Does GPT Really Get It? A Hierarchical Scale to Quantify Human vs AI's Understanding of Algorithms
2406.14722
0
0
Abstract
As Large Language Models (LLMs) perform (and sometimes excel at) more and more complex cognitive tasks, a natural question is whether AI really understands. The study of understanding in LLMs is in its infancy, and the community has yet to incorporate well-trodden research in philosophy, psychology, and education. We initiate this, specifically focusing on understanding algorithms, and propose a hierarchy of levels of understanding. We use the hierarchy to design and conduct a study with human subjects (undergraduate and graduate students) as well as large language models (generations of GPT), revealing interesting similarities and differences. We expect that our rigorous criteria will be useful to keep track of AI's progress in such cognitive domains.
Create account to get full access
Overview
• This paper proposes a hierarchical scale to quantify the understanding of algorithms by both humans and AI systems. • It explores the different levels of understanding, ranging from basic knowledge to the ability to explain, apply, and generalize algorithmic concepts. • The researchers aim to provide a framework for assessing and comparing the algorithm understanding capabilities of humans and AI models, such as GPT-3.
Plain English Explanation
Algorithms are the step-by-step instructions that computers and AI systems use to solve problems. Understanding how these algorithms work is crucial for both humans and AI models. This paper introduces a new way to measure and compare the level of understanding that humans and AI systems have of algorithms.
The researchers have created a hierarchical scale that ranges from the most basic knowledge of an algorithm to the ability to fully explain, apply, and generalize its concepts. At the lowest level, someone might simply be able to identify the steps of an algorithm. At the highest level, they could deeply understand the algorithm, adapt it to new situations, and even create new algorithms based on the same principles.
By using this scale, the researchers hope to better understand how well AI models, like GPT-3, are able to comprehend and work with algorithms. This could help improve the development of AI systems that can truly understand and reason about the algorithms they use, rather than just following instructions without deeper comprehension.
Technical Explanation
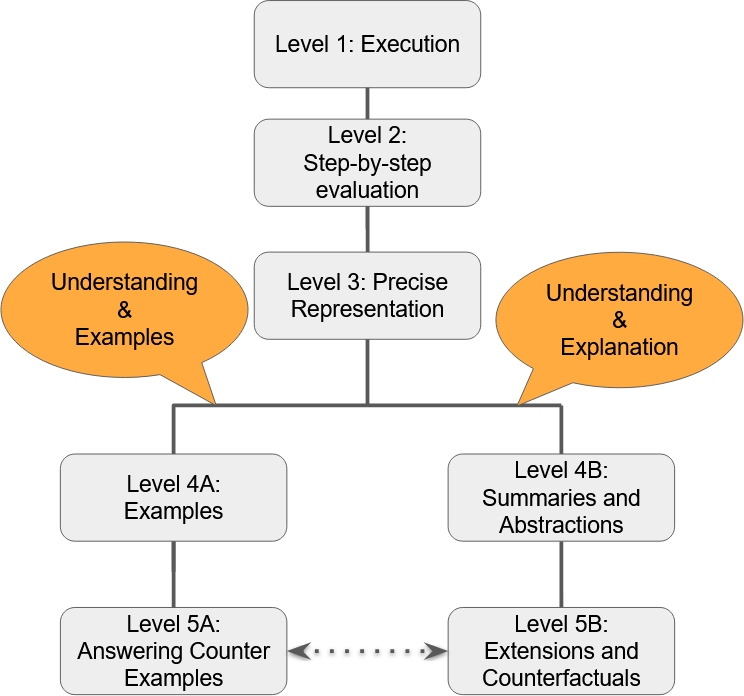
The paper presents a hierarchical scale to measure algorithm understanding, inspired by Bloom's taxonomy of educational objectives. This scale consists of five levels:
- Identification: The ability to recognize and name the steps of an algorithm.
- Explanation: The ability to describe how an algorithm works and why it is structured in a particular way.
- Application: The ability to use an algorithm to solve problems, including modifying it for new situations.
- Analysis: The ability to break down an algorithm, understand its components, and evaluate its efficiency or correctness.
- Synthesis: The ability to design new algorithms based on an understanding of algorithmic principles.
The researchers conducted experiments to evaluate the algorithm understanding of both humans and the GPT-3 language model. They designed tasks that tested participants' abilities at each level of the scale, and compared the performance of humans and GPT-3.
The results suggest that while GPT-3 can perform well on basic tasks like algorithm identification, it struggles to demonstrate deeper levels of understanding, such as analysis and synthesis. This reveals limitations in the ability of large language models to truly comprehend and reason about algorithms, beyond just pattern matching and text generation.
Critical Analysis
The proposed hierarchical scale provides a valuable framework for assessing algorithm understanding, but it is important to note that the levels are not necessarily discrete or mutually exclusive. In practice, an individual's understanding of an algorithm may span multiple levels, and the boundaries between them can be blurred.
Additionally, the experiments conducted in the paper focused on a relatively limited set of algorithms and tasks. Further research is needed to validate the scale across a wider range of algorithmic concepts and problem-solving scenarios, including more complex or domain-specific algorithms.
The paper also acknowledges that the assessment of algorithm understanding, particularly for AI systems, is a challenging and subjective task. Developing reliable and objective evaluation methods remains an important area for future work.
Conclusion
This paper introduces a novel hierarchical scale for quantifying the understanding of algorithms by both humans and AI systems. The scale provides a structured way to assess the depth of algorithmic comprehension, ranging from basic recognition to the ability to design new algorithms.
The findings suggest that while current AI models, such as GPT-3, can perform well on simple algorithmic tasks, they struggle to demonstrate the deeper levels of understanding that humans often exhibit. This highlights the need for continued research and development to create AI systems that can truly comprehend and reason about the algorithms they use, rather than just memorizing and applying them.
By establishing a clear framework for measuring algorithm understanding, this paper lays the groundwork for future studies that can further explore the cognitive capabilities of humans and AI when it comes to working with algorithms, a fundamental component of computational thinking and problem-solving.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Assessing the nature of large language models: A caution against anthropocentrism
Ann Speed
0
0
Generative AI models garnered a large amount of public attention and speculation with the release of OpenAIs chatbot, ChatGPT. At least two opinion camps exist: one excited about possibilities these models offer for fundamental changes to human tasks, and another highly concerned about power these models seem to have. To address these concerns, we assessed several LLMs, primarily GPT 3.5, using standard, normed, and validated cognitive and personality measures. For this seedling project, we developed a battery of tests that allowed us to estimate the boundaries of some of these models capabilities, how stable those capabilities are over a short period of time, and how they compare to humans. Our results indicate that LLMs are unlikely to have developed sentience, although its ability to respond to personality inventories is interesting. GPT3.5 did display large variability in both cognitive and personality measures over repeated observations, which is not expected if it had a human-like personality. Variability notwithstanding, LLMs display what in a human would be considered poor mental health, including low self-esteem, marked dissociation from reality, and in some cases narcissism and psychopathy, despite upbeat and helpful responses.
6/28/2024

GPT-ology, Computational Models, Silicon Sampling: How should we think about LLMs in Cognitive Science?
Desmond C. Ong
0
0
Large Language Models have taken the cognitive science world by storm. It is perhaps timely now to take stock of the various research paradigms that have been used to make scientific inferences about ``cognition in these models or about human cognition. We review several emerging research paradigms -- GPT-ology, LLMs-as-computational-models, and ``silicon sampling -- and review recent papers that have used LLMs under these paradigms. In doing so, we discuss their claims as well as challenges to scientific inference under these various paradigms. We highlight several outstanding issues about LLMs that have to be addressed to push our science forward: closed-source vs open-sourced models; (the lack of visibility of) training data; and reproducibility in LLM research, including forming conventions on new task ``hyperparameters like instructions and prompts.
6/17/2024
🤔
Understanding Understanding: A Pragmatic Framework Motivated by Large Language Models
Kevin Leyton-Brown, Yoav Shoham
0
0
Motivated by the rapid ascent of Large Language Models (LLMs) and debates about the extent to which they possess human-level qualities, we propose a framework for testing whether any agent (be it a machine or a human) understands a subject matter. In Turing-test fashion, the framework is based solely on the agent's performance, and specifically on how well it answers questions. Elements of the framework include circumscribing the set of questions (the scope of understanding), requiring general competence (passing grade), avoiding ridiculous answers, but still allowing wrong and I don't know answers to some questions. Reaching certainty about these conditions requires exhaustive testing of the questions which is impossible for nontrivial scopes, but we show how high confidence can be achieved via random sampling and the application of probabilistic confidence bounds. We also show that accompanying answers with explanations can improve the sample complexity required to achieve acceptable bounds, because an explanation of an answer implies the ability to answer many similar questions. According to our framework, current LLMs cannot be said to understand nontrivial domains, but as the framework provides a practical recipe for testing understanding, it thus also constitutes a tool for building AI agents that do understand.
6/21/2024
🤖
Evaluating and Modeling Social Intelligence: A Comparative Study of Human and AI Capabilities
Junqi Wang, Chunhui Zhang, Jiapeng Li, Yuxi Ma, Lixing Niu, Jiaheng Han, Yujia Peng, Yixin Zhu, Lifeng Fan
0
0
Facing the current debate on whether Large Language Models (LLMs) attain near-human intelligence levels (Mitchell & Krakauer, 2023; Bubeck et al., 2023; Kosinski, 2023; Shiffrin & Mitchell, 2023; Ullman, 2023), the current study introduces a benchmark for evaluating social intelligence, one of the most distinctive aspects of human cognition. We developed a comprehensive theoretical framework for social dynamics and introduced two evaluation tasks: Inverse Reasoning (IR) and Inverse Inverse Planning (IIP). Our approach also encompassed a computational model based on recursive Bayesian inference, adept at elucidating diverse human behavioral patterns. Extensive experiments and detailed analyses revealed that humans surpassed the latest GPT models in overall performance, zero-shot learning, one-shot generalization, and adaptability to multi-modalities. Notably, GPT models demonstrated social intelligence only at the most basic order (order = 0), in stark contrast to human social intelligence (order >= 2). Further examination indicated a propensity of LLMs to rely on pattern recognition for shortcuts, casting doubt on their possession of authentic human-level social intelligence. Our codes, dataset, appendix and human data are released at https://github.com/bigai-ai/Evaluate-n-Model-Social-Intelligence.
5/21/2024