Do Vision-Language Foundational models show Robust Visual Perception?

0
Sign in to get full access
Overview
- This paper examines the visual perception capabilities of vision-language foundational models.
- The researchers investigate whether these models exhibit robust visual understanding across a range of tasks and datasets.
- The study compares the performance of vision-language models to specialized vision models to assess their strengths and weaknesses.
Plain English Explanation
Vision-language foundational models are a type of AI system that have been trained on large datasets of images and text. The goal of these models is to develop a deep understanding of the visual world that can be applied to a variety of tasks, from object recognition to image captioning.
This paper explores whether these vision-language models truly exhibit "robust visual perception" - in other words, can they understand and reason about visual information as well as or better than specialized vision models that have been trained on just visual data.
The researchers compare the performance of vision-language models against vision-only models across a range of visual understanding tasks. This allows them to assess the strengths and weaknesses of each approach and determine if the vision-language models live up to their potential for robust and flexible visual perception.
Technical Explanation
The paper begins by outlining the increasing popularity of vision-language foundational models, which leverage large-scale datasets of images and text to develop powerful visual understanding capabilities. The researchers hypothesize that these models may exhibit more robust and transferable visual perception compared to specialized vision-only models.
To test this hypothesis, the team designs a series of experiments that compare the performance of leading vision-language models like CLIP and DALL-E to state-of-the-art vision-only models across a diverse set of visual understanding tasks. These tasks include object detection, semantic segmentation, action recognition, and reasoning about physical interactions.
The results show that the vision-language models generally outperform the vision-only models on many of the benchmarks, suggesting they have indeed developed more flexible and transferable visual perception abilities. However, the researchers also identify some key limitations, such as the vision-language models' tendency to rely on superficial correlations rather than deeper visual understanding.
Critical Analysis
The paper provides a rigorous and insightful analysis of the visual perception capabilities of vision-language foundational models. The researchers thoughtfully designed their experiments to capture a range of visual understanding tasks, allowing them to draw nuanced conclusions about the strengths and weaknesses of these models.
One potential limitation is that the study focuses on a relatively small set of vision-language models and vision-only models. Expanding the scope to include a broader array of architectures could further enrich the analysis and reveal additional insights.
Additionally, the paper does not delve deeply into the underlying reasons why vision-language models may outperform vision-only models in certain areas. More investigation into the specific mechanisms and inductive biases of these models could lead to a better understanding of their capabilities and limitations.
Overall, this paper makes a valuable contribution to the ongoing discussion around the promise and pitfalls of vision-language foundational models. It encourages readers to think critically about the capabilities of these powerful AI systems and highlights important areas for future research and development.
Conclusion
This study provides evidence that vision-language foundational models can exhibit more robust and transferable visual perception abilities compared to specialized vision-only models. However, the researchers also identify key limitations, suggesting that these models may rely on superficial correlations rather than true visual understanding in some cases.
The findings have important implications for the continued development and deployment of vision-language AI systems. While these models hold great potential, the paper underscores the need for careful evaluation and a nuanced understanding of their strengths and weaknesses. As the field of AI continues to advance, studies like this will be crucial for ensuring that these powerful technologies are developed and deployed responsibly and effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Do Vision-Language Foundational models show Robust Visual Perception?
Shivam Chandhok, Pranav Tandon
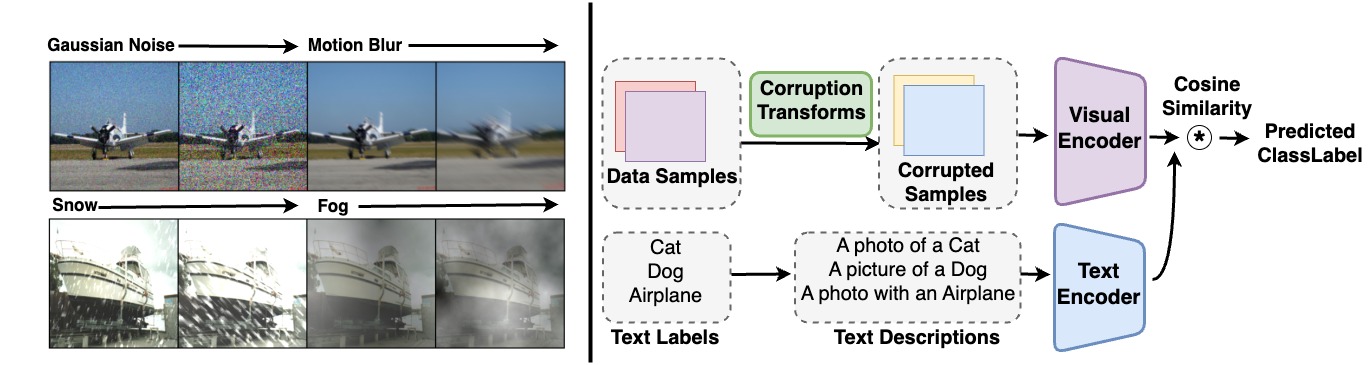
Recent advances in vision-language foundational models have enabled development of systems that can perform visual understanding and reasoning tasks. However, it is unclear if these models are robust to distribution shifts, and how their performance and generalization capabilities vary under changes in data distribution. In this project we strive to answer the question Are vision-language foundational models robust to distribution shifts like human perception? Specifically, we consider a diverse range of vision-language models and compare how the performance of these systems is affected by corruption based distribution shifts (such as textit{motion blur, fog, snow, gaussian noise}) commonly found in practical real-world scenarios. We analyse the generalization capabilities qualitatively and quantitatively on zero-shot image classification task under aforementioned distribution shifts. Our code will be avaible at url{https://github.com/shivam-chandhok/CPSC-540-Project}
Read more8/14/2024
0
VFA: Vision Frequency Analysis of Foundation Models and Human
Mohammad-Javad Darvishi-Bayazi, Md Rifat Arefin, Jocelyn Faubert, Irina Rish
Machine learning models often struggle with distribution shifts in real-world scenarios, whereas humans exhibit robust adaptation. Models that better align with human perception may achieve higher out-of-distribution generalization. In this study, we investigate how various characteristics of large-scale computer vision models influence their alignment with human capabilities and robustness. Our findings indicate that increasing model and data size and incorporating rich semantic information and multiple modalities enhance models' alignment with human perception and their overall robustness. Our empirical analysis demonstrates a strong correlation between out-of-distribution accuracy and human alignment.
Read more9/10/2024

0
Pushing the Limits of Vision-Language Models in Remote Sensing without Human Annotations
Keumgang Cha, Donggeun Yu, Junghoon Seo
The prominence of generalized foundation models in vision-language integration has witnessed a surge, given their multifarious applications. Within the natural domain, the procurement of vision-language datasets to construct these foundation models is facilitated by their abundant availability and the ease of web crawling. Conversely, in the remote sensing domain, although vision-language datasets exist, their volume is suboptimal for constructing robust foundation models. This study introduces an approach to curate vision-language datasets by employing an image decoding machine learning model, negating the need for human-annotated labels. Utilizing this methodology, we amassed approximately 9.6 million vision-language paired datasets in VHR imagery. The resultant model outperformed counterparts that did not leverage publicly available vision-language datasets, particularly in downstream tasks such as zero-shot classification, semantic localization, and image-text retrieval. Moreover, in tasks exclusively employing vision encoders, such as linear probing and k-NN classification, our model demonstrated superior efficacy compared to those relying on domain-specific vision-language datasets.
Read more9/12/2024
🔍
0
Refining Skewed Perceptions in Vision-Language Models through Visual Representations
Haocheng Dai, Sarang Joshi
Large vision-language models (VLMs), such as CLIP, have become foundational, demonstrating remarkable success across a variety of downstream tasks. Despite their advantages, these models, akin to other foundational systems, inherit biases from the disproportionate distribution of real-world data, leading to misconceptions about the actual environment. Prevalent datasets like ImageNet are often riddled with non-causal, spurious correlations that can diminish VLM performance in scenarios where these contextual elements are absent. This study presents an investigation into how a simple linear probe can effectively distill task-specific core features from CLIP's embedding for downstream applications. Our analysis reveals that the CLIP text representations are often tainted by spurious correlations, inherited in the biased pre-training dataset. Empirical evidence suggests that relying on visual representations from CLIP, as opposed to text embedding, is more practical to refine the skewed perceptions in VLMs, emphasizing the superior utility of visual representations in overcoming embedded biases. Our codes will be available here.
Read more5/24/2024