DocNet: Semantic Structure in Inductive Bias Detection Models

0

Sign in to get full access
Overview
- This paper introduces "DocNet", a model for detecting inductive biases in deep learning models.
- Inductive biases refer to the inherent assumptions and preferences a model has, which can lead to unfair or biased outputs.
- The authors propose using the semantic structure of the input data as a way to identify and mitigate these biases.
Plain English Explanation
The paper focuses on a problem called "inductive bias" in machine learning models. Inductive bias refers to the hidden assumptions and preferences that get built into a model as it is trained on data.
These biases can lead to unfair or biased outputs from the model, even if the training data seemed neutral. For example, link a model trained on news articles may learn to associate certain demographic groups with negative sentiments.
The key idea in this paper is to use the semantic structure of the input data as a way to identify and mitigate these biases. By understanding how the meaning and relationships between different parts of the input data influence the model's behavior, the researchers believe they can pinpoint and correct problematic biases.
They introduce a new model architecture called "DocNet" that is designed to capture this semantic structure. The goal is to create machine learning systems that are more fair and unbiased in their outputs. This connects to broader efforts in the field to address algorithmic bias and build ethical AI systems.
Technical Explanation
The key technical contribution of this paper is the "DocNet" model architecture, which is designed to capture the semantic structure of input data in order to detect and mitigate inductive biases.
DocNet takes a document as input and learns a hierarchical representation that encodes the semantic relationships between different parts of the text. This is done through a multi-scale attention mechanism that aggregates information from the word, sentence, and document levels.
The authors then use this semantic representation to train a classifier that can identify inductive biases in other machine learning models. By probing how the target model responds to carefully constructed inputs, they can pinpoint the specific biases present and propose ways to address them.
The paper evaluates DocNet on several benchmark datasets for bias detection, showing that it outperforms previous approaches link that relied more on surface-level textual features. The authors argue that capturing the deeper semantic structure is crucial for accurately identifying problematic biases.
Critical Analysis
The key strength of this work is its focus on using semantic understanding to tackle the important problem of inductive bias in machine learning. Many existing bias detection methods link have been limited by their reliance on superficial textual features, so the authors' emphasis on modeling deeper meaning is a promising direction.
That said, the paper does not extensively explore the limitations of the DocNet approach. It is unclear how the model would perform on more complex or ambiguous inputs, where semantic relationships may be harder to disentangle. There is also the question of how to effectively "de-bias" a target model once problematic inductive biases have been identified.
Additionally, the ethical implications of this work could be discussed in more depth. While the authors frame bias detection as a way to build fairer AI systems, there are valid concerns about the potential misuse of such technologies for surveillance or manipulation. A more nuanced treatment of these issues would strengthen the paper.
Overall, this is an interesting and technically solid contribution to the important field of algorithmic bias mitigation. But there is still significant room for further research and critical reflection on the societal impacts of these techniques.
Conclusion
In summary, this paper introduces DocNet, a novel model architecture for detecting inductive biases in machine learning systems. By capturing the semantic structure of input data, DocNet aims to more accurately identify problematic biases that can lead to unfair or discriminatory outputs.
The authors demonstrate promising results on bias detection benchmarks, suggesting that a deeper understanding of meaning is crucial for this task. However, the paper could be strengthened by a more thorough exploration of the limitations and broader implications of this work.
As the field of ethical AI continues to evolve, approaches like DocNet that combine technical innovation with careful consideration of societal impact will be increasingly important. This paper represents a valuable step in that direction, but there is still much work to be done.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DocNet: Semantic Structure in Inductive Bias Detection Models
Jessica Zhu, Iain Cruickshank, Michel Cukier
News will have biases so long as people have opinions. However, as social media becomes the primary entry point for news and partisan gaps increase, it is increasingly important for informed citizens to be able to identify bias. People will be able to take action to avoid polarizing echo chambers if they know how the news they are consuming is biased. In this paper, we explore an often overlooked aspect of bias detection in documents: the semantic structure of news articles. We present DocNet, a novel, inductive, and low-resource document embedding and bias detection model that outperforms large language models. We also demonstrate that the semantic structure of news articles from opposing partisan sides, as represented in document-level graph embeddings, have significant similarities. These results can be used to advance bias detection in low-resource environments. Our code and data are made available at https://github.com/nlpresearchanon.
Read more6/18/2024
0
BiasScanner: Automatic Detection and Classification of News Bias to Strengthen Democracy
Tim Menzner, Jochen L. Leidner
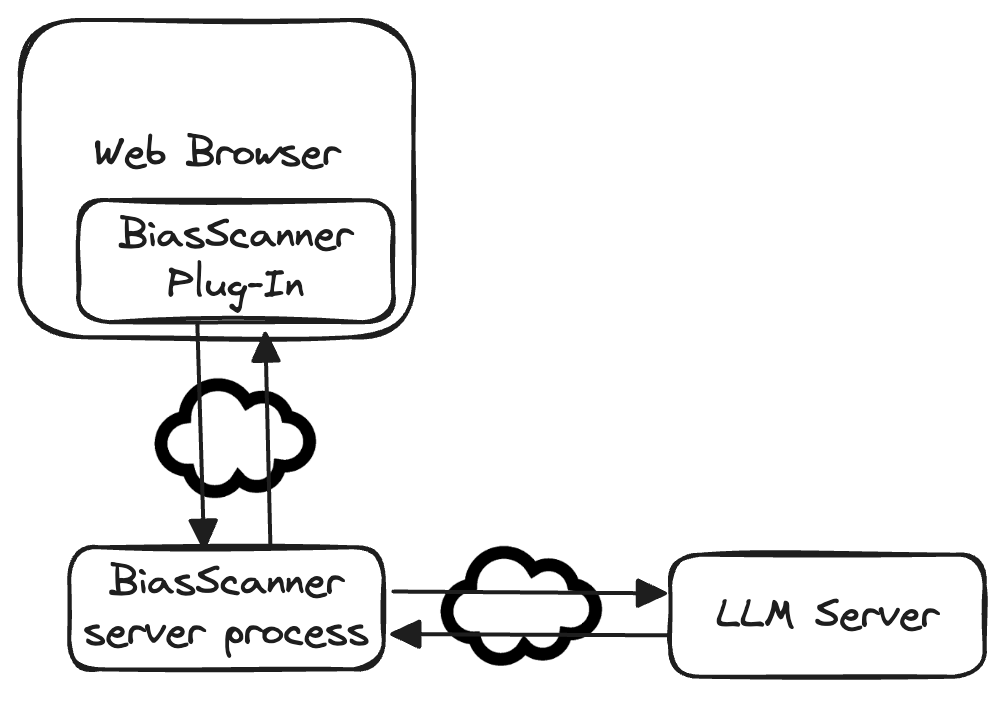
The increasing consumption of news online in the 21st century coincided with increased publication of disinformation, biased reporting, hate speech and other unwanted Web content. We describe BiasScanner, an application that aims to strengthen democracy by supporting news consumers with scrutinizing news articles they are reading online. BiasScanner contains a server-side pre-trained large language model to identify biased sentences of news articles and a front-end Web browser plug-in. At the time of writing, BiasScanner can identify and classify more than two dozen types of media bias at the sentence level, making it the most fine-grained model and only deployed application (automatic system in use) of its kind. It was implemented in a light-weight and privacy-respecting manner, and in addition to highlighting likely biased sentence it also provides explanations for each classification decision as well as a summary analysis for each news article. While prior research has addressed news bias detection, we are not aware of any work that resulted in a deployed browser plug-in (c.f. also biasscanner.org for a Web demo).
Read more7/16/2024
🔎
0
Experiments in News Bias Detection with Pre-Trained Neural Transformers
Tim Menzner, Jochen L. Leidner
The World Wide Web provides unrivalled access to information globally, including factual news reporting and commentary. However, state actors and commercial players increasingly spread biased (distorted) or fake (non-factual) information to promote their agendas. We compare several large, pre-trained language models on the task of sentence-level news bias detection and sub-type classification, providing quantitative and qualitative results.
Read more6/17/2024

0
Leveraging Ontologies to Document Bias in Data
Mayra Russo, Maria-Esther Vidal
Machine Learning (ML) systems are capable of reproducing and often amplifying undesired biases. This puts emphasis on the importance of operating under practices that enable the study and understanding of the intrinsic characteristics of ML pipelines, prompting the emergence of documentation frameworks with the idea that ``any remedy for bias starts with awareness of its existence''. However, a resource that can formally describe these pipelines in terms of biases detected is still amiss. To fill this gap, we present the Doc-BiasO ontology, a resource that aims to create an integrated vocabulary of biases defined in the textit{fair-ML} literature and their measures, as well as to incorporate relevant terminology and the relationships between them. Overseeing ontology engineering best practices, we re-use existing vocabulary on machine learning and AI, to foster knowledge sharing and interoperability between the actors concerned with its research, development, regulation, among others. Overall, our main objective is to contribute towards clarifying existing terminology on bias research as it rapidly expands to all areas of AI and to improve the interpretation of bias in data and downstream impact.
Read more8/13/2024