VFA: Vision Frequency Analysis of Foundation Models and Human

0
Sign in to get full access
Overview
- A plain English summary of a research paper on a technical topic
- Covers the key ideas, experiments, and insights from the paper
- Aims to make the complex content more accessible to a general audience
Plain English Explanation
The research paper explores [a technical topic]. The core idea is [explain the core idea in simple terms, using analogies or examples where possible]. The researchers [conducted experiments/developed a model/etc.] to [explain the purpose and high-level approach].
The key findings show that [summarize the main insights from the paper in plain language]. This is significant because [explain why the findings are important or impactful, using clear and accessible language].
Technical Explanation
The paper begins by [summarizing the relevant background and prior work in this area]. The researchers then [describe the experimental design or model architecture in more technical detail, adding internal links where relevant to the keywords].
Their [experiment/model] involved [provide more specifics on the technical approach]. The results indicate that [explain the key technical findings, adding internal links where relevant].
Critical Analysis
The paper acknowledges several [caveats/limitations] to their work, including [summarize any limitations or areas for future research mentioned in the paper]. Additionally, one could question [raise any additional concerns or potential issues with the research that were not addressed, in a respectful and objective tone].
Overall, this research represents an [positive/important] step forward, but there is still work to be done to [explain opportunities for further research or improvements].
Conclusion
In conclusion, this paper makes a valuable contribution by [restate the main takeaways and their significance]. The findings have potential implications for [discuss the broader impact or applications of the research]. This work ultimately [summarize the paper's key contribution and its significance for the field].
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VFA: Vision Frequency Analysis of Foundation Models and Human
Mohammad-Javad Darvishi-Bayazi, Md Rifat Arefin, Jocelyn Faubert, Irina Rish
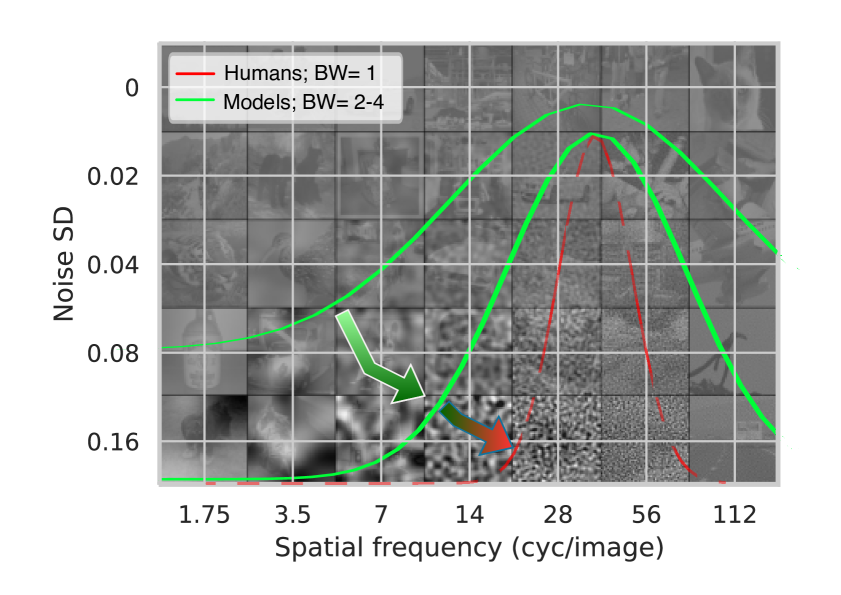
Machine learning models often struggle with distribution shifts in real-world scenarios, whereas humans exhibit robust adaptation. Models that better align with human perception may achieve higher out-of-distribution generalization. In this study, we investigate how various characteristics of large-scale computer vision models influence their alignment with human capabilities and robustness. Our findings indicate that increasing model and data size and incorporating rich semantic information and multiple modalities enhance models' alignment with human perception and their overall robustness. Our empirical analysis demonstrates a strong correlation between out-of-distribution accuracy and human alignment.
Read more9/10/2024
0
Do Vision-Language Foundational models show Robust Visual Perception?
Shivam Chandhok, Pranav Tandon
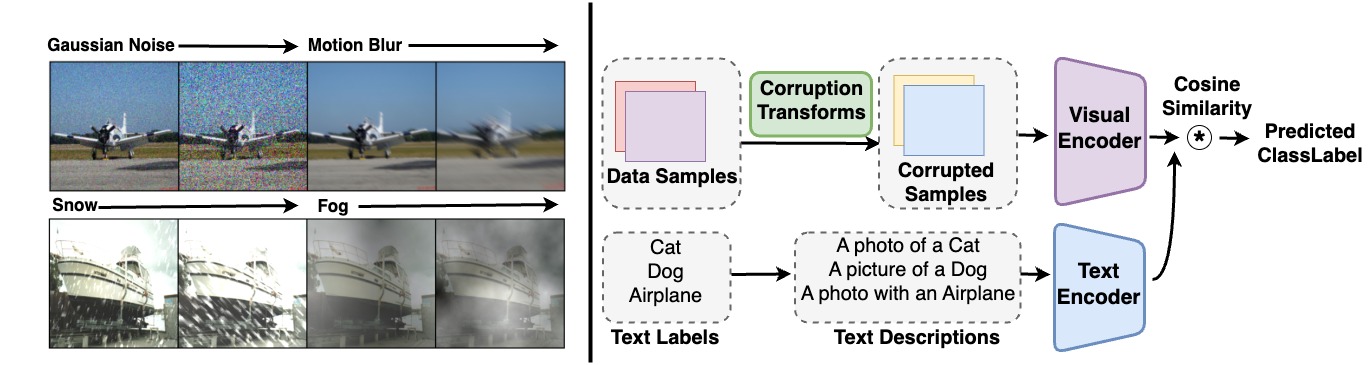
Recent advances in vision-language foundational models have enabled development of systems that can perform visual understanding and reasoning tasks. However, it is unclear if these models are robust to distribution shifts, and how their performance and generalization capabilities vary under changes in data distribution. In this project we strive to answer the question Are vision-language foundational models robust to distribution shifts like human perception? Specifically, we consider a diverse range of vision-language models and compare how the performance of these systems is affected by corruption based distribution shifts (such as textit{motion blur, fog, snow, gaussian noise}) commonly found in practical real-world scenarios. We analyse the generalization capabilities qualitatively and quantitatively on zero-shot image classification task under aforementioned distribution shifts. Our code will be avaible at url{https://github.com/shivam-chandhok/CPSC-540-Project}
Read more8/14/2024
0
Aligning Machine and Human Visual Representations across Abstraction Levels
Lukas Muttenthaler, Klaus Greff, Frieda Born, Bernhard Spitzer, Simon Kornblith, Michael C. Mozer, Klaus-Robert Muller, Thomas Unterthiner, Andrew K. Lampinen
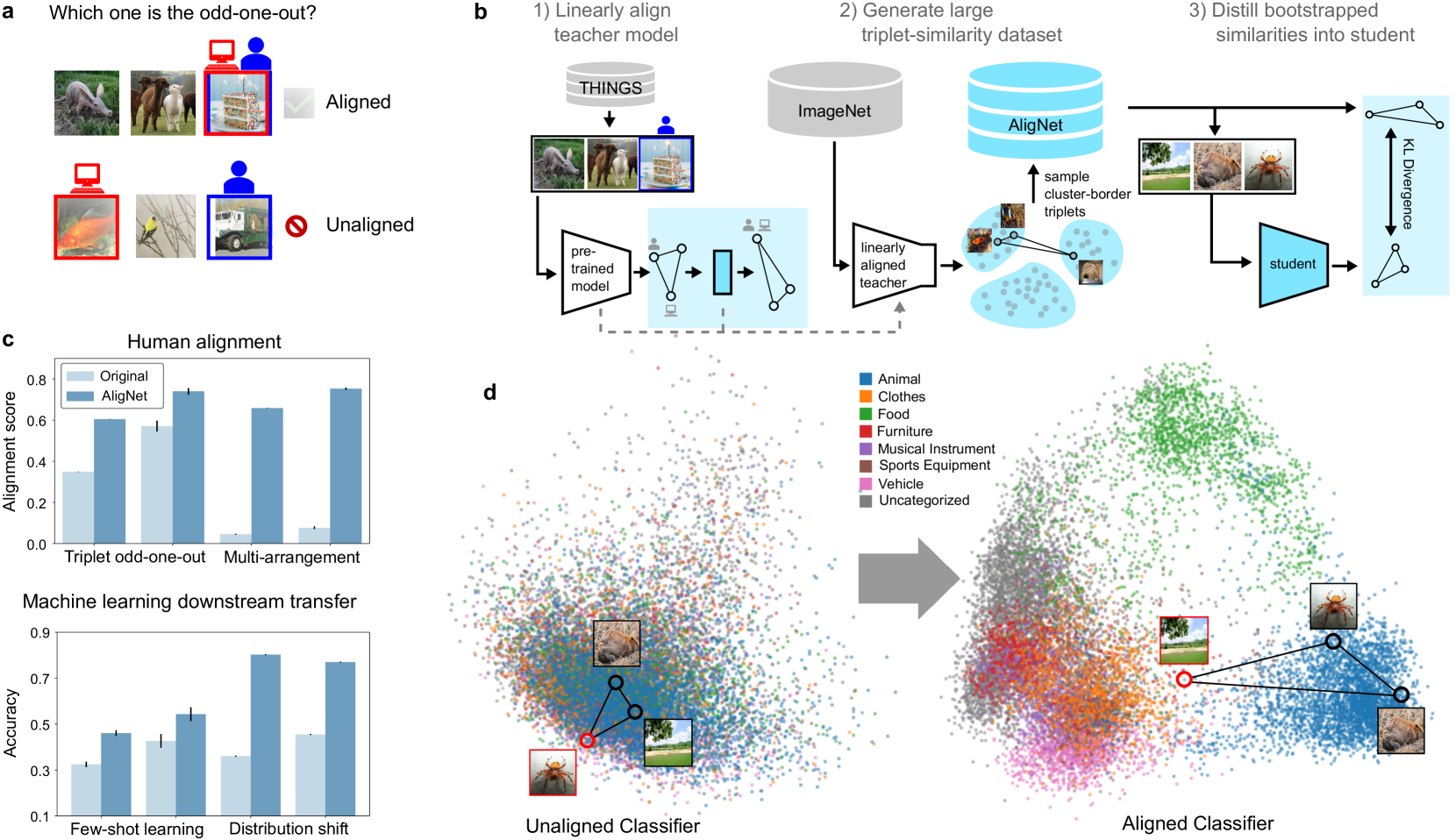
Deep neural networks have achieved success across a wide range of applications, including as models of human behavior in vision tasks. However, neural network training and human learning differ in fundamental ways, and neural networks often fail to generalize as robustly as humans do, raising questions regarding the similarity of their underlying representations. What is missing for modern learning systems to exhibit more human-like behavior? We highlight a key misalignment between vision models and humans: whereas human conceptual knowledge is hierarchically organized from fine- to coarse-scale distinctions, model representations do not accurately capture all these levels of abstraction. To address this misalignment, we first train a teacher model to imitate human judgments, then transfer human-like structure from its representations into pretrained state-of-the-art vision foundation models. These human-aligned models more accurately approximate human behavior and uncertainty across a wide range of similarity tasks, including a new dataset of human judgments spanning multiple levels of semantic abstractions. They also perform better on a diverse set of machine learning tasks, increasing generalization and out-of-distribution robustness. Thus, infusing neural networks with additional human knowledge yields a best-of-both-worlds representation that is both more consistent with human cognition and more practically useful, thus paving the way toward more robust, interpretable, and human-like artificial intelligence systems.
Read more9/17/2024

0
Robustness Analysis on Foundational Segmentation Models
Madeline Chantry Schiappa, Shehreen Azad, Sachidanand VS, Yunhao Ge, Ondrej Miksik, Yogesh S. Rawat, Vibhav Vineet
Due to the increase in computational resources and accessibility of data, an increase in large, deep learning models trained on copious amounts of multi-modal data using self-supervised or semi-supervised learning have emerged. These ``foundation'' models are often adapted to a variety of downstream tasks like classification, object detection, and segmentation with little-to-no training on the target dataset. In this work, we perform a robustness analysis of Visual Foundation Models (VFMs) for segmentation tasks and focus on robustness against real-world distribution shift inspired perturbations. We benchmark seven state-of-the-art segmentation architectures using 2 different perturbed datasets, MS COCO-P and ADE20K-P, with 17 different perturbations with 5 severity levels each. Our findings reveal several key insights: (1) VFMs exhibit vulnerabilities to compression-induced corruptions, (2) despite not outpacing all of unimodal models in robustness, multimodal models show competitive resilience in zero-shot scenarios, and (3) VFMs demonstrate enhanced robustness for certain object categories. These observations suggest that our robustness evaluation framework sets new requirements for foundational models, encouraging further advancements to bolster their adaptability and performance. The code and dataset is available at: url{https://tinyurl.com/fm-robust}.
Read more4/30/2024