DocXplain: A Novel Model-Agnostic Explainability Method for Document Image Classification

0
Sign in to get full access
Overview
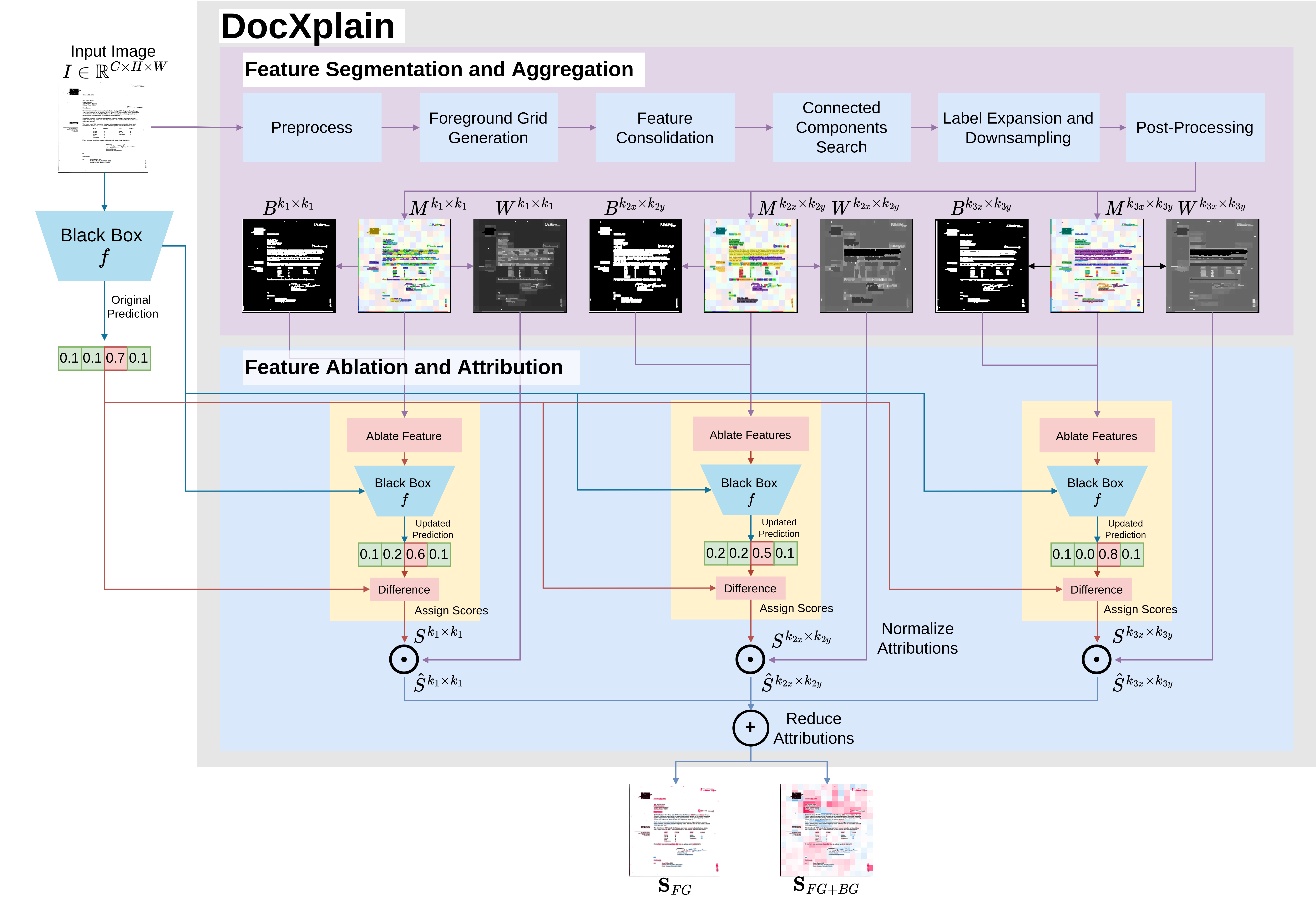
- This paper proposes a novel model-agnostic explainability method called DocXplain for document image classification tasks.
- The method aims to provide interpretable explanations for the model's predictions without requiring access to the model's internal architecture.
- The approach leverages a reinforcement learning-based technique to identify the most relevant regions of the input document image that contribute to the classification decision.
Plain English Explanation
DocXplain: A Novel Model-Agnostic Explainability Method for Document Image Classification is a research paper that introduces a new way to explain how document classification models make their predictions. The key idea is to identify the specific regions or areas of the document image that are most important for the model's decision, without needing to know the internal details of the model itself.
This is useful because many advanced document classification models can be complex "black boxes" - it's not always clear how they arrive at their conclusions. DocXplain provides a way to "peek under the hood" and understand the model's reasoning in a more interpretable way.
The paper uses a reinforcement learning approach to systematically identify the most relevant parts of the document image that contribute to the classification. This allows the model to highlight the specific regions that are driving its decisions, rather than just providing a generic explanation.
By making the model's decision-making process more transparent, DocXplain can help users better understand and trust the model's outputs. This is particularly important for high-stakes applications like medical diagnosis or financial risk assessment, where model interpretability is crucial.
Technical Explanation
The DocXplain method works by training a separate "explanation" model that learns to identify the most salient regions of the input document image. This explanation model is trained using a reinforcement learning approach, where it receives rewards for correctly identifying the regions that are most important for the classification task.
The key components of the DocXplain architecture include:
- Classifier Model: The original model that performs the document image classification task. This can be any type of model, as DocXplain is designed to be model-agnostic.
- Explanation Model: The reinforcement learning-based model that learns to highlight the relevant regions of the input document.
- Reinforcement Learning Reward Function: The signal used to train the explanation model, which encourages it to focus on the most important parts of the document for the classification.
During inference, the explanation model is used to generate a heatmap or saliency map that shows which regions of the document image were most influential in the classifier's prediction. This provides users with a visual explanation of the model's decision-making process.
The paper evaluates DocXplain on several document image classification benchmarks and demonstrates its effectiveness in improving model interpretability without compromising classification performance.
Critical Analysis
The paper makes a compelling case for the importance of model interpretability in document image classification tasks, and the DocXplain method appears to be a promising approach to address this need.
One potential limitation is that the performance of the explanation model is dependent on the quality of the reinforcement learning reward function. If the reward function does not accurately capture the most relevant regions for the classification task, the explanation model may fail to highlight the true drivers of the classifier's decisions.
Additionally, while DocXplain is designed to be model-agnostic, the paper does not explore how the method might perform on a wider range of classifier architectures, such as end-to-end deep learning models. Further research could investigate the generalizability of DocXplain to a broader set of document classification models.
Another area for further exploration is the potential for DocXplain to be extended to other types of image-based classification tasks, beyond just document images. The core principles of the method may be applicable to a wider range of visual recognition problems where model interpretability is important.
Conclusion
The DocXplain method represents a novel and promising approach to improving the interpretability of document image classification models. By using a reinforcement learning-based explanation model, the method can highlight the specific regions of the input document that are most influential in the classifier's predictions, without requiring access to the model's internal architecture.
This increased transparency can help build trust and understanding in the model's outputs, which is particularly important for high-stakes applications where model interpretability is crucial. The paper demonstrates the effectiveness of DocXplain on several benchmark datasets, and the method's model-agnostic design suggests it could be broadly applicable to a range of document classification tasks.
Overall, the DocXplain research contributes to the growing field of explainable AI, which aims to make machine learning models more interpretable and accessible to human users. As AI systems become increasingly prevalent in real-world applications, methods like DocXplain will play an important role in ensuring these models are transparent, accountable, and aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DocXplain: A Novel Model-Agnostic Explainability Method for Document Image Classification
Saifullah Saifullah, Stefan Agne, Andreas Dengel, Sheraz Ahmed
Deep learning (DL) has revolutionized the field of document image analysis, showcasing superhuman performance across a diverse set of tasks. However, the inherent black-box nature of deep learning models still presents a significant challenge to their safe and robust deployment in industry. Regrettably, while a plethora of research has been dedicated in recent years to the development of DL-powered document analysis systems, research addressing their transparency aspects has been relatively scarce. In this paper, we aim to bridge this research gap by introducing DocXplain, a novel model-agnostic explainability method specifically designed for generating high interpretability feature attribution maps for the task of document image classification. In particular, our approach involves independently segmenting the foreground and background features of the documents into different document elements and then ablating these elements to assign feature importance. We extensively evaluate our proposed approach in the context of document image classification, utilizing 4 different evaluation metrics, 2 widely recognized document benchmark datasets, and 10 state-of-the-art document image classification models. By conducting a thorough quantitative and qualitative analysis against 9 existing state-of-the-art attribution methods, we demonstrate the superiority of our approach in terms of both faithfulness and interpretability. To the best of the authors' knowledge, this work presents the first model-agnostic attribution-based explainability method specifically tailored for document images. We anticipate that our work will significantly contribute to advancing research on transparency, fairness, and robustness of document image classification models.
Read more7/8/2024

0
Aligning Human Knowledge with Visual Concepts Towards Explainable Medical Image Classification
Yunhe Gao, Difei Gu, Mu Zhou, Dimitris Metaxas
Although explainability is essential in the clinical diagnosis, most deep learning models still function as black boxes without elucidating their decision-making process. In this study, we investigate the explainable model development that can mimic the decision-making process of human experts by fusing the domain knowledge of explicit diagnostic criteria. We introduce a simple yet effective framework, Explicd, towards Explainable language-informed criteria-based diagnosis. Explicd initiates its process by querying domain knowledge from either large language models (LLMs) or human experts to establish diagnostic criteria across various concept axes (e.g., color, shape, texture, or specific patterns of diseases). By leveraging a pretrained vision-language model, Explicd injects these criteria into the embedding space as knowledge anchors, thereby facilitating the learning of corresponding visual concepts within medical images. The final diagnostic outcome is determined based on the similarity scores between the encoded visual concepts and the textual criteria embeddings. Through extensive evaluation of five medical image classification benchmarks, Explicd has demonstrated its inherent explainability and extends to improve classification performance compared to traditional black-box models.
Read more6/11/2024
📉
0
T-Explainer: A Model-Agnostic Explainability Framework Based on Gradients
Evandro S. Ortigossa, F'abio F. Dias, Brian Barr, Claudio T. Silva, Luis Gustavo Nonato
The development of machine learning applications has increased significantly in recent years, motivated by the remarkable ability of learning-powered systems to discover and generalize intricate patterns hidden in massive datasets. Modern learning models, while powerful, often have a level of complexity that renders them opaque black boxes, resulting in a notable lack of transparency that hinders our ability to decipher their reasoning. Opacity challenges the interpretability and practical application of machine learning, especially in critical domains where understanding the underlying reasons is essential for informed decision-making. Explainable Artificial Intelligence (XAI) rises to address that challenge, unraveling the complexity of black boxes by providing elucidating explanations. Among the various XAI approaches, feature attribution/importance stands out for its capacity to delineate the significance of input features in the prediction process. However, most existing attribution methods have limitations, such as instability, when divergent explanations may result from similar or even the same instance. This work introduces T-Explainer, a novel local additive attribution explainer based on Taylor expansion. It has desirable properties, such as local accuracy and consistency, making T-Explainer stable over multiple runs. We demonstrate T-Explainer's effectiveness in quantitative benchmark experiments against well-known attribution methods. Additionally, we provide several tools to evaluate and visualize explanations, turning T-Explainer into a comprehensive XAI framework.
Read more8/7/2024
💬
0
TExplain: Explaining Learned Visual Features via Pre-trained (Frozen) Language Models
Saeid Asgari Taghanaki, Aliasghar Khani, Ali Saheb Pasand, Amir Khasahmadi, Aditya Sanghi, Karl D. D. Willis, Ali Mahdavi-Amiri
Interpreting the learned features of vision models has posed a longstanding challenge in the field of machine learning. To address this issue, we propose a novel method that leverages the capabilities of language models to interpret the learned features of pre-trained image classifiers. Our method, called TExplain, tackles this task by training a neural network to establish a connection between the feature space of image classifiers and language models. Then, during inference, our approach generates a vast number of sentences to explain the features learned by the classifier for a given image. These sentences are then used to extract the most frequent words, providing a comprehensive understanding of the learned features and patterns within the classifier. Our method, for the first time, utilizes these frequent words corresponding to a visual representation to provide insights into the decision-making process of the independently trained classifier, enabling the detection of spurious correlations, biases, and a deeper comprehension of its behavior. To validate the effectiveness of our approach, we conduct experiments on diverse datasets, including ImageNet-9L and Waterbirds. The results demonstrate the potential of our method to enhance the interpretability and robustness of image classifiers.
Read more5/3/2024