output pairs obtained from evaluating prompts on the validation set as exemplars consistently improves performance over IO methods but is currently under-investigated. We also find that despite the recent focus on IO, how we select exemplars can outweigh how we optimize instructions, with ES strategies as simple as random search outperforming state-of-the-art IO methods with seed instructions without any optimization. Moreover, we observe synergy between ES and IO, with optimal combinations surpassing individual contributions. We conclude that studying exemplar selection as a standalone method and its optimal combination with instruction optimization remains a crucial aspect of APO and deserves greater consideration in future research, even in the era of highly capable instruction-following models.
6/26/2024