Constraining Large Language Model for Generating Computer-Parsable Content
2404.05499
0
0
💬
Abstract
We propose a method to guide Large Language Models (LLMs) in generating structured content adhering to specific conventions without fine-tuning. By utilizing coroutine-based content generation constraints through a pre-agreed context-free grammar (CFG), LLMs are directed during decoding to produce formal language compliant outputs. This enhances stability and consistency in generating target data structures, types, or instructions, reducing application development complexities. Experimentally, error rates of GPT-2 and Gemma exceed 95% for DSLs longer than 36 and 282 tokens, respectively. We introduce YieldLang, a coroutine-based DSL generation framework, and evaluate it with LLMs on various tasks including JSON and Mermaid flowchart generation. Compared to benchmarks, our approach improves accuracy by 1.09 to 11.6 times, with LLMs requiring only about 16.5% of the samples to generate JSON effectively. This enhances usability of LLM-generated content for computer programs.
Create account to get full access
Overview
- Proposes a method to guide Large Language Models (LLMs) in generating structured content without fine-tuning
- Utilizes coroutine-based content generation constraints through a pre-agreed context-free grammar (CFG)
- Aims to enhance stability and consistency in generating target data structures, types, or instructions
- Introduces YieldLang, a coroutine-based DSL generation framework
- Evaluates the approach with LLMs on various tasks including JSON and Mermaid flowchart generation
Plain English Explanation
Large Language Models (LLMs) are powerful AI systems that can generate human-like text. However, using LLMs to create structured content, such as computer code or data formats, can be challenging. The authors of this paper propose a method to guide LLMs in generating structured content that adheres to specific conventions, without the need for extensive fine-tuning.
The key idea is to use a pre-agreed context-free grammar (CFG) to define the rules and structure of the desired output. During the content generation process, the LLM is directed by "coroutine-based content generation constraints" to produce formal language that complies with these rules. This helps ensure the stability and consistency of the generated output, reducing the complexity of application development.
The researchers introduce a framework called YieldLang that implements this coroutine-based approach. They evaluate YieldLang with LLMs on various tasks, such as generating JSON data and Mermaid flowcharts. Compared to benchmark methods, their approach significantly improves the accuracy of the generated content, while requiring fewer training samples for the LLMs to be effective.
This work has important implications for making LLM-generated content more usable in computer programs, as it addresses the challenge of maintaining the structure and integrity of the output. By guiding LLMs to produce formal language, the authors aim to enhance the practical applications of these powerful AI models.
Technical Explanation
The paper proposes a method to guide Large Language Models (LLMs) in generating structured content that adheres to specific conventions, without the need for fine-tuning. The key elements of their approach are:
-
Coroutine-based Content Generation Constraints: The researchers utilize a pre-agreed context-free grammar (CFG) to define the rules and structure of the desired output. During the decoding process, the LLM is directed by these coroutine-based constraints to produce formal language that complies with the CFG.
-
YieldLang Framework: The authors introduce a coroutine-based domain-specific language (DSL) generation framework called YieldLang. This framework allows for the integration of the coroutine-based constraints with LLMs to generate structured content.
-
Experimental Evaluation: The researchers evaluate their approach on various tasks, including the generation of JSON data and Mermaid flowcharts. They compare the performance of GPT-2 and Gemma LLMs with and without their coroutine-based constraints.
The experiments show that without the constraints, the error rates of GPT-2 and Gemma exceed 95% for DSLs longer than 36 and 282 tokens, respectively. However, when using the coroutine-based constraints through the YieldLang framework, the accuracy of the generated content improves significantly, outperforming benchmark methods by 1.09 to 11.6 times. Additionally, the LLMs require only about 16.5% of the samples to generate JSON effectively, enhancing the usability of the LLM-generated content for computer programs.
Critical Analysis
The paper presents a promising approach to guiding Large Language Models (LLMs) in generating structured content that adheres to specific conventions. The use of coroutine-based constraints and a pre-agreed context-free grammar (CFG) is an innovative way to address the challenge of maintaining the integrity and stability of LLM-generated output.
One potential limitation mentioned in the paper is the need for a pre-agreed CFG, which may not always be available or easy to define, particularly for more complex or domain-specific tasks. Additionally, the authors note that their approach may not be as effective for longer DSLs, as the error rates for GPT-2 and Gemma still exceed 95% for DSLs longer than 36 and 282 tokens, respectively.
Further research could explore ways to make the CFG definition process more accessible or even automatically infer the CFG from example data. Additionally, investigating the scalability and generalization of the approach to a wider range of structured content types and LLM architectures could be valuable.
Overall, the paper presents a compelling technique for enhancing the usability of LLM-generated content in computer programs, and the YieldLang framework offers a promising starting point for further advancements in this area.
Conclusion
This paper proposes a method to guide Large Language Models (LLMs) in generating structured content that adheres to specific conventions, without the need for extensive fine-tuning. By utilizing coroutine-based content generation constraints and a pre-agreed context-free grammar (CFG), the researchers were able to significantly improve the accuracy and stability of LLM-generated output on tasks such as JSON and Mermaid flowchart generation.
The introduced YieldLang framework provides a practical implementation of this approach, and the experimental results demonstrate its potential to enhance the usability of LLM-generated content for computer programs. This work represents an important step towards bridging the gap between the powerful text generation capabilities of LLMs and the specific structured requirements of many real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DocCGen: Document-based Controlled Code Generation
Sameer Pimparkhede, Mehant Kammakomati, Srikanth G. Tamilselvam, Prince Kumar, Ashok Pon Kumar, Pushpak Bhattacharyya
0
0
Recent developments show that Large Language Models (LLMs) produce state-of-the-art performance on natural language (NL) to code generation for resource-rich general-purpose languages like C++, Java, and Python. However, their practical usage for structured domain-specific languages (DSLs) such as YAML, JSON is limited due to domain-specific schema, grammar, and customizations generally unseen by LLMs during pre-training. Efforts have been made to mitigate this challenge via in-context learning through relevant examples or by fine-tuning. However, it suffers from problems, such as limited DSL samples and prompt sensitivity but enterprises maintain good documentation of the DSLs. Therefore, we propose DocCGen, a framework that can leverage such rich knowledge by breaking the NL-to-Code generation task for structured code languages into a two-step process. First, it detects the correct libraries using the library documentation that best matches the NL query. Then, it utilizes schema rules extracted from the documentation of these libraries to constrain the decoding. We evaluate our framework for two complex structured languages, Ansible YAML and Bash command, consisting of two settings: Out-of-domain (OOD) and In-domain (ID). Our extensive experiments show that DocCGen consistently improves different-sized language models across all six evaluation metrics, reducing syntactic and semantic errors in structured code. We plan to open-source the datasets and code to motivate research in constrained code generation.
6/19/2024

From Tarzan to Tolkien: Controlling the Language Proficiency Level of LLMs for Content Generation
Ali Malik, Stephen Mayhew, Chris Piech, Klinton Bicknell
0
0
We study the problem of controlling the difficulty level of text generated by Large Language Models (LLMs) for contexts where end-users are not fully proficient, such as language learners. Using a novel framework, we evaluate the effectiveness of several key approaches for this task, including few-shot prompting, supervised finetuning, and reinforcement learning (RL), utilising both GPT-4 and open source alternatives like LLama2-7B and Mistral-7B. Our findings reveal a large performance gap between GPT-4 and the open source models when using prompt-based strategies. However, we show how to bridge this gap with a careful combination of finetuning and RL alignment. Our best model, CALM (CEFR-Aligned Language Model), surpasses the performance of GPT-4 and other strategies, at only a fraction of the cost. We further validate the quality of our results through a small-scale human study.
6/6/2024

Generating Games via LLMs: An Investigation with Video Game Description Language
Chengpeng Hu, Yunlong Zhao, Jialin Liu
0
0
Recently, the emergence of large language models (LLMs) has unlocked new opportunities for procedural content generation. However, recent attempts mainly focus on level generation for specific games with defined game rules such as Super Mario Bros. and Zelda. This paper investigates the game generation via LLMs. Based on video game description language, this paper proposes an LLM-based framework to generate game rules and levels simultaneously. Experiments demonstrate how the framework works with prompts considering different combinations of context. Our findings extend the current applications of LLMs and offer new insights for generating new games in the area of procedural content generation.
5/31/2024
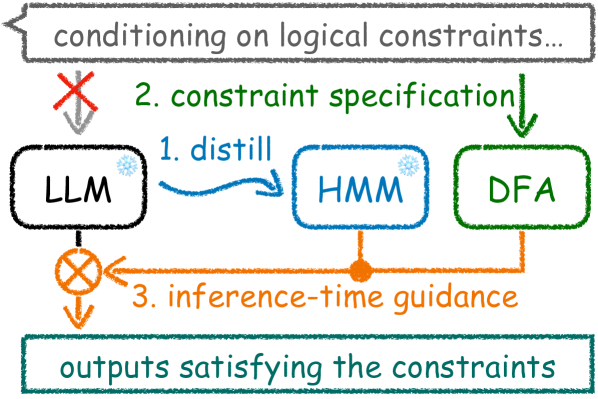
Adaptable Logical Control for Large Language Models
Honghua Zhang, Po-Nien Kung, Masahiro Yoshida, Guy Van den Broeck, Nanyun Peng
0
0
Despite the success of Large Language Models (LLMs) on various tasks following human instructions, controlling model generation at inference time poses a persistent challenge. In this paper, we introduce Ctrl-G, an adaptable framework that facilitates tractable and flexible control of LLM generation to reliably follow logical constraints. Ctrl-G combines any production-ready LLM with a Hidden Markov Model, enabling LLM outputs to adhere to logical constraints represented as deterministic finite automata. We show that Ctrl-G, when applied to a TULU2-7B model, outperforms GPT3.5 and GPT4 on the task of interactive text editing: specifically, for the task of generating text insertions/continuations following logical constraints, Ctrl-G achieves over 30% higher satisfaction rate in human evaluation compared to GPT4. When applied to medium-size language models (e.g., GPT2-large), Ctrl-G also beats its counterparts for constrained generation by large margins on standard benchmarks. Additionally, as a proof-of-concept study, we experiment Ctrl-G on the Grade School Math benchmark to assist LLM reasoning, foreshadowing the application of Ctrl-G, as well as other constrained generation approaches, beyond traditional language generation tasks.
6/21/2024