TExplain: Explaining Learned Visual Features via Pre-trained (Frozen) Language Models

0
💬
Sign in to get full access
Overview
- Interpreting the learned features of vision models is a longstanding challenge in machine learning.
- The authors propose a novel method called TExplain that leverages language models to interpret the learned features of pre-trained image classifiers.
- TExplain trains a neural network to establish a connection between the feature space of image classifiers and language models.
- During inference, TExplain generates a large number of sentences to explain the features learned by the classifier for a given image.
- The frequent words extracted from these sentences provide insights into the decision-making process of the image classifier, enabling the detection of spurious correlations, biases, and a deeper understanding of its behavior.
Plain English Explanation
Interpreting the Learned Features of Vision Models is a challenge in machine learning because it's not always clear how image classification models arrive at their decisions.
To address this, the authors developed a new method called TExplain that uses language models to help interpret the features learned by image classification models.
Here's how it works:
- TExplain trains a neural network to connect the feature space of image classifiers with the feature space of language models.
- When you show TExplain an image, it generates a large number of sentences that explain the features the image classifier has learned.
- From these sentences, TExplain extracts the most frequent words, which provide insights into how the image classifier is making its decisions.
This allows you to better understand the classifier's behavior, including any biases or spurious correlations it may have learned. It can also help make the classifier more interpretable and robust.
Technical Explanation
TExplain tackles the challenge of interpreting the learned features of vision models by leveraging the capabilities of language models. The authors train a neural network to establish a connection between the feature space of pre-trained image classifiers and language models.
During inference, TExplain generates a vast number of sentences to explain the features learned by the classifier for a given image. These sentences are then analyzed to extract the most frequent words, providing a comprehensive understanding of the learned features and patterns within the classifier.
The authors conduct experiments on diverse datasets, including ImageNet-9L and Waterbirds, to validate the effectiveness of their approach. The results demonstrate the potential of TExplain to enhance the interpretability and robustness of image classifiers by enabling the detection of spurious correlations and biases.
Critical Analysis
The paper presents a novel and promising approach to interpreting the learned features of vision models. However, there are a few potential limitations and areas for further research:
- The authors only evaluated TExplain on a limited set of datasets. It would be valuable to test the method on a wider range of datasets and task domains to understand its generalizability.
- The paper does not provide a detailed analysis of the computational complexity and runtime performance of TExplain, which could be an important consideration for real-world applications.
- While TExplain can provide insights into the decision-making process of the image classifier, the paper does not explore whether these insights can be used to directly improve the classifier's performance or robustness.
Overall, the research presented in this paper is a valuable contribution to the field of machine learning interpretability, and the TExplain method shows promise for enhancing the transparency and understanding of vision models.
Conclusion
The paper introduces a novel method called TExplain that leverages the power of language models to interpret the learned features of pre-trained image classifiers. By generating explanatory sentences and extracting the most frequent words, TExplain provides valuable insights into the decision-making process of the image classifier, enabling the detection of biases and spurious correlations.
The experimental results demonstrate the potential of TExplain to enhance the interpretability and robustness of image classification models, which is a crucial step towards building more trustworthy and transparent AI systems. While the paper identifies a few areas for further research, the TExplain approach represents an important advancement in the field of machine learning interpretability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
TExplain: Explaining Learned Visual Features via Pre-trained (Frozen) Language Models
Saeid Asgari Taghanaki, Aliasghar Khani, Ali Saheb Pasand, Amir Khasahmadi, Aditya Sanghi, Karl D. D. Willis, Ali Mahdavi-Amiri
Interpreting the learned features of vision models has posed a longstanding challenge in the field of machine learning. To address this issue, we propose a novel method that leverages the capabilities of language models to interpret the learned features of pre-trained image classifiers. Our method, called TExplain, tackles this task by training a neural network to establish a connection between the feature space of image classifiers and language models. Then, during inference, our approach generates a vast number of sentences to explain the features learned by the classifier for a given image. These sentences are then used to extract the most frequent words, providing a comprehensive understanding of the learned features and patterns within the classifier. Our method, for the first time, utilizes these frequent words corresponding to a visual representation to provide insights into the decision-making process of the independently trained classifier, enabling the detection of spurious correlations, biases, and a deeper comprehension of its behavior. To validate the effectiveness of our approach, we conduct experiments on diverse datasets, including ImageNet-9L and Waterbirds. The results demonstrate the potential of our method to enhance the interpretability and robustness of image classifiers.
Read more5/3/2024

0
Explainable Concept Generation through Vision-Language Preference Learning
Aditya Taparia, Som Sagar, Ransalu Senanayake
Concept-based explanations have become a popular choice for explaining deep neural networks post-hoc because, unlike most other explainable AI techniques, they can be used to test high-level visual concepts that are not directly related to feature attributes. For instance, the concept of stripes is important to classify an image as a zebra. Concept-based explanation methods, however, require practitioners to guess and collect multiple candidate concept image sets, which can often be imprecise and labor-intensive. Addressing this limitation, in this paper, we frame concept image set creation as an image generation problem. However, since naively using a generative model does not result in meaningful concepts, we devise a reinforcement learning-based preference optimization algorithm that fine-tunes the vision-language generative model from approximate textual descriptions of concepts. Through a series of experiments, we demonstrate the capability of our method to articulate complex, abstract concepts that are otherwise challenging to craft manually. In addition to showing the efficacy and reliability of our method, we show how our method can be used as a diagnostic tool for analyzing neural networks.
Read more8/27/2024
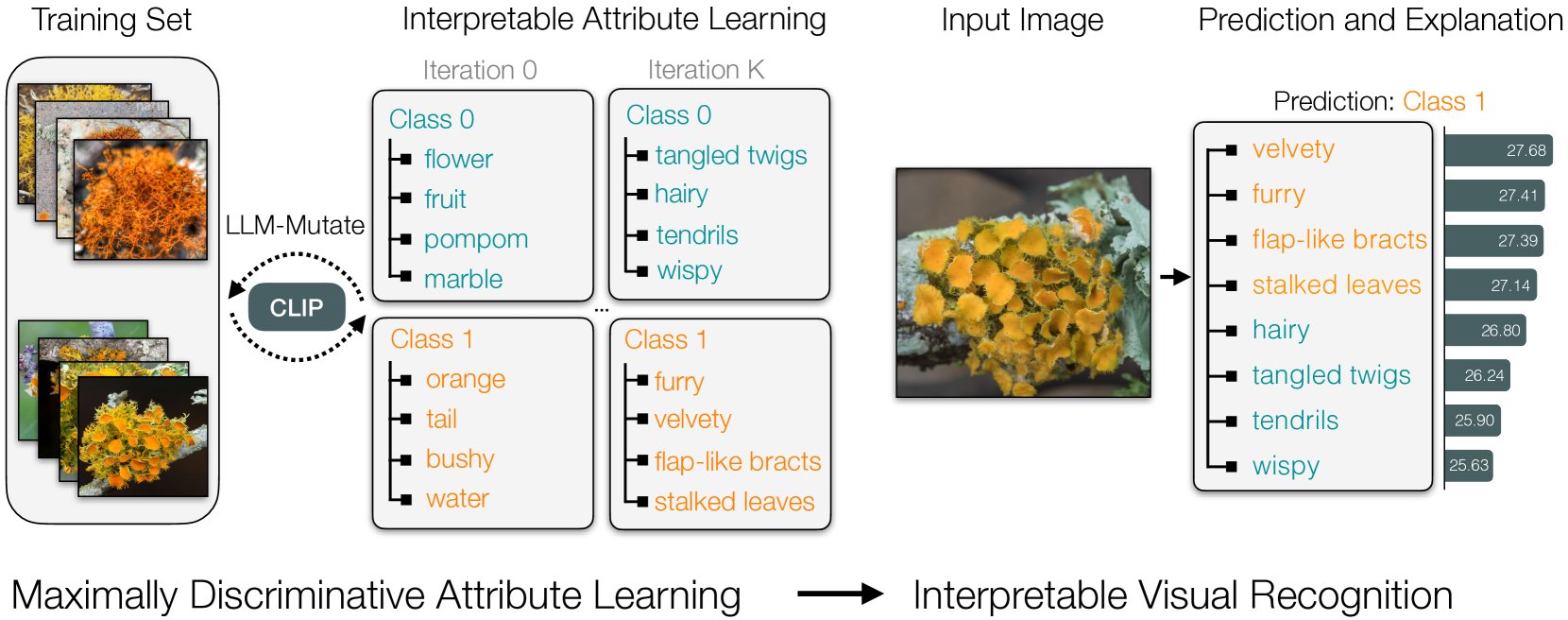
0
Evolving Interpretable Visual Classifiers with Large Language Models
Mia Chiquier, Utkarsh Mall, Carl Vondrick
Multimodal pre-trained models, such as CLIP, are popular for zero-shot classification due to their open-vocabulary flexibility and high performance. However, vision-language models, which compute similarity scores between images and class labels, are largely black-box, with limited interpretability, risk for bias, and inability to discover new visual concepts not written down. Moreover, in practical settings, the vocabulary for class names and attributes of specialized concepts will not be known, preventing these methods from performing well on images uncommon in large-scale vision-language datasets. To address these limitations, we present a novel method that discovers interpretable yet discriminative sets of attributes for visual recognition. We introduce an evolutionary search algorithm that uses a large language model and its in-context learning abilities to iteratively mutate a concept bottleneck of attributes for classification. Our method produces state-of-the-art, interpretable fine-grained classifiers. We outperform the latest baselines by 18.4% on five fine-grained iNaturalist datasets and by 22.2% on two KikiBouba datasets, despite the baselines having access to privileged information about class names.
Read more4/16/2024

0
From Redundancy to Relevance: Enhancing Explainability in Multimodal Large Language Models
Xiaofeng Zhang, Chen Shen, Xiaosong Yuan, Shaotian Yan, Liang Xie, Wenxiao Wang, Chaochen Gu, Hao Tang, Jieping Ye
Recently, multimodal large language models have exploded with an endless variety, most of the popular Large Vision Language Models (LVLMs) depend on sequential visual representation, where images are converted into hundreds or thousands of tokens before being input into the Large Language Model (LLM) along with language prompts. The black-box design hinders the interpretability of visual-language models, especially regarding more complex reasoning tasks. To explore the interaction process between image and text in complex reasoning tasks, we introduce the information flow method to visualize the interaction mechanism. By analyzing the dynamic flow of the information flow, we find that the information flow appears to converge in the shallow layer. Further investigation revealed a redundancy of the image token in the shallow layer. Consequently, a truncation strategy was introduced to aggregate image tokens within these shallow layers. This approach has been validated through experiments across multiple models, yielding consistent improvements.
Read more6/14/2024