DocCGen: Document-based Controlled Code Generation
2406.11925
0
0

Abstract
Recent developments show that Large Language Models (LLMs) produce state-of-the-art performance on natural language (NL) to code generation for resource-rich general-purpose languages like C++, Java, and Python. However, their practical usage for structured domain-specific languages (DSLs) such as YAML, JSON is limited due to domain-specific schema, grammar, and customizations generally unseen by LLMs during pre-training. Efforts have been made to mitigate this challenge via in-context learning through relevant examples or by fine-tuning. However, it suffers from problems, such as limited DSL samples and prompt sensitivity but enterprises maintain good documentation of the DSLs. Therefore, we propose DocCGen, a framework that can leverage such rich knowledge by breaking the NL-to-Code generation task for structured code languages into a two-step process. First, it detects the correct libraries using the library documentation that best matches the NL query. Then, it utilizes schema rules extracted from the documentation of these libraries to constrain the decoding. We evaluate our framework for two complex structured languages, Ansible YAML and Bash command, consisting of two settings: Out-of-domain (OOD) and In-domain (ID). Our extensive experiments show that DocCGen consistently improves different-sized language models across all six evaluation metrics, reducing syntactic and semantic errors in structured code. We plan to open-source the datasets and code to motivate research in constrained code generation.
Create account to get full access
Overview
- This paper introduces DocCGen, a framework for document-based controlled code generation.
- DocCGen aims to enable users to generate code by providing relevant textual information, rather than having to write code directly.
- The framework leverages large language models to translate natural language descriptions into executable code.
Plain English Explanation
The paper describes a system called DocCGen that allows users to generate code by providing natural language descriptions, rather than having to write the code themselves. This could be useful for people who are not experienced programmers, as it removes the need to learn the syntax and structure of a programming language.
DocCGen: Document-based Controlled Code Generation works by using large language models, which are AI systems that have been trained on vast amounts of text data. These models can understand and generate human-like text. DocCGen uses these models to translate the user's natural language descriptions into executable code.
For example, a user might describe in plain English what they want a program to do, and DocCGen would then generate the corresponding code. This could make it easier for non-programmers to create software applications or automate various tasks.
Technical Explanation
DocCGen: Document-based Controlled Code Generation presents a framework that leverages large language models to translate natural language descriptions into executable code. The key idea is to provide users with a way to generate code by specifying their requirements in textual form, rather than having to write the code directly.
The DocCGen framework consists of several components, including a language model for understanding the user's natural language input, a code generation module that translates the input into code, and a mechanism for controlling and refining the generated code. The authors also introduce techniques for guiding the language model to produce code that aligns with the user's intent, such as by providing relevant context or using domain-specific prompts.
The paper presents experiments that demonstrate the effectiveness of the DocCGen approach, showing that it can generate code that meets user requirements while maintaining relevant and consistent code structure. The authors also discuss the potential of integrating DocCGen with other code generation techniques, such as retrieval-augmented generation, to further enhance the system's capabilities.
Critical Analysis
The DocCGen framework represents an interesting approach to addressing the challenge of code generation, which is an active area of research in the field of AI-assisted code generation. By leveraging large language models, the authors aim to provide a more accessible way for users to create code without requiring extensive programming expertise.
One potential limitation of the approach is the reliance on the language model's ability to accurately interpret the user's natural language input and translate it into correct and meaningful code. The paper acknowledges this challenge and discusses techniques for guiding the model, but further research may be needed to ensure the generated code is consistently reliable and aligned with the user's intent.
Additionally, the paper does not address the scalability of the DocCGen framework, particularly in terms of handling complex or domain-specific code generation tasks. Integrating the system with other code generation techniques could be a promising direction to explore, as it may help expand the framework's capabilities and applicability.
Conclusion
The DocCGen framework presents a novel approach to code generation that leverages large language models to translate natural language descriptions into executable code. This could potentially make coding more accessible to a wider range of users, including those without extensive programming experience.
While the paper demonstrates the feasibility of the approach, further research is needed to address the challenges of ensuring the reliability and scalability of the generated code. Integrating DocCGen with other AI-assisted code generation techniques could be a promising direction for future work in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Constraining Large Language Model for Generating Computer-Parsable Content
Jiaye Wang
0
0
We propose a method to guide Large Language Models (LLMs) in generating structured content adhering to specific conventions without fine-tuning. By utilizing coroutine-based content generation constraints through a pre-agreed context-free grammar (CFG), LLMs are directed during decoding to produce formal language compliant outputs. This enhances stability and consistency in generating target data structures, types, or instructions, reducing application development complexities. Experimentally, error rates of GPT-2 and Gemma exceed 95% for DSLs longer than 36 and 282 tokens, respectively. We introduce YieldLang, a coroutine-based DSL generation framework, and evaluate it with LLMs on various tasks including JSON and Mermaid flowchart generation. Compared to benchmarks, our approach improves accuracy by 1.09 to 11.6 times, with LLMs requiring only about 16.5% of the samples to generate JSON effectively. This enhances usability of LLM-generated content for computer programs.
4/23/2024
🛸
Domain-Specific Shorthand for Generation Based on Context-Free Grammar
Andriy Kanyuka, Elias Mahfoud
0
0
The generation of structured data in formats such as JSON, YAML and XML is a critical task in Generative AI (GenAI) applications. These formats, while widely used, contain many redundant constructs that lead to inflated token usage. This inefficiency is particularly evident when employing large language models (LLMs) like GPT-4, where generating extensive structured data incurs increased latency and operational costs. We introduce a domain-specific shorthand (DSS) format, underpinned by a context-free grammar (CFG), and demonstrate its usage to reduce the number of tokens required for structured data generation. The method involves creating a shorthand notation that captures essential elements of the output schema with fewer tokens, ensuring it can be unambiguously converted to and from its verbose form. It employs a CFG to facilitate efficient shorthand generation by the LLM, and to create parsers to translate the shorthand back into standard structured formats. The application of our approach to data visualization with LLMs demonstrates a significant (3x to 5x) reduction in generated tokens, leading to significantly lower latency and cost. This paper outlines the development of the DSS and the accompanying CFG, and the implications of this approach for GenAI applications, presenting a scalable solution to the token inefficiency problem in structured data generation.
6/18/2024
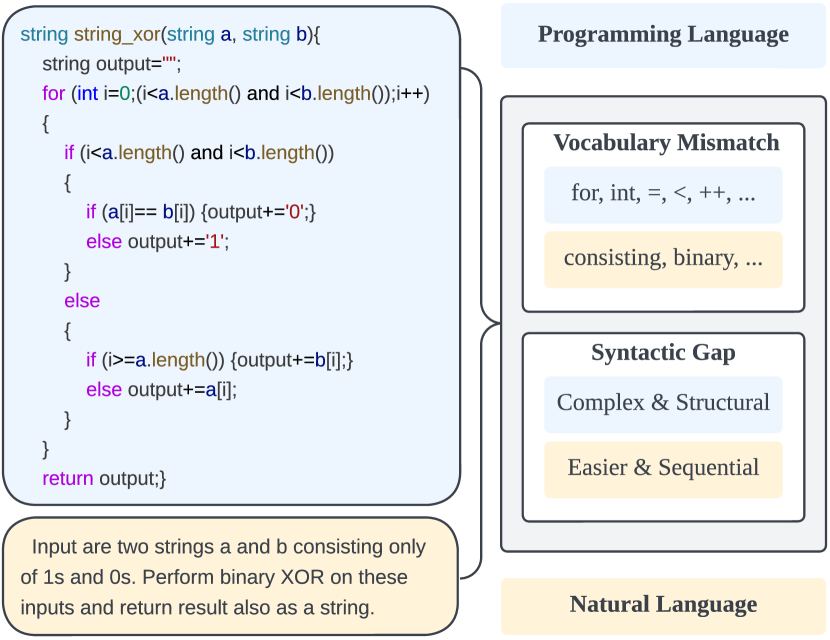
CodeGRAG: Extracting Composed Syntax Graphs for Retrieval Augmented Cross-Lingual Code Generation
Kounianhua Du, Renting Rui, Huacan Chai, Lingyue Fu, Wei Xia, Yasheng Wang, Ruiming Tang, Yong Yu, Weinan Zhang
0
0
Utilizing large language models to generate codes has shown promising meaning in software development revolution. Despite the intelligence shown by the general large language models, their specificity in code generation can still be improved due to the syntactic gap and mismatched vocabulary existing among natural language and different programming languages. In addition, programming languages are inherently logical and complex, making them hard to be correctly generated. Existing methods rely on multiple prompts to the large language model to explore better solutions, which is expensive. In this paper, we propose Syntax Graph Retrieval Augmented Code Generation (CodeGRAG) to enhance the performance of LLMs in single-round code generation tasks. CodeGRAG extracts and summarizes the control flow and data flow of code blocks to fill the gap between programming languages and natural language. The extracted external structural knowledge models the inherent flows of code blocks, which can facilitate LLMs for better understanding of code syntax and serve as a bridge among different programming languages. CodeGRAG significantly improves the code generation ability of LLMs and can even offer performance gain for cross-lingual code generation, e.g., C++ for Python.
5/7/2024

SynCode: LLM Generation with Grammar Augmentation
Shubham Ugare, Tarun Suresh, Hangoo Kang, Sasa Misailovic, Gagandeep Singh
0
0
LLMs are widely used in complex AI applications. These applications underscore the need for LLM outputs to adhere to a specific format, for their integration with other components in the systems. Typically the format rules e.g., for data serialization formats such as JSON, YAML, or Code in Programming Language are expressed as context-free grammar (CFG). Due to the hallucinations and unreliability of LLMs, instructing LLMs to adhere to specified syntax becomes an increasingly important challenge. We present SynCode, a novel framework for efficient and general syntactical decoding with LLMs, to address this challenge. SynCode leverages the CFG of a formal language, utilizing an offline-constructed efficient lookup table called DFA mask store based on the discrete finite automaton (DFA) of the language grammar terminals. We demonstrate SynCode's soundness and completeness given the CFG of the formal language, presenting its ability to retain syntactically valid tokens while rejecting invalid ones. SynCode seamlessly integrates with any language defined by CFG, as evidenced by experiments focusing on generating JSON, Python, and Go outputs. Our experiments evaluating the effectiveness of SynCode for JSON generation demonstrate that SynCode eliminates all syntax errors and significantly outperforms state-of-the-art baselines. Furthermore, our results underscore how SynCode significantly reduces 96.07% of syntax errors in generated Python and Go code, showcasing its substantial impact on enhancing syntactical precision in LLM generation. Our code is available at https://github.com/uiuc-focal-lab/syncode
4/30/2024