Understanding Understanding: A Pragmatic Framework Motivated by Large Language Models
2406.10937
0
0
🤔
Abstract
Motivated by the rapid ascent of Large Language Models (LLMs) and debates about the extent to which they possess human-level qualities, we propose a framework for testing whether any agent (be it a machine or a human) understands a subject matter. In Turing-test fashion, the framework is based solely on the agent's performance, and specifically on how well it answers questions. Elements of the framework include circumscribing the set of questions (the scope of understanding), requiring general competence (passing grade), avoiding ridiculous answers, but still allowing wrong and I don't know answers to some questions. Reaching certainty about these conditions requires exhaustive testing of the questions which is impossible for nontrivial scopes, but we show how high confidence can be achieved via random sampling and the application of probabilistic confidence bounds. We also show that accompanying answers with explanations can improve the sample complexity required to achieve acceptable bounds, because an explanation of an answer implies the ability to answer many similar questions. According to our framework, current LLMs cannot be said to understand nontrivial domains, but as the framework provides a practical recipe for testing understanding, it thus also constitutes a tool for building AI agents that do understand.
Create account to get full access
Overview
- The paper proposes a pragmatic framework for understanding large language models (LLMs) and their capabilities.
- It explores how LLMs can be used to model and understand the nature of human-level understanding.
- The framework is motivated by the limitations and challenges encountered in current LLM systems.
Plain English Explanation
The paper is about trying to understand how large language models (LLMs) like GPT-3 and others work and what they are capable of. The authors argue that these models, while very impressive in many ways, still have significant limitations when it comes to truly understanding language and meaning the way humans do.
The researchers propose a new framework or way of thinking about "understanding" that is motivated by the shortcomings of current LLMs. They suggest that rather than just focusing on the raw performance of these models on tasks, we need to dig deeper and examine the underlying nature of how they process and comprehend language.
The goal is to develop a more nuanced and pragmatic understanding of what these models can and cannot do, and to use that knowledge to advance the field of artificial intelligence (AI) and bring us closer to human-level understanding. The paper draws inspiration from related work on the philosophical introduction to language models, the challenges LLMs face with uncommon meanings, and the phenomenon of "easy problems that LLMs get wrong".
Technical Explanation
The paper begins by acknowledging the remarkable progress made in LLM capabilities, as evidenced by their strong performance on a wide range of language tasks. However, the authors argue that these models still struggle to truly "understand" language in the way humans do, as demonstrated by cases where they fail at seemingly simple problems.
To address this, the researchers propose a pragmatic framework for understanding understanding, which focuses on three key elements:
- Coherence: The ability to maintain consistent and meaningful connections between different parts of a text or discourse.
- Plausibility: The capacity to judge the reasonableness and appropriateness of language use in a given context.
- Generalization: The power to apply learned knowledge to new, unfamiliar situations.
The paper then explores how these elements of understanding can be modeled and evaluated in the context of LLMs, drawing inspiration from related work on the nature of language model comprehension and the computational basis of meaning.
Critical Analysis
The paper presents a thoughtful and nuanced approach to understanding the capabilities and limitations of LLMs. The proposed framework focuses on key aspects of language understanding that are often overlooked in the pursuit of raw performance metrics.
One potential limitation of the framework is that it may be challenging to operationalize and measure some of the more abstract concepts, such as "plausibility." The authors acknowledge this challenge and suggest that further research is needed to develop robust evaluation methods.
Additionally, the paper does not delve into the potential societal implications of these models and their understanding capabilities. As LLMs become more widely adopted, it will be important to consider how their biases and limitations may impact real-world applications, such as in language generation for content moderation or decision-making support.
Conclusion
The paper offers a valuable contribution to the ongoing discussion around the nature of language understanding in large language models. By proposing a pragmatic framework that goes beyond simple task performance, the authors encourage the AI research community to think more deeply about the core mechanisms and limitations of these powerful systems.
The framework's focus on coherence, plausibility, and generalization provides a promising path forward for developing LLMs that can more closely approximate human-level understanding. As the field of AI continues to evolve, this type of nuanced and reflective approach will be crucial for unlocking the true potential of language models and advancing the state of the art.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
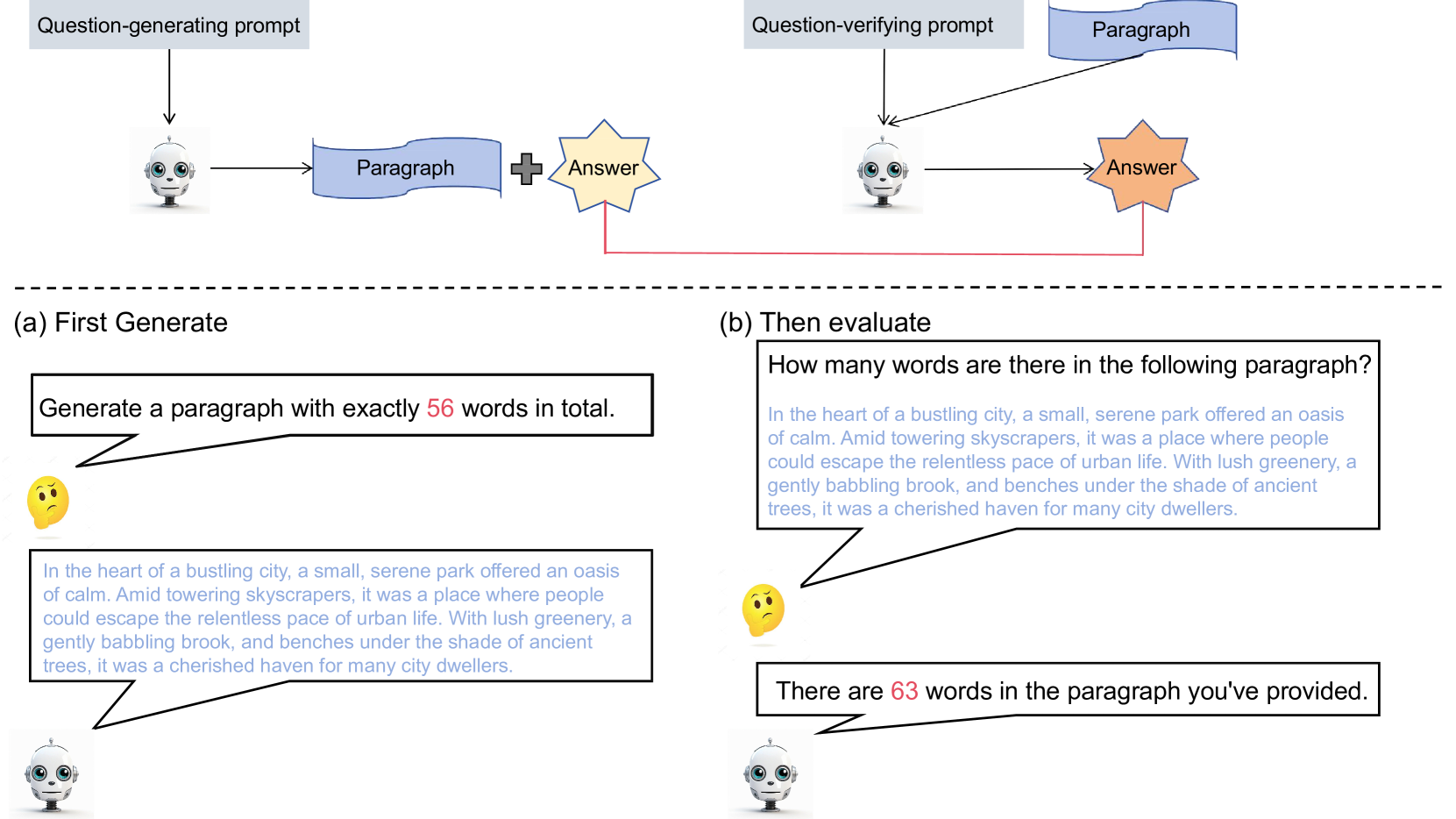
Can I understand what I create? Self-Knowledge Evaluation of Large Language Models
Zhiquan Tan, Lai Wei, Jindong Wang, Xing Xie, Weiran Huang
0
0
Large language models (LLMs) have achieved remarkable progress in linguistic tasks, necessitating robust evaluation frameworks to understand their capabilities and limitations. Inspired by Feynman's principle of understanding through creation, we introduce a self-knowledge evaluation framework that is easy to implement, evaluating models on their ability to comprehend and respond to self-generated questions. Our findings, based on testing multiple models across diverse tasks, reveal significant gaps in the model's self-knowledge ability. Further analysis indicates these gaps may be due to misalignment with human attention mechanisms. Additionally, fine-tuning on self-generated math task may enhance the model's math performance, highlighting the potential of the framework for efficient and insightful model evaluation and may also contribute to the improvement of LLMs.
6/11/2024
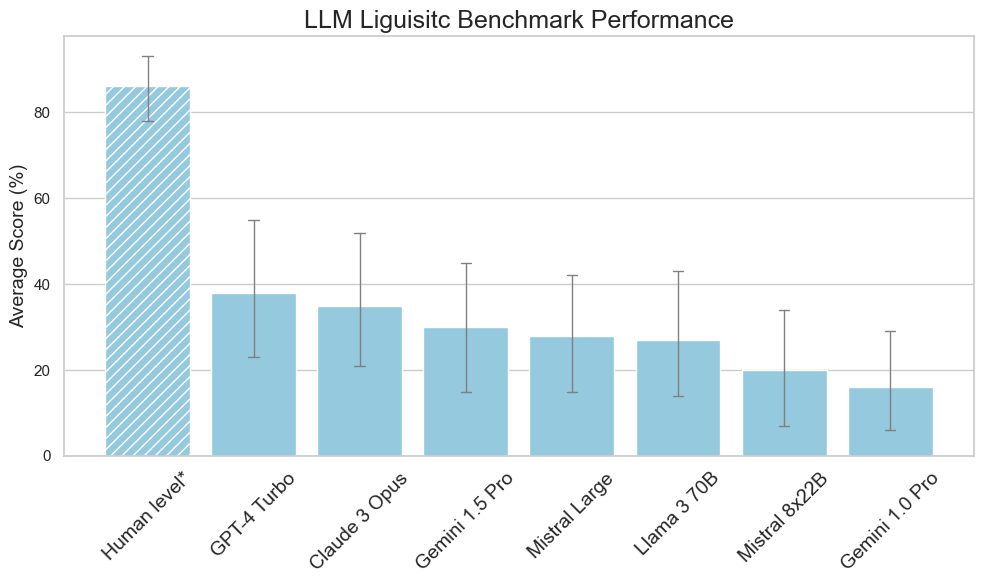
Easy Problems That LLMs Get Wrong
Sean Williams, James Huckle
0
0
We introduce a comprehensive Linguistic Benchmark designed to evaluate the limitations of Large Language Models (LLMs) in domains such as logical reasoning, spatial intelligence, and linguistic understanding, among others. Through a series of straightforward questions, it uncovers the significant limitations of well-regarded models to perform tasks that humans manage with ease. It also highlights the potential of prompt engineering to mitigate some errors and underscores the necessity for better training methodologies. Our findings stress the importance of grounding LLMs with human reasoning and common sense, emphasising the need for human-in-the-loop for enterprise applications. We hope this work paves the way for future research to enhance the usefulness and reliability of new models.
6/4/2024
💬
A Philosophical Introduction to Language Models - Part II: The Way Forward
Raphael Milli`ere, Cameron Buckner
0
0
In this paper, the second of two companion pieces, we explore novel philosophical questions raised by recent progress in large language models (LLMs) that go beyond the classical debates covered in the first part. We focus particularly on issues related to interpretability, examining evidence from causal intervention methods about the nature of LLMs' internal representations and computations. We also discuss the implications of multimodal and modular extensions of LLMs, recent debates about whether such systems may meet minimal criteria for consciousness, and concerns about secrecy and reproducibility in LLM research. Finally, we discuss whether LLM-like systems may be relevant to modeling aspects of human cognition, if their architectural characteristics and learning scenario are adequately constrained.
5/7/2024
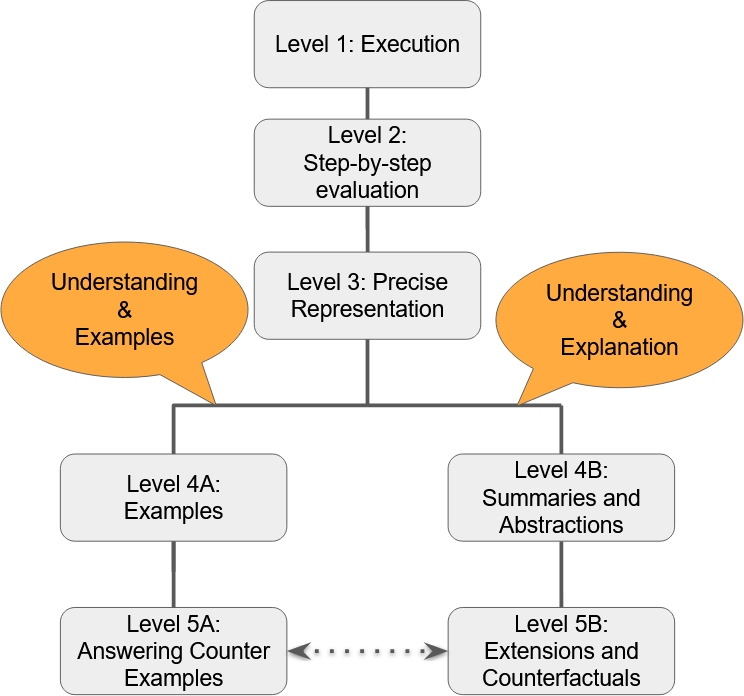
Does GPT Really Get It? A Hierarchical Scale to Quantify Human vs AI's Understanding of Algorithms
Mirabel Reid, Santosh S. Vempala
0
0
As Large Language Models (LLMs) perform (and sometimes excel at) more and more complex cognitive tasks, a natural question is whether AI really understands. The study of understanding in LLMs is in its infancy, and the community has yet to incorporate well-trodden research in philosophy, psychology, and education. We initiate this, specifically focusing on understanding algorithms, and propose a hierarchy of levels of understanding. We use the hierarchy to design and conduct a study with human subjects (undergraduate and graduate students) as well as large language models (generations of GPT), revealing interesting similarities and differences. We expect that our rigorous criteria will be useful to keep track of AI's progress in such cognitive domains.
6/24/2024