GPT-ology, Computational Models, Silicon Sampling: How should we think about LLMs in Cognitive Science?
2406.09464
0
0

Abstract
Large Language Models have taken the cognitive science world by storm. It is perhaps timely now to take stock of the various research paradigms that have been used to make scientific inferences about cognition in these models or about human cognition. We review several emerging research paradigms -- GPT-ology, LLMs-as-computational-models, and silicon sampling -- and review recent papers that have used LLMs under these paradigms. In doing so, we discuss their claims as well as challenges to scientific inference under these various paradigms. We highlight several outstanding issues about LLMs that have to be addressed to push our science forward: closed-source vs open-sourced models; (the lack of visibility of) training data; and reproducibility in LLM research, including forming conventions on new task ``hyperparameters like instructions and prompts.
Create account to get full access
A typology of research paradigms
GPT-ology
This section discusses the various ways researchers are studying large language models (LLMs) like GPT from a cognitive science perspective. Some are treating LLMs as abstract computational models, exploring how their behavior can inform theories of human cognition. Others are looking at LLMs as physical artifacts, analyzing the low-level properties of the underlying silicon and software. And a third group is focused on using LLMs as tools for probing the nature of human language and intelligence. Each of these approaches offers unique insights, but they also come with their own limitations and challenges.
Computational Models
Researchers taking the computational modeling approach are interested in understanding LLMs as abstract information processing systems. They study the mathematical and algorithmic principles that govern how these models learn and reason, with the goal of developing a deeper theoretical understanding of intelligence and language. This work often involves devising new analytical techniques, developing novel architectural variants, and examining the models' systematic strengths and weaknesses on specialized tasks. The hope is that by reverse-engineering the inner workings of LLMs, we can gain fresh insights into the computational principles underlying human cognition.
Silicon Sampling
In contrast, the silicon sampling approach treats LLMs as physical artifacts, examining the low-level properties of the hardware and software that underpins their operation. This might involve things like measuring the energy efficiency of different model architectures, characterizing the noise profiles of neural activations, or probing the distributional properties of the word embeddings. The goal here is to understand how the physical realization of these models shapes their cognitive capabilities and limitations. This work can inform the design of more efficient and robust AI systems, as well as shed light on the role of embodiment in human intelligence.
Leveraging LLMs
The final paradigm is centered on using LLMs as tools for studying human language and cognition. Researchers in this camp are interested in leveraging the impressive capabilities of these models to probe the nature of semantic representation, common sense reasoning, and other hallmarks of human intelligence. This might involve using LLMs as annotators or evaluators to shed light on how humans understand and use language, or exploring the limits of what LLMs can learn and represent. The goal is to leverage the unique capabilities of these models to advance our fundamental understanding of cognition.
Technical Explanation
The paper presents a taxonomy of three distinct research paradigms that are emerging in the study of large language models (LLMs) from a cognitive science perspective.
The first paradigm, "GPT-ology," treats LLMs as abstract computational models, exploring how their behavior can inform theories of human cognition. Researchers in this camp are interested in understanding the mathematical and algorithmic principles that govern how these models learn and reason, with the goal of developing a deeper theoretical understanding of intelligence and language.
The second paradigm, "Silicon Sampling," examines LLMs as physical artifacts, focusing on the low-level properties of the hardware and software that underpins their operation. This work aims to understand how the physical realization of these models shapes their cognitive capabilities and limitations, which can inform the design of more efficient and robust AI systems.
The third paradigm, "Leveraging LLMs," uses these powerful language models as tools for studying human language and cognition more broadly. Researchers in this camp are interested in using LLMs as annotators, evaluators, or probes to shed light on semantic representation, common sense reasoning, and other hallmarks of human intelligence.
The paper argues that while each of these paradigms offers unique insights, they also come with their own limitations and challenges. By considering the diverse ways researchers are approaching the study of LLMs, the authors hope to encourage a more nuanced and holistic understanding of these models and their implications for cognitive science.
Critical Analysis
The paper provides a useful taxonomy for understanding the different ways researchers are studying large language models from a cognitive science perspective. However, it also acknowledges that each of these paradigms has its own limitations and challenges.
One potential limitation of the "GPT-ology" approach is that it may oversimplify the complex relationship between LLMs and human cognition. While studying the computational principles underlying these models can certainly inform our theories of intelligence, it's important to recognize that human cognition is shaped by a wide range of biological, social, and environmental factors that may not be fully captured by abstract models.
Similarly, the "Silicon Sampling" approach, while valuable for understanding the physical constraints and affordances of LLMs, may struggle to account for the higher-level cognitive phenomena that emerge from the complex interplay between hardware, software, and the external world.
The "Leveraging LLMs" paradigm also faces its own challenges, such as the potential biases and limitations of using these models as proxies for human language and reasoning. It's important to carefully consider the extent to which LLMs can accurately reflect the nuances of human cognition, and to be mindful of the potential pitfalls of over-relying on these models as research tools.
Ultimately, the paper argues that a multifaceted approach, drawing on the insights of all three paradigms, is likely to be the most fruitful way forward in understanding the relationship between large language models and human cognition. By acknowledging the strengths and limitations of each approach, researchers can work towards a more holistic and nuanced understanding of these powerful AI systems and their implications for the study of intelligence.
Conclusion
The paper presents a typology of three distinct research paradigms that are emerging in the study of large language models (LLMs) from a cognitive science perspective.
The "GPT-ology" approach treats LLMs as abstract computational models, exploring how their behavior can inform theories of human cognition. The "Silicon Sampling" paradigm examines LLMs as physical artifacts, focusing on the low-level properties of the hardware and software that underpins their operation. And the "Leveraging LLMs" approach uses these powerful language models as tools for studying human language and cognition more broadly.
While each of these paradigms offers unique insights, the paper acknowledges that they also come with their own limitations and challenges. By considering the diverse ways researchers are approaching the study of LLMs, the authors hope to encourage a more nuanced and holistic understanding of these models and their implications for the field of cognitive science.
Ultimately, the paper suggests that a multifaceted approach, drawing on the strengths of all three paradigms, is likely to be the most fruitful way forward in understanding the relationship between large language models and human intelligence. This will involve carefully considering the potential biases and limitations of these models, as well as their affordances and the computational principles that govern their behavior.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
A Philosophical Introduction to Language Models - Part II: The Way Forward
Raphael Milli`ere, Cameron Buckner
0
0
In this paper, the second of two companion pieces, we explore novel philosophical questions raised by recent progress in large language models (LLMs) that go beyond the classical debates covered in the first part. We focus particularly on issues related to interpretability, examining evidence from causal intervention methods about the nature of LLMs' internal representations and computations. We also discuss the implications of multimodal and modular extensions of LLMs, recent debates about whether such systems may meet minimal criteria for consciousness, and concerns about secrecy and reproducibility in LLM research. Finally, we discuss whether LLM-like systems may be relevant to modeling aspects of human cognition, if their architectural characteristics and learning scenario are adequately constrained.
5/7/2024
💬
Assessing the nature of large language models: A caution against anthropocentrism
Ann Speed
0
0
Generative AI models garnered a large amount of public attention and speculation with the release of OpenAIs chatbot, ChatGPT. At least two opinion camps exist: one excited about possibilities these models offer for fundamental changes to human tasks, and another highly concerned about power these models seem to have. To address these concerns, we assessed several LLMs, primarily GPT 3.5, using standard, normed, and validated cognitive and personality measures. For this seedling project, we developed a battery of tests that allowed us to estimate the boundaries of some of these models capabilities, how stable those capabilities are over a short period of time, and how they compare to humans. Our results indicate that LLMs are unlikely to have developed sentience, although its ability to respond to personality inventories is interesting. GPT3.5 did display large variability in both cognitive and personality measures over repeated observations, which is not expected if it had a human-like personality. Variability notwithstanding, LLMs display what in a human would be considered poor mental health, including low self-esteem, marked dissociation from reality, and in some cases narcissism and psychopathy, despite upbeat and helpful responses.
6/28/2024

Large Knowledge Model: Perspectives and Challenges
Huajun Chen
0
0
Humankind's understanding of the world is fundamentally linked to our perception and cognition, with emph{human languages} serving as one of the major carriers of emph{world knowledge}. In this vein, emph{Large Language Models} (LLMs) like ChatGPT epitomize the pre-training of extensive, sequence-based world knowledge into neural networks, facilitating the processing and manipulation of this knowledge in a parametric space. This article explores large models through the lens of knowledge. We initially investigate the role of symbolic knowledge such as Knowledge Graphs (KGs) in enhancing LLMs, covering aspects like knowledge-augmented language model, structure-inducing pre-training, knowledgeable prompts, structured CoT, knowledge editing, semantic tools for LLM and knowledgeable AI agents. Subsequently, we examine how LLMs can boost traditional symbolic knowledge bases, encompassing aspects like using LLM as KG builder and controller, structured knowledge pretraining, and LLM-enhanced symbolic reasoning. Considering the intricate nature of human knowledge, we advocate for the creation of emph{Large Knowledge Models} (LKM), specifically engineered to manage diversified spectrum of knowledge structures. This promising undertaking would entail several key challenges, such as disentangling knowledge base from language models, cognitive alignment with human knowledge, integration of perception and cognition, and building large commonsense models for interacting with physical world, among others. We finally propose a five-A principle to distinguish the concept of LKM.
6/27/2024
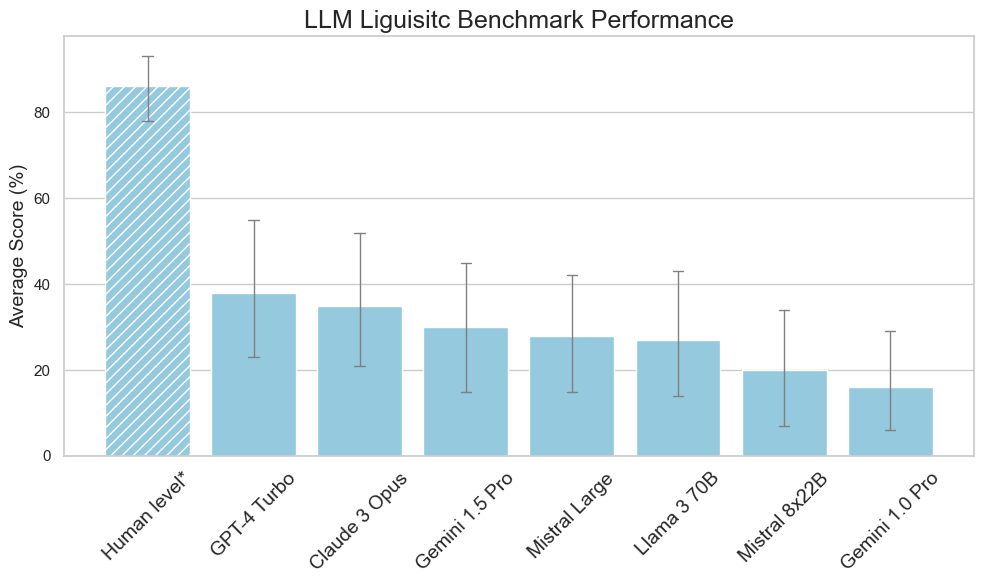
Easy Problems That LLMs Get Wrong
Sean Williams, James Huckle
0
0
We introduce a comprehensive Linguistic Benchmark designed to evaluate the limitations of Large Language Models (LLMs) in domains such as logical reasoning, spatial intelligence, and linguistic understanding, among others. Through a series of straightforward questions, it uncovers the significant limitations of well-regarded models to perform tasks that humans manage with ease. It also highlights the potential of prompt engineering to mitigate some errors and underscores the necessity for better training methodologies. Our findings stress the importance of grounding LLMs with human reasoning and common sense, emphasising the need for human-in-the-loop for enterprise applications. We hope this work paves the way for future research to enhance the usefulness and reliability of new models.
6/4/2024